如果你也在 怎样代写统计Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计Statistics是数学的一个分支,涉及到矢量空间和线性映射。它包括对线、面和子空间的研究,也涉及所有向量空间的一般属性。
统计学Statistics是一门关于发展和研究收集、分析、解释和展示经验数据的方法的科学。统计Statistics是一个高度跨学科的领域;统计Statistics的研究几乎适用于所有的科学领域,各科学领域的研究问题促使新的统计方法和理论的发展。在开发方法和研究支撑这些方法的理论时,统计学家利用了各种数学和计算工具。
统计Statistics领域的两个基本概念是不确定性和突变。我们在科学(或更广泛的生活)中遇到的许多情况,其结果是不确定的。在某些情况下,不确定性是因为有关的结果尚未确定(例如,我们可能不知道明天是否会下雨),而在其他情况下,不确定性是因为虽然结果已经确定,但我们并不知道(例如,我们可能不知道我们是否通过了某项考试)。
my-assignmentexpert™ 统计Statistics作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计Statistics作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在统计Statistics代写方面经验极为丰富,各种统计Statistics相关的作业也就用不着 说。
我们提供的统计Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Date Analysis数据分析
- Actuarial Science 精算科学
- Bayesian Statistics 贝叶斯统计
- Generalized Linear Model 广义线性模型
- Macroeconomic statistics 宏观统计学
- Microeconomic statistics 微观统计学
- Logistic regression 逻辑回归
- linear regression 线性回归
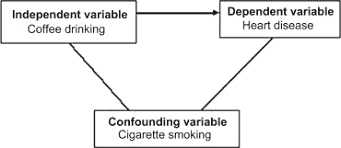
Let’s examine one other issue at this juncture about multiple LRMs. This returns to a point made in Chapter 4 about the need to assess confounding variables. As mentioned there, a confounding variable accounts for the association between an explanatory and an outcome variable (recall the lighter purchases and lung disease example).
To be a bit more precise: a variable is considered a confounder if it meets the following criteria. First, the variable is associated with the explanatory variable. Second, it is associated with the outcome variable independent of the explanatory variable. Third, it is not part of a causal pathway from the explanatory variable to the outcome variable. Returning to the example in Chapter 4 , suppose we find that sales of lighters are associated with lung cancer rates. Cigarette smoking serves as a confounder if: (a) it is associated with sales of lighters (highly likely); (b) it is associated with lung cancer rates independent of lighter sales (a valid conjecture); and (c) it does not play a role in the causal association between cigarette smoking and cancer rates. The latter claim is also valid since buying more lighters is not likely to directlydoubt on causal connections between variables: the frequency of lighter purchases does not cause lung cancer rates because cigarette smoking confounds their association ${ }^{14}$
We’ll discuss confounding a bit more in Chapter 12 , but for now consider the two LRMs designed to predict the number of opioid deaths per 100,000 . Looking back at the coefficients from the two models, in the nested model, average life satisfaction has a partial slope of $-2.40$, whereas in the full model it has a partial slope of $-2.01$ The partial slope thus decreased by about $16 \%$ when we included the additional variables in the model. We cannot tell at this point whether the decrease is practically or statistically significant (although tools are available for the latter issue), but let’s assume it is. We may then tentatively claim that one or both of the new explanatory