如果你也在 怎样代写广义线性模型Generalized linear model这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。广义线性模型Generalized linear model在统计学中,是普通线性回归的灵活概括。广义线性模型通过允许线性模型通过一个链接函数与响应变量相关,并允许每个测量值的方差大小是其预测值的函数,从而概括了线性回归。
广义线性模型Generalized linear model是由John Nelder和Robert Wedderburn提出的,作为统一其他各种统计模型的一种方式,包括线性回归、逻辑回归和泊松回归。 他们提出了一种迭代加权的最小二乘法,用于模型参数的最大似然估计。最大似然估计仍然很流行,是许多统计计算软件包的默认方法。其他方法,包括贝叶斯方法和最小二乘法对方差稳定反应的拟合,已经被开发出来。
my-assignmentexpert™广义线性模型Generalized linear model作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的广义线性模型Generalized linear model作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此广义线性模型Generalized linear model作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在广义线性模型Generalized linear model代写方面经验极为丰富,各种广义线性模型Generalized linear model相关的作业也就用不着 说。
我们提供的广义线性模型Generalized linear model及其相关学科的代写,服务范围广, 其中包括但不限于:
统计代写|Generalized linear model代考广义线性模型代写|Model definition and examples
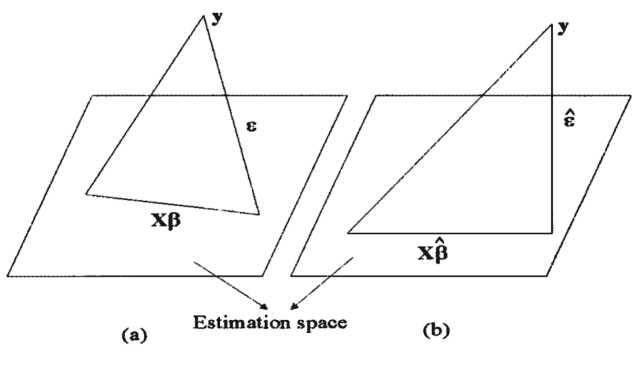
Given data $\left(Y_{i}, X_{i 1}, X_{i 2}, \cdots, X_{i k}\right), i=1, \cdots, N$, the general linear model has the form
$$
\mathbf{y}=\mathbf{X} \beta+\varepsilon
$$
where $\mathbf{y}=\left(Y_{1}, \cdots, Y_{N}\right)^{\prime}$ is an $N$-dimensional vector of observed responses, $\beta=$ $\left(\beta_{0}, \beta_{1}, \cdots, \beta_{k}\right)^{\prime}$ is a $(k+1)$-dimensional vector of unknown parameters, $\mathbf{X}$ is an $N \times(k+1)$ matrix of rank $r$ of known predictors, and $\varepsilon=\left(\varepsilon_{1}, \cdots, \varepsilon_{N}\right)^{\prime}$ is an $N$-dimensional random vector of unobserved errors. The matrix $\mathbf{X}$ is written as
$$
\mathbf{X}=\left(\begin{array}{cccc}
1 & X_{11} & \cdots & X_{1 k} \
1 & X_{21} & \cdots & X_{2 k} \
\vdots & \vdots & \vdots & \vdots \
1 & X_{N 1} & \cdots & X_{N k}
\end{array}\right)
$$
统计代写|Generalized linear model代考广义线性模型代写|The least squares approach
Given data on the response variable and predictors, either from an observational study or from a designed experiment, the objective is inference on the model parameters, or functions of the model parameters, as well as predictions for the response variable based on the general linear model (4.1.1). The method of least squares, which was introduced in the early 19 th century, enables such inference using minimal assumptions. In particular, we need not specify any parametric form for the probability distribution of the errors $\varepsilon_{i}$. In the full rank linear model, i.e., when $r(\mathbf{X})=p$, the least squares approach enables us to construct the best linear unbiased estimator of the parameter vector $\beta$, “best” in the sense of having minimum variance in the class of all linear unbiased estimators. When $r(\mathbf{X})=r<p$, we will obtain least squares estimates of certain linear functions of $\beta$, although, as we shall see, there does not exist a unique estimator for $\beta$ itself. In order to proceed with inference beyond point estimation and prediction for the linear model, i.e., in order to construct confidence interval estimates or to do hypothesis tests, it is usual to assume some parametric form for the error distribution. The simplest and most popular distributional assumption is the assumption of normality of the linear model errors. In Chapter 5 , we introduce suitable families of multivariate probability distributions, including the multivariate normal distribution, and return to classical inference for linear models in Chapter 7 . We now describe the least squares principle.
