如果你也在 怎样代写复杂网络Complex Network CS-E5740这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。复杂网络Complex Network在网络理论的背景下,复杂网络是指具有非微观拓扑特征的图(网络)–这些特征在简单的网络(如格子或随机图)中不会出现,但在代表真实系统的网络中经常出现。复杂网络的研究是一个年轻而活跃的科学研究领域(自2000年以来),主要受到现实世界网络的经验发现的启发,如计算机网络、生物网络、技术网络、大脑网络、气候网络和社会网络。
复杂网络Complex Network大多数社会、生物和技术网络显示出实质性的非微观拓扑特征,其元素之间的连接模式既不是纯粹的规则也不是纯粹的随机。这些特征包括学位分布的重尾、高聚类系数、顶点之间的同态性或异态性、社区结构和层次结构。在有向网络的情况下,这些特征还包括互惠性、三联体重要性概况和其他特征。相比之下,过去研究的许多网络的数学模型,如格子和随机图,并没有显示这些特征。最复杂的结构可以由具有中等数量相互作用的网络实现。这与中等概率获得最大信息含量(熵)的事实相对应。
复杂网络Complex Network代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。最高质量的复杂网络Complex Network作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此复杂网络Complex Network作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
。
数据科学代写|复杂网络代写Complex Network代考|Generating maximally random networks
For simulations, generation of a full statistical ensemble, as in the configuration model is often infeasable. How can we construct an equilibrium network in practice if we want it to satisfy a set of structural constraints? In addition to the degree sequence as in the configuration model, we can, for instance, forbid self-loops and multiple connections. ${ }^9$ The idea is, as in physics, to start with a graph satisfying these constraints and relax it to an ‘equilibrium’ by performing a chain of random steps such that all the constraints are fulfilled at each step. Maslov, Sneppen, and Alon (2003) proposed this kind of practical randomization algorithm just for random networks with a fixed degree sequence and without multiple edges and self-loops. Suppose we want to generate a uniformly random network of this sort consisting of a single connected component. To do this, we must perform the following steps:
(i) Create an arbitrary connected graph, with a given degree sequence, and without multiple connections and self-loops.
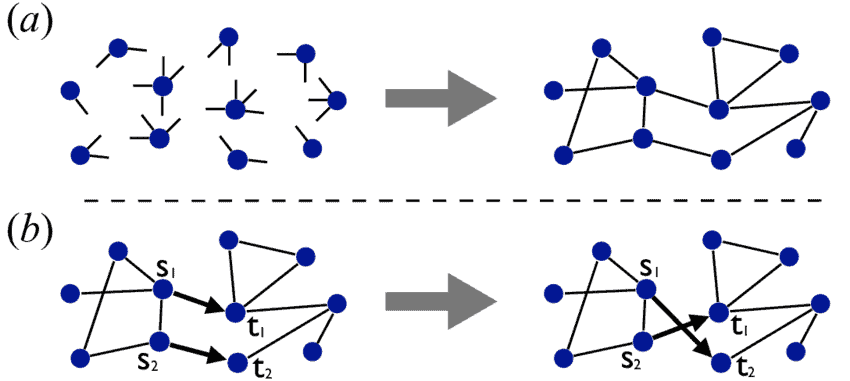
(ii) Rewire a pair of uniformly randomly chosen edges in a way shown in Figure 4.3. This retains the degrees of all vertices and does not create multiple edges. Check whether this rewiring splits the network into two parts or not. If it splits, then abandon this rewiring and repeat the step.
(iii) Repeat (ii) until the network relaxes to an equilibrium state.
The slowest part of this algorithm is checking the connectedness of the networks. If we do not need our network to be connected, then this algorithm is very fast.
数据科学代写|复杂网络代写Complex Network代考|Hidden variables
After the configuration model using a microcanonical statistical ensemble, the second way to construct a network with a desired degree distribution was found in 2001-2002. This grand canonical ensemble construction (Goh, Kahng, and Kim, 2001; Chung and Lu, 2002; Caldarelli, Capocci, De Los Rios, and Munoz, 2002; Söderberg, 2002), generalizes the $G(N, p)$ model, and it is essentially based on the notion of hidden variables. The idea is to ascribe non-negative real numbers $f_i$ (hidden variables) to the vertices, $i=1,2, \ldots, N$ and to interconnect each pair of vertices, $i$ and $j$, with a probability $p_{i j}\left(f_i, f_j\right)$ depending on the hidden variables of these two vertices. In different versions of the model, the hidden variables $f_i$ may be a given sequence of numbers, or they may be drawn from some probability distribution $P_h(f)$. As the result, we get a grand canonical ensemble of simple graphs. In particular, when $f_i=c>0, i=1,2, \ldots, N$, we arrive at the standard $G(N, p)$ random graph. Various versions of this model are called the static model (Goh, Kahng, and Kim, 2001), ${ }^{10}$ the Chung-Lu model after Chung and Lu (2002), or, more generally, random networks with hidden variables.
