如果你也在 怎样代写r语言r project这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。r语言r projectR是一种用于统计计算和图形的编程语言,由R核心团队和R统计计算基金会支持。R由统计学家Ross Ihaka和Robert Gentleman创建,在数据挖掘者和统计学家中被用于数据分析和开发统计软件。用户已经创建了软件包来增强R语言的功能。根据用户调查和对学术文献数据库的研究,R是数据挖掘中最常用的编程语言之一。截至2022年3月,R在衡量编程语言普及程度的TIOBE指数中排名第11位。
r语言r project官方的R软件环境是GNU软件包中的一个开源自由软件环境,在GNU通用公共许可证下提供。它主要是用C、Fortran和R本身(部分自我托管)编写的。预编译的可执行文件提供给各种操作系统。R有一个命令行界面。也有多个第三方图形用户界面,如RStudio,一个集成开发环境,和Jupyter,一个笔记本界面。
my-assignmentexpert™r语言r projects作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的r语言r project作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此r语言r project作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在r语言r project代写方面经验极为丰富,各种r语言r project相关的作业也就用不着 说。
我们提供的r语言r project及其相关学科的代写,服务范围广, 其中包括但不限于:
统计代写|r语言代考r project代写|Conceptual Preparation: How to Understand Regression Analysis
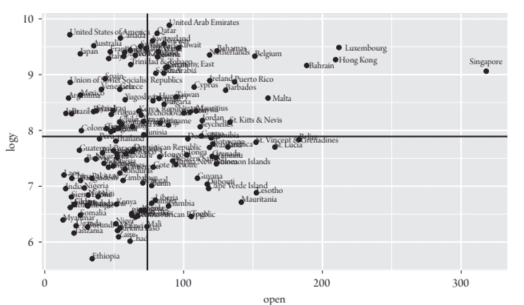
Does trade promote economic growth? According to many economists, trade openness promotes growth in the long run because international commerce increases market competition, re-allocates domestic resources to more efficient use, encourages technologies to spread, and expands the market size. Statistical evidence of the relationship between trade openness and growth, however, has been rather mixed and open to various methodological criticisms. In this section, we will provide a simple example from the trade-growth studies to illustrate how we use $R$ and cross-sectional regression analysis to evaluate the effect of trade on economic growth.
Our example draws on a highly influential paper that has a Google Scholar citation count of over 5,000 :
Frankel, Jeffrey A., and David Romer. 1999. “Does trade cause growth?” American Economic Review 89(3): 379-99.
Using this example, we aim to illustrate the following issues in regression analysis:
- How do we identify a statistical model from a theoretical argument?
- How do we understand the logic of regression analysis?
- How do we prepare data for the variables in the statistical model?
- How do we estimate the statistical model?
- How do we interpret the model estimates?
- How do we make statistical inferences based on the model estimates?
- How do we explain overall model fit?
To study the effect of trade on growth, Frankel and Romer (1999) start with the following theoretical premise:
$$
\ln Y_{i}=\alpha+\beta T_{i}+\gamma W_{i}+\varepsilon_{i}
$$
where $Y_{i}$ is income per person, $T_{i}$ indicates international trade, $W_{i}$ denotes within-country trade, and $\varepsilon_{i}$ represents other influences on income.
统计代写|r语言代考r project代写|HOW TO ESTIMATE AND INTERPRET OLS MODEL COEFFICIENTS
What technique should we use to estimate the sample regression model? As noted earlier, we use OLS, which is to find a set of coefficient estimates that minimizes the residual sum of squares. The specific OLS estimator (or equation) for the vector of coefficients in the sample model, denoted as $B$ containing $a, b$, $c_{1}$, and $c_{2}$, can be expressed as follows:
$$
\boldsymbol{B}=\left(\mathbf{X}^{\prime} \mathbf{X}\right)^{-1} \mathbf{X}^{\prime} \mathbf{Y}=\left(\sum \mathbf{x}{i} \mathbf{x}{i}^{\prime}\right)^{-1}\left(\sum \mathbf{x}{i} y{i}\right)
$$
The essence of the formula is that it allows us to find the set of $B$ (i.e., $a, b, c_{1}$, and $c_{2}$ ) that minimizes the residual sum of squares.
The $\mathrm{R}$ code for obtaining the OLS coefficient estimates and related output is straightforward. We begin with the $\operatorname{lm} 0$ function, which represents a linear model. The argument inside the function includes the dependent variable, followed by a tilde and the independent variables connected by plus sign, and the data= option for specifying the dataset. Once the model is estimated, the output from the $\operatorname{lm} 0$ function is assigned to some object, which we refer to as model1. To demonstrate the content of the model output, we simply apply the summary0 function to model1.
统计代写|R语言代考R PROJECT代写|How to Make an Inference about the Population Parameter of Interest
We may think about the relationship between the sample estimate $b$ and the population parameter $\beta_{1}$ within the context of OLS estimation and the Gauss-Markov theorem as follows:
$$
b \sim N\left(\beta_{1}, \operatorname{Var}(b)\right)
$$
According to the expression, the sample regression coefficient $b$ is assumed to be normally distributed with mean $\beta_{1}$ and variance $\operatorname{Var}(b)$.