统计代写|GENERALIZED LINEAR MODEL代考广义线性模型代写|Estimable functions
In the previous section, we saw that unless $r(\mathbf{X})=p, \beta^{0}$ is not unique. Although in the full rank model, we can estimate any function of $\beta$, we must restrict our-selves to estimating only certain linear functions of $\beta$ when $r(\mathbf{X})<p$. Such a linear function of $\beta$ is called an estimable function. In other words, a linear function of $\beta$ for which a (unique) estimator based on $\beta^{0}$ exists, which is invariant to the solution $\beta^{0}$, is called an estimable function. A more precise definition, which also provides an approach for the identification of an estimable function of $\beta$, is given below.
A linear parametric function $\mathbf{c}^{\prime} \beta$ is said to be an estimable function of $\beta$ if there exists an $N$-dimensional vector $\mathbf{t}=\left(t_{1}, \cdots, t_{N}\right)^{\prime}$ such that the expectation (with respect to the distribution of $\mathbf{y}$ ) of the linear combination $\mathbf{t}^{\prime} \mathbf{y}=t_{1} Y_{1}+\cdots+t_{N} Y_{N}$ is equal to $\mathbf{c}^{\prime} \beta$, i.e.,
$$
E\left(\mathbf{t}^{\prime} \mathbf{y}\right)=\mathbf{c}^{\prime} \beta
$$
广义线性模型代写
统计代写|GENERALIZED LINEAR MODEL代考广义线性模型代写|MODEL DEFINITION AND EXAMPLES
给定数据(是一世,X一世1,X一世2,⋯,X一世ķ),一世=1,⋯,ñ,一般线性模型具有形式
是=Xb+e
在哪里是=(是1,⋯,是ñ)′是一个ñ观察到的反应的维向量,b= (b0,b1,⋯,bķ)′是一个(ķ+1)-未知参数的维向量,X是一个ñ×(ķ+1)秩矩阵r已知的预测变量,和e=(e1,⋯,eñ)′是一个ñ未观察到的误差的维随机向量。矩阵X写成
$$
\mathbf{X}=\left(\begin{array}{cccc}
1 & X_{11} & \cdots & X_{1 k} \
1 & X_{21} & \cdots & X_{2 k} \
\vdots & \vdots & \vdots & \vdots \
1 & X_{N 1} & \cdots & X_{N k}
\end{array}\right)
$$
统计代写|GENERALIZED LINEAR MODEL代考广义线性模型代写|THE LEAST SQUARES APPROACH
给定来自观察研究或设计实验的响应变量和预测变量数据,目标是推断模型参数或模型参数的函数,以及基于一般线性模型的响应变量预测4.1.1. 19 世纪初引入的最小二乘法可以使用最小假设进行此类推断。特别是,我们不需要为错误的概率分布指定任何参数形式e一世. 在满秩线性模型中,即当r(X)=p,最小二乘法使我们能够构造参数向量的最佳线性无偏估计量b,“最佳”是指在所有线性无偏估计量中具有最小方差。什么时候r(X)=r<p,我们将获得某些线性函数的最小二乘估计b,尽管正如我们将看到的,不存在唯一的估计量b本身。为了在线性模型的点估计和预测之外进行推理,即,为了构建置信区间估计或进行假设检验,通常对误差分布采取某种参数形式。最简单和最流行的分布假设是线性模型误差的正态性假设。在第 5 章中,我们介绍了合适的多元概率分布族,包括多元正态分布,并在第 7 章回到线性模型的经典推理。我们现在描述最小二乘原理。
统计代写|GENERALIZED LINEAR MODEL代考广义线性模型代写|ESTIMABLE FUNCTIONS
在上一节中,我们看到除非r(X)=p,b0不是唯一的。尽管在满秩模型中,我们可以估计b,我们必须限制自己只估计某些线性函数b什么时候r(X)<p. 这样的线性函数b称为可估计函数。换句话说,一个线性函数b为此在n一世q在和估计器基于b0存在,对解是不变的b0,称为可估计函数。一个更精确的定义,它也提供了一种识别可估计函数的方法b, 下面给出。
线性参数函数C′b据说是一个可估计函数b如果存在一个ñ维向量吨=(吨1,⋯,吨ñ)′这样期望在一世吨Hr和sp和C吨吨这吨H和d一世s吨r一世b在吨一世这n这F$是$线性组合的吨′是=吨1是1+⋯+吨ñ是ñ等于C′b, IE,

统计代写|Generalized linear model代考广义线性模型代写 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。