如果你也在 怎样代写贝叶斯统计Bayesian Statistics STA619这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。贝叶斯统计Bayesian Statistics是统计学领域的一种理论,基于对概率的贝叶斯解释,其中概率表达了对某一事件的相信程度。相信的程度可以基于关于该事件的先验知识,如以前的实验结果,或基于个人对该事件的信念。这与其他一些对概率的解释不同,例如频繁主义的解释将概率视为一个事件在多次试验后的相对频率的极限。
贝叶斯统计Bayesian Statistics方法使用贝叶斯定理来计算和更新获得新数据后的概率。贝叶斯定理描述了基于数据以及关于该事件或与该事件相关的条件的先验信息或信念的事件的条件概率。例如,在贝叶斯推理中,贝叶斯定理可用于估计概率分布或统计模型的参数。由于贝叶斯统计学将概率视为信仰的程度,所以贝叶斯定理可以直接将量化信仰的概率分布分配给参数或参数集。
贝叶斯统计Bayesian Statistics代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。最高质量的贝叶斯统计Bayesian Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此贝叶斯统计Bayesian Statistics作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在统计Statistics代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在贝叶斯统计Bayesian Statistics代写方面经验极为丰富,各种贝叶斯统计Bayesian Statistics相关的作业也就用不着说。
统计代写|贝叶斯统计代写Bayesian Statistics代考|R AND STAN
Modern Bayesian data analysis uses computers. Luckily for the student of Bayesian statistics, the most up-to-date and useful software packages are open source, meaning they are freely available to use. In this book, we use solely this type of software.
The most recent, and powerful, software to emerge is Stan, developed by Andrew Gelman et al. $[8,34]$. The language of this software is not difficult to understand, and the code is easier to write and debug than its competition. Stan allows a user to fit complex models to data sets without having to wait an age for the results. It is now the de facto choice of modelling software for MCMC for most researchers who use Bayesian statistics. This is reflected in terms of both the number of papers that cite Stan and the number of textbooks that use Stan as their programming language of choice. This popularity matters. It means that the language is here to stay, and will likely continue to improve. It also means that there is an active user forum (which is managed by Stan developers) where you can often find answers to issues by searching through the question bank or, failing a resolution, ask a question yourself. In short, if you run into issues with your code or have trouble with the sampling, then there are a range of places you can go to find a solution (covered in detail in Chapter 16).
Stan is usually run through another piece of ‘helper’ software. While a number of alternatives are available, we choose to use $\mathrm{R}$ because it is open source and widely used. This means that anyone with a modern computer can get their