如果你也在 怎样代写missing data这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。missing data在统计学中,当观察中的变量没有存储数据值时,就会出现缺失数据,或缺失值。缺失数据是一种常见的现象,对从数据中得出的结论会有很大的影响。
missing data缺失数据的发生可能是由于无应答:没有为一个或多个项目或整个单位(”主体”)提供信息。有些项目比其他项目更有可能产生无应答现象:例如关于收入等私人主题的项目。损耗是一种可能发生在纵向研究中的缺失–例如研究发展,在一定时期后重复测量。当参与者在测试结束前退出,并且有一个或多个测量项目缺失时,就会出现缺失现象。
my-assignmentexpert™missing data作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的missing data作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此missing data作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在missing data代写方面经验极为丰富,各种missing data相关的作业也就用不着 说。
我们提供的missing data及其相关学科的代写,服务范围广, 其中包括但不限于:
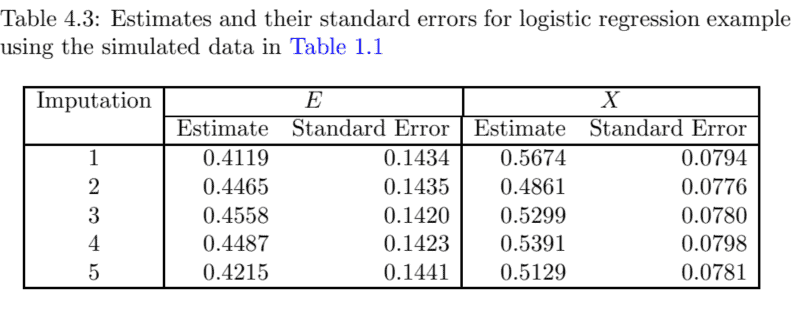
数学代写|missing data代考|Data in Table
For the data in Table $1.1$, cell-specific imputations may be performed using the normal model with cell-specific mean and cell-specific standard deviation. Consider the cell $D=0, E=0$ with 299 sample observations $\left(n_{o o}\right.$ ) but only 212 respondents $\left(r_{o o}\right)$. The assumed model is $x \sim N\left(\mu_{o o}, \sigma_{o o}^{2}\right)$ with a diffuse prior distribution for the parameters, $\pi\left(\mu_{o o} \sigma_{o o}\right) \propto \sigma_{o o}^{-1}$. The sample mean is $\bar{x}{o o}=-0.57$ and the sample variance $s{o o}^{2}=0.9^{2}$. Note from the basic theory that
- $\sqrt{r_{o o}}\left(\bar{x}{o o}-\mu{o o}\right) / \sigma_{o o} \sim N(0,1)$
- $\left(r_{o o}-1\right) s_{o o}^{2} / \sigma_{o o}^{2} \sim \chi_{r_{o o}-1}^{2}$.
The eighty seven observations can be multiply imputed as follows: - Generate a chi-square random variable, $u$, with $r_{o o}-1$ degrees of freedom and define $\sigma_{o o}^{2} *=211 \times 0.9^{2} / u$.
- Generate a random normal deviate $z$, and define $\mu_{o o}^{}=-0.57+$ $\sigma_{o o}^{} z / \sqrt{r_{o o}}$.
- Generate 87 random normal deviates, $z_{1}, z_{2}, \ldots, z_{87}$, and define $x_{j}^{}=\mu_{o o}^{}+\sigma_{o o}^{*} z_{j}$ as the imputed values.
- Repeat steps (1)-(3) $M$ times.
The same procedure can be applied for the other three cells. After imputation, fit the logistic regression model with $D$ as the outcome, $E$ and $X$ as the predictors. Table $4.2$ provides five imputed data estimates and their standard errors for the regression coefficient of $E$ in the logistic regression model with $D$ as the dependent variable and $E$ and $X$ as predictors. The mean of the regression coefficients for $E$ is $\bar{e}{M I}=0.4369$. The average of the squared standard error is $\bar{U}{M}=0.0205$ and the variance of the five estimates is $B_{M}=0.0190$ and, thus, $T_{M}=0.0205+(1+1 / 5) 0.0190=0.0433$ or the multiple imputation standard error is $0.2081$. The fraction of missing information is $r_{M}=(1+$ $1 / 5) 0.0190 / 0.0433=52.7 \%$ and the degrees of freedom $\nu_{M}=4 / .527^{2}=14.4$. This leads to a $95 \%$ confidence interval as $(.4369 \pm 2.14 \times 0.2081)$.
数学代写|missing data代考|Case-Control Study
Revisit the case-control analysis where the missing values in $\log ($ REDOMEGA3) was imputed using a model based procedure using the dietary value $\log ($ DIETOMEGA3 $+1)$. The number of missing values is rather large in this example $(73 \%$ for cases and $27 \%$ for controls). Since imputations are being carried out separately for cases and controls, a large number of imputations may be needed to get stable answers. The problem is simple enough to repeat the imputation a large number of times using a variety of software packages.
A total of $M=100$ imputations were carried out and after each imputation, the variable was retransformed back to the original scale, and then the substantive logistic regression model with PCA as the dependent variable and imputed (or completed) REDOMEGA3 as a predictor was fit. The second column in Table $4.4$ provides the estimated regression coefficient, its standard error and the fraction of missing information.
In this example, an auxiliary variable was used to impute the missing values with the hope of recovering information about the missing red cell membrane values. Perform multiple imputation analysis without using the auxiliary variable as a way to assess its usefulness. The last column in Table $4.4$ provides the estimate, standard error and the fraction of missing information based on $M=100$ imputations. Including dietary intake in the imputation model reduces the fraction of missing information by about five percentage points (6.4\% reduction in the standard error of the regression coefficient).
The efficiency gain in using dietary intake in the imputation process can differ by the type of parameters. Table $4.5$ provides information about estimating the mean of red-cell membrane values for cases and controls. Reduction in the standard error and the fraction of missing information are comparable to those given in Table 4.4.
missing data代写
数学代写|MISSING DATA代考|DATA IN TABLE
对于表中的数据1.1,可以使用具有细胞特异性平均值和细胞特异性标准差的正常模型来执行细胞特异性插补。考虑细胞D=0,和=0有 299 个样本观测值(n这这) 但只有 212 名受访者(r这这). 假设的模型是X∼ñ(μ这这,σ这这2)具有参数的扩散先验分布,圆周率(μ这这σ这这)∝σ这这−1. 样本均值是 $\bar{x} {oo}=-0.57一种nd吨H和s一种米pl和在一种r一世一种nC和s {oo}^{2}=0.9^{2}$。从基本理论中注意到
- $\sqrt{r_{oo}}\left(\bar{x} {oo}-\mu {oo}\right) / \sigma_{oo} \sim N0,1$
- (r这这−1)s这这2/σ这这2∼χr这这−12.
八十七个观察值可以按如下方式进行乘法估算: - 生成卡方随机变量,在, 和r这这−1自由度和定义σ这这2∗=211×0.92/在.
- 生成随机正态偏差和, 并定义 $\mu_{oo}^{ }=-0.57+\sigma_ {oo} ^ { } z / \ sqrt {r_ {oo}} $。
- 生成 87 个随机正态偏差,和1,和2,…,和87,并将 $x_{j}^{ }=\mu_{oo}^{ }+\sigma_{oo}^{*} z_{j}$ 定义为估算值。
- 重复步骤1-3 米次。
可以对其他三个单元应用相同的过程。插补后,拟合逻辑回归模型D结果,和和X作为预测器。桌子4.2为回归系数提供了五个估算数据估计值及其标准误差和在逻辑回归模型中D作为因变量和和和X作为预测器。回归系数的平均值和是 $D$ as the outcome, $E$ and $X$ as the predictors. Table $4.2$ provides five imputed data estimates and their standard errors for the regression coefficient of $E$ in the logistic regression model with $D$ as the dependent variable and $E$ and $X$ as predictors. The mean of the regression coefficients for $E$ is $\bar{e}{M I}=0.4369$. The average of the squared standard error is $\bar{U}{M}=0.0205$ and the variance of the five estimates is $B_{M}=0.0190$ and, thus, $T_{M}=0.0205+(1+1 / 5) 0.0190=0.0433$ or the multiple imputation standard error is $0.2081$. The fraction of missing information is $r_{M}=(1+$ $1 / 5) 0.0190 / 0.0433=52.7 \%$ and the degrees of freedom $\nu_{M}=4 / .527^{2}=14.4$. This leads to a $95 \%$ confidence interval as $(.4369 \pm 2.14 \times 0.2081)$.
数学代写|MISSING DATA代考|CASE-CONTROL STUDY
重新审视病例对照分析,其中缺失值日志(REDOMEGA3) 使用基于模型的程序使用膳食值进行估算日志(DIETOMEGA3+1). 在这个例子中缺失值的数量相当大(73%对于案件和27%用于控制)。由于对病例和对照分别进行插补,可能需要大量插补才能获得稳定的答案。这个问题很简单,可以使用各种软件包多次重复插补。
总计米=100进行插补,每次插补后,将变量重新转换回原始量表,然后以PCA为因变量进行实质性逻辑回归模型并进行插补这rC这米pl和吨和dREDOMEGA3 作为预测器是合适的。表中的第二列4.4提供估计的回归系数、其标准误差和缺失信息的比例。
在此示例中,使用辅助变量来估算缺失值,以期恢复有关缺失红细胞膜值的信息。执行多重插补分析,而不使用辅助变量作为评估其有用性的方法。表中的最后一列4.4提供估计值、标准误差和缺失信息的比例,基于米=100归责。在插补模型中包含膳食摄入量可将缺失信息的比例降低约 5 个百分点6.4%r和d在C吨一世这n一世n吨H和s吨一种nd一种rd和rr这r这F吨H和r和Gr和ss一世这nC这和FF一世C一世和n吨.
在估算过程中使用膳食摄入量的效率增益可能因参数类型而异。桌子4.5提供有关估计病例和对照的红细胞膜值平均值的信息。标准误差的减少和缺失信息的比例与表 4.4 中给出的相当。

数学代写|missing data代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。