variables included in the model confounded the association between the average life satisfaction and opioid deaths. They did not confound it completely-the slope would be much closer to zero if this was the case (or it would decrease enough that we’d judge it to be non-essential)-but changed it enough to draw our attention. We usually look for variables that completely account for the association between two variables, but even those that only partially account for it can be interesting. The key question you should always ask yourself, though, is why. Why does the association change when we add a new variable? It could be a random fluctuation in the data, but it might be something important and worthy of further exploration. In this example, perhaps life satisfaction and one of the other explanatory variables, such as the unemployment rate, are associated in an intriguing way. You might ask whether the unemployment rate is associated with average life satisfaction and opioid deaths in a causal fashion or is it simply a confounder? ${ }^{15}$
在这个关键时刻,让我们研究另一个关于多个 LRM 的问题。这又回到了第 4 章中关于评估混杂变量的必要性的观点。正如那里提到的,一个混淆变量解释了解释变量和结果变量之间的关联(回想一下较轻的购买和肺部疾病的例子)。
更准确地说:如果一个变量满足以下标准,它就被认为是一个混杂因素。首先,变量与解释变量相关联。其次,它与独立于解释变量的结果变量相关联。第三,它不是从解释变量到结果变量的因果路径的一部分。回到第 4 章的例子,假设我们发现打火机的销售与肺癌发病率相关。在以下情况下,吸烟会成为一种混杂因素: (a) 它与打火机的销售有关(很可能);(b) 它与肺癌发病率相关,与较轻的销售无关(一个有效的猜想);(c) 它在吸烟与癌症发病率之间的因果关系中没有作用。14
我们将在第 12 章中进一步讨论混淆,但现在考虑用于预测每 100,000 人中阿片类药物死亡人数的两种 LRM。回顾两个模型的系数,在嵌套模型中,平均生活满意度有一个偏斜率−2.40,而在完整模型中,它的部分斜率为−2.01部分斜率因此减少了大约16%当我们在模型中包含其他变量时。在这一点上,我们无法判断这种减少是实际显着还是统计显着(尽管有工具可用于后一个问题),但让我们假设它是。然后,我们可以暂时声称模型中包含的一个或两个新解释变量混淆了平均生活满意度与阿片类药物死亡之间的关联。他们并没有完全混淆它——如果是这种情况,斜率会更接近于零(或者它会减小到足以让我们判断它是非必要的)——但改变它足以引起我们的注意。我们通常会寻找完全解释两个变量之间关联的变量,但即使是那些仅部分解释它的变量也可能很有趣。但是,您应该始终问自己的关键问题是为什么。为什么当我们添加一个新变量时关联会发生变化?这可能是数据的随机波动,但它可能是重要的,值得进一步探索。在这个例子中,也许生活满意度和其他解释变量之一(例如失业率)以一种有趣的方式相关联。您可能会问,失业率是否与平均生活满意度和阿片类药物死亡之间存在因果关系,还是仅仅是一个混杂因素?15

统计作业代写Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
matlab代写
MATLAB是一个编程和数值计算平台,被数百万工程师和科学家用来分析数据、开发算法和创建模型。
MATLAB is a programming and numeric computing platform used by millions of engineers and scientists to analyze data, develop algorithms, and create models.
统计代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
统计作业代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
my-assignmentexpert™这边统计代写的质量怎么样?保不保分?靠不靠谱? 一般能写到多少分?
各国各学校的学术标准都有所差异,即使是统计作业,给分也存在一定的主观性因素,有时Teacher和TA的改分并不能够做到完全公正,所有的作业分数都存在一定的运气成分,TA对于步骤把控的严格程度可能和给分的TA今天的心情以及他的性格正相关。一般情况下,MY-ASSIGNMENTEXPERT™出品的作业平均正确率在93%以上。
我在MY-ASSIGNMENTEXPERT™这里购买了代写服务,然后最后这门课的成绩挂了怎么办?
若是因为各种因素结合导致在此购买的统计作业的成绩未达到事先指定的标准,MY-ASSIGNMENTEXPERT™承诺免费重写/修改,并且无条件退款。
最快什么时候写完? 很急的任务可以做吗?
最急的统计论文,可在24小时以内完成,加急的论文价格会比普通的订单稍贵,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计quiz和统计exam代考,在写手档期ok的情况下,可以在下单之后一小时之内进行,不过不提倡这样临时找人,因为加急的quiz和exam代考价格会比普通的订单贵更重要的是可能找不到人,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计assignment,在写手档期ok的情况下,可以在下单之后三小时之内完成,价格在一般的assignment基础上收一个加急费用,如果一份assignment发下来不确定自己能不能完成也能提前和我们联系,报价是不收取任何费用的,如果后续有需要,也方便我们安排写手档期。