It is essential for us to understand the nature of this expression because the statistical inferences we are making later on hinge on the following thought experiment. If we draw a first sample from the population and apply the OLS estimator equation listed in the previous section, we will obtain one $b$ value as the first estimate of $\beta_{1}$; if we repeat the process with a second sample, we will obtain a second $b$ value as the second estimate of $\beta_{1}$; and if we estimate our model in repeated samples, we will obtain as many $b$ estimates as the number of samples we draw from the population. As a result, $b$ behaves like a random variable, i.e.,its value varies from one sample to another. These estimates of $b$ from repeated samples form a probability distribution, called the sampling distribution of the sample regression coefficient estimator $b$. As noted, $b$ is assumed to be normally distributed with mean $\beta_{1}$ and variance $\operatorname{Var}(b)$.
Based on this background information, we will use null hypothesis testing and confidence interval construction to make two types of statistical inferences from the sample coefficient $b$ to the population parameter $\beta_{1}$. Below we will discuss them in turn using the results from modell.
R语言代写
统计代写|R语言代考R PROJECT代写|CONCEPTUAL PREPARATION: HOW TO UNDERSTAND REGRESSION ANALYSIS
贸易能促进经济增长吗?许多经济学家认为,从长远来看,贸易开放会促进增长,因为国际贸易增加了市场竞争,重新分配国内资源以更有效地利用,鼓励技术传播,扩大市场规模。然而,贸易开放与增长之间关系的统计证据相当混杂,并且对各种方法论批评持开放态度。在本节中,我们将提供一个来自贸易增长研究的简单示例来说明我们如何使用R和横截面回归分析来评估贸易对经济增长的影响。
我们的示例借鉴了一篇极具影响力的论文,该论文的 Google Scholar 引用次数超过 5,000:
Frankel、Jeffrey A. 和 David Romer。1999. “贸易会导致增长吗?” 美国经济评论 893: 379-99。
使用此示例,我们旨在说明回归分析中的以下问题:
- 我们如何从理论论证中识别统计模型?
- 我们如何理解回归分析的逻辑?
- 我们如何为统计模型中的变量准备数据?
- 我们如何估计统计模型?
- 我们如何解释模型估计?
- 我们如何根据模型估计进行统计推断?
- 我们如何解释整体模型拟合?
为了研究贸易对增长的影响,弗兰克尔和罗默1999从以下理论前提开始:
ln是一世=一种+b吨一世+C在一世+e一世
在哪里是一世是人均收入,吨一世表示国际贸易,在一世表示国内贸易,并且e一世代表对收入的其他影响。
统计代写|R语言代考R PROJECT代写|HOW TO ESTIMATE AND INTERPRET OLS MODEL COEFFICIENTS
我们应该使用什么技术来估计样本回归模型?如前所述,我们使用 OLS,即找到一组最小化残差平方和的系数估计值。特定的 OLS 估计器这r和q在一种吨一世这n对于样本模型中的系数向量,表示为乙包含一种,b, C1, 和C2, 可以表示为:
$$
\boldsymbol{B}=\left\mathbf{X}^{\prime} \mathbf{X}\right\mathbf{X}^{\prime} \mathbf{X}\right^{-1} \mathbf{X}^{\prime} \mathbf{Y}=\left(\sum \mathbf{x} {i} \mathbf{x} {i}^{\prime}\right) ^{-1}\left(\sum \mathbf{x} {i} y {i}\right)
$$
公式的本质是它可以让我们找到乙 一世.和.,$一种,b,C1$,一种nd$C2$最小化残差平方和。
这R获取 OLS 系数估计和相关输出的代码很简单。我们从流明0函数,它代表一个线性模型。函数内部的参数包括因变量,后跟波浪号和由加号连接的自变量,以及用于指定数据集的 data= 选项。估计模型后,输出流明0函数被分配给某个对象,我们称之为model1。为了演示模型输出的内容,我们简单地将 summary0 函数应用于 model1。
统计代写|R语言代考R PROJECT代写|HOW TO MAKE AN INFERENCE ABOUT THE POPULATION PARAMETER OF INTEREST
我们可以考虑样本估计之间的关系b和人口参数b1在 OLS 估计和 Gauss-Markov 定理的范围内如下:
b∼ñ(b1,曾是(b))
根据表达式,样本回归系数b假设正态分布,均值b1和方差曾是(b).
我们必须理解这个表达式的性质,因为我们稍后做出的统计推断取决于以下思想实验。如果我们从总体中抽取第一个样本并应用上一节中列出的 OLS 估计方程,我们将获得一个b值作为第一个估计b1; 如果我们用第二个样本重复这个过程,我们将获得第二个b值作为第二个估计b1; 如果我们在重复样本中估计我们的模型,我们将获得尽可能多的b估计为我们从总体中抽取的样本数量。因此,b表现得像一个随机变量,即它的值从一个样本到另一个样本不同。这些估计b从重复的样本中形成一个概率分布,称为样本回归系数估计的抽样分布b. 如前所述,b假设正态分布,均值b1和方差曾是(b).
基于此背景信息,我们将使用零假设检验和置信区间构造从样本系数进行两种统计推断b到人口参数b1. 下面我们将使用模型的结果依次讨论它们。

统计代写|r语言代考r project代写 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。