First, without specifying the form of $p_{i j}\left(f_i, f_j\right)$, let us look at the probability of realization of a member of this ensemble – a simple graph described by an $N \times N$ adjacency matrix $A$, namely
$$
\mathcal{P}(A)=\prod_{i<j}\left[p_{i j} A_{i j}+\left(1-p_{i j}\right)\left(1-A_{i j}\right)\right] .
$$
Using this probability, we can get all observables for this random network in terms of the probabilities $p_{i j}$. For example, in the same way as for the $G(N, p)$ model, Eq. (3.10), one can obtain the entropy
$$
S=-\sum_{i<j}\left[p_{i j} \ln p_{i j}+\left(1-p_{i j}\right) \ln \left(1-p_{i j}\right)\right],
$$
derive an expression for the degree distribution (Lee, Kahng, Cho, Goh, and Lee, 2018), which we do not show here. Of these observables, here we need the average degree of vertex $i$ in this ensemble, which can be easily written:
$$
\langle q\rangle_i=\sum_j p_{i j}
$$
复杂网络代写
数据科学代写|复杂网络代写COMPLEX NETWORK代 考|GENERATING MAXIMALLY RANDOM NETWORKS
对于模拟,生成完整的统计集成,如在配置模型中通常是不可行的。如果我们希望它满足一组结构约束,我们如何在实践中构建一个均衡网络? 除了配置模型中的 度数序列外,我们还可以例如禁止自循环和多连接。 ${ }^9$ 就像在物理学中一样,这个想法是从满足这些约束的图开始,然后通过执行一系列随机步骤将其放松到“平 衡”,以便在每一步都满足所有约束。马斯洛夫、斯内彭和阿隆2003提出了这种实用的随机化算法,仅适用于具有固定度数序列且没有多重边和自环的随机网络。 假设我们想要生成一个由单个连接组件组成的此类均匀随机网络。为此,我们必须执行以下步骤:
$i$ 创建具有给定度数序列且没有多个连接和自环的任意连通图。
ii以图 4.3 所示的方式重新连接一对均匀随机选择的边。这会保留所有顶点的度数,并且不会创建多个边。检自此重新布线是否将网络分成两部分。如果它分裂,
则放弃此重新布线并重复该步骤。
$i i$ 重荁 $i$ 直到网絡松弛到平衡状态。
该算法最慢的部分是检亱网絡的连通性。如果我们不需要连接我们的网络,那么这个算法非常快。
数据科学代写|复杂网络代写COMPLEX NETWORK代 考|HIDDEN VARIABLES
在使用微规范统计集成的配置模型之后,在 2001-2002 年发现了第二种构建具有所需度分布的网絡的方法。这个宏伟的规范合秦结构
Goh, Kahng, andKim, 2001; ChungandLu, 2002; Caldarelli, Capocci, DeLosRios, andMunoz, 2002; Söderberg, 2002, 概括G (N, p)模型,它本质上是 其于隐藏变量的概念。这个想法是赋予非负实数 $f_i$ hiddenvariables 到顶点, $i=1,2, \ldots, N$ 并互连每对顶点,i和 $j$, 有概率 $p_{i j}\left(f_i, f_j\right)$ 取决于这两个顶点的隐藏 变量。在不同版本的模型中,隐藏变量 $f_i$ 可能是给定的数字序列,也可能是从某个概率分布中得出的 $P_h(f)$. 结果,我们得到了一个简单图的大规范集合。特别是, 当 $f_i=c>0, i=1,2, \ldots, N$ ,我们达到标准 $G(N, p)$ 随机图。该模型的各种版本称为静态模型 $G o h, K a h n g, a n d K i m, 2001$, 10 仲鲁之后的仲鲁模式 2002 ,或 者更一般地说,具有隐藏变量的随机网络。
首先,不指定形式 $p_{i j}\left(f_i, f_j\right)$ ,让我们看看实现这个集合的一个成员的概率一一一个由一个简单的图描述的 $N \times N$ 邻接矩阵 $A$ ,即
$$
\mathcal{P}(A)=\prod_{i<j}\left[p_{i j} A_{i j}+\left(1-p_{i j}\right)\left(1-A_{i j}\right)\right] .
$$
使用这个概率,我们可以根据概率获得这个随机网络的所有可观察值 $p_{i j}$. 例如,以与 $G(N, p)$ 模型,方程式。 $3.10$, 可以得到熵
$$
S=-\sum_{i<j}\left[p_{i j} \ln p_{i j}+\left(1-p_{i j}\right) \ln \left(1-p_{i j}\right)\right],
$$
导出度分布的表达式Lee, Kahng, Cho, Goh, andLee, 2018,我们在这里没有展示。在这些 observables 中,这里我们需要顶点的平均度数 $i$ 在这个合秦中,可以 很容易地写成:
$$
\langle q\rangle_i=\sum_j p_{i j}
$$

数据科学代写|复杂网络代写Complex Network代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。