如果你也在 怎样代写自然语言处理Natural Language Processing学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。自然语言处理Natural Language Processing是一个用于机器学习和人工智能的免费和开源的软件库。它可以用于一系列的任务,但特别专注于深度神经网络的训练和推理。
自然语言处理Natural Language Processing是语言学、计算机科学和人工智能的一个子领域,涉及计算机和人类语言之间的互动,特别是如何为计算机编程以处理和分析大量的自然语言数据。其目标是使计算机能够 “理解 “文件的内容,包括文件中语言的上下文细微差别。然后,该技术可以准确地提取文件中的信息和见解,并对文件本身进行分类和组织。
my-assignmentexpert™自然语言处理Natural Language Processing代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的自然语言处理Natural Language Processing作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此自然语言处理Natural Language Processing作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在机器学习Machine Learning代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的机器学习Machine Learning代写服务。我们的专家在自然语言处理NLP代写方面经验极为丰富,各种自然语言处理NLP相关的作业也就用不着 说。
我们提供的自然语言处理NLP及其相关学科的代写,服务范围广, 其中包括但不限于:
机器学习代写|自然语言处理代写NLP代考|POST-HOC UNSTRUCTURED PRUNING
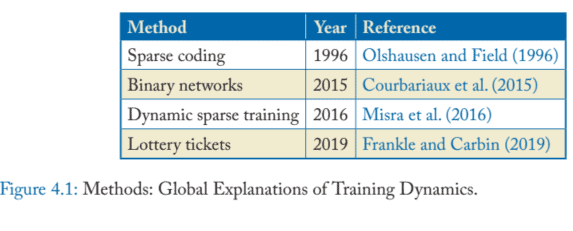
The idea of doing weight pruning based on the magnitude or gradients of the weights after training, has been around since LeCun et al. (1990). I refer to this approach as post-boc unstructured weight pruning. Han et al. (2015) is a good example of this class of methods, relying on raw magnitudes to decide which weights should be pruned. Gordon et al. (2020) and Mao et al. (2020) both use this method to compress language models.
Post-hoc unstructured pruning, of course, does not have to be a one-shot operation. It is perfectly possible to imagine iterating over training and pruning steps, leading to gradually smaller networks. Zhu and Gupta (2017), for example, add a binary weight mask for every layer, which is updated at every training iteration. They simply mask to zero the smallest magnitude weights at that step until some fixed sparsity level is reached.
Obviously, brute-force ablation is also a weight pruning strategy, albeit an expensive one. Several papers have proposed using ablation to identify cells in recurrent architectures that correlate with sentiment or linguistic properties (Kementchedjhieva and Lopez, 2018; Lakretz et al., 2019; Radford et al., 2017). Shibata et al. (2020) extract subspaces of the context vectors $c_{t_{i}}$ that correlate with linguistic properties.
机器学习代写|自然语言处理代写NLP代考|LOTTERY TICKETS
The lottery ticket hypothesis (Frankle and Carbin, 2019) refers to the idea that we can sometimes train networks from initialisations that are 10 or 100 times smaller than the full network, with a minimal loss in performance. The method is in its most general form: after training you identify (using some identification method) a subset of weights that you then re-initialize (to their original initial weights, not to new random weights); you then retrain the network omitting all other weights. This adds a second perspective to our search through the loss landscape; our search for a decent-sized valley is also a search for a subset of parameters with good initial weights. Encouragingly, Morcos et al. (2019) and others found that these initializations are useful across datasets and tasks. Several identification methods have been proposed for extracting such tickets.
Frankle and Carbin (2019) present an iterative, unstructured pruning method that relies on raw weight magnitudes. The method is simply referred to as iterative magnitude pruning. The pruning is done after training, and the magnitudes are the changes in weight magnitudes relative to the random initialization. Frankle et al. $(2020)$ shows that iterative magnitude pruning succeeds in finding good sub-networks if they are stable to noise. In order to make sub-networks more robust, they re-initialize weights to their values at iteration $k$ (for some small $k$ ) rather than their values at iteration 0 . This is called iterative magnitude pruning with rewinding. Rewinding empirically performs well (Renda et al., 2020) and has also seen applications in NLP (Brix et al., 2020). Malach et al. (2020) and Orseau et al. (2020) subsequently showed that for sufficiently large networks, good performance can be achieved without training.
机器学习代写|自然语言处理代写NLP代考|DYNAMIC SPARSE TRAINING
Post-hoc weight pruning induces a network first, then prunes it. The lottery ticket method retrains the network after pruning it, but would it perhaps be superior to jointly train and prune networks? Several papers have in recent years presented variations over the idea that I here refer to as dynamic sparse training, i.e., that idea that we can learn a binary weight mask during training, not simply by ranking weight magnitudes or performing post-hoc relevance propagation.
Earlier work on dynamic sparse training was mostly about structured pruning: cross-stitch networks (Misra et al., 2016) used special parameters to control sharing between pairs of layers of deep neural networks. The parameters were called stitches, stitching together two task-specific neural networks, but can also be thought of as masking sub-networks in a fully shared architecture. Ruder et al. (2018) used a similar approach to make recurrent multi-task learning architectures for NLP tasks better and more sparse, but using smooth indicator functions. These indicator functions were called sluices and are directly interpretable. Note that since the indicator functions are smooth, the joint architecture is differentiable in both cases.
自然语言处理代写
机器学习代写|自然语言处理代写NLP代考|POST-HOC UNSTRUCTURED PRUNING
自 LeCun 等人以来,基于训练后权重的大小或梯度进行权重修剪的想法一直存在。1990. 我将这种方法称为 post-boc 非结构化权重修剪。韩等人。2015是这类方法的一个很好的例子,它依赖于原始大小来决定应该修剪哪些权重。戈登等人。2020和毛等人。2020两者都使用这种方法来压缩语言模型。
当然,事后非结构化修剪不一定是一次性操作。完全可以想象迭代训练和修剪步骤,导致网络逐渐变小。朱和古普塔2017例如,为每一层添加一个二进制权重掩码,该掩码在每次训练迭代时更新。他们只是在该步骤中将最小的权重掩码为零,直到达到某个固定的稀疏度水平。
显然,蛮力消融也是一种权重修剪策略,尽管成本很高。几篇论文提出使用消融来识别与情感或语言特性相关的循环架构中的细胞ķ和米和n吨CH和djH一世和在一个一个nd大号○p和和,2018;大号一个ķr和吨和和吨一个l.,2019;R一个dF○rd和吨一个l.,2017. 柴田等人。2020提取上下文向量的子空间C吨一世与语言属性相关。
机器学习代写|自然语言处理代写NLP代考|LOTTERY TICKETS
彩票假说Fr一个nķl和一个ndC一个rb一世n,2019指的是我们有时可以从比完整网络小 10 或 100 倍的初始化中训练网络,而性能损失最小。该方法是最通用的形式:经过培训,您确定在s一世nGs○米和一世d和n吨一世F一世C一个吨一世○n米和吨H○d然后重新初始化的权重子集吨○吨H和一世r○r一世G一世n一个l一世n一世吨一世一个l在和一世GH吨s,n○吨吨○n和在r一个nd○米在和一世GH吨s; 然后你重新训练网络忽略所有其他权重。这为我们搜索损失情况增加了第二个视角;我们对适当大小的山谷的搜索也是对具有良好初始权重的参数子集的搜索。令人鼓舞的是,Morcos 等人。2019和其他人发现这些初始化在数据集和任务中很有用。已经提出了几种用于提取此类票证的识别方法。
弗兰克和卡宾2019提出了一种依赖于原始权重大小的迭代、非结构化修剪方法。该方法简称为迭代幅度修剪。修剪是在训练之后进行的,幅度是权重幅度相对于随机初始化的变化。弗兰克等人。(2020)表明如果迭代幅度修剪对噪声稳定,则它们可以成功找到好的子网络。为了使子网络更加健壮,它们在迭代时将权重重新初始化为它们的值ķ F○rs○米和s米一个ll$ķ$而不是它们在迭代 0 时的值。这称为带有倒带的迭代幅度修剪。倒带凭经验表现良好R和nd一个和吨一个l.,2020并且还看到了在 NLP 中的应用乙r一世X和吨一个l.,2020. 马拉赫等人。2020和 Orseau 等人。2020随后表明,对于足够大的网络,无需训练即可获得良好的性能。
机器学习代写|自然语言处理代写NLP代考|DYNAMIC SPARSE TRAINING
事后权重修剪首先诱导网络,然后修剪它。彩票方法在修剪后重新训练网络,但它可能优于联合训练和修剪网络吗?近年来,有几篇论文提出了对我在这里称为动态稀疏训练的想法的变体,即我们可以在训练期间学习二进制权重掩码的想法,而不仅仅是通过对权重大小进行排序或执行事后相关性传播。
早期关于动态稀疏训练的工作主要是关于结构化修剪:十字绣网络米一世sr一个和吨一个l.,2016使用特殊参数来控制深度神经网络层对之间的共享。这些参数被称为缝合,将两个特定于任务的神经网络缝合在一起,但也可以被认为是完全共享架构中的掩蔽子网络。鲁德等人。2018使用类似的方法使 NLP 任务的循环多任务学习架构更好、更稀疏,但使用平滑的指示函数。这些指标函数被称为水闸,可以直接解释。请注意,由于指标函数是平滑的,因此联合架构在两种情况下都是可微的。

机器学习代写|自然语言处理代写NLP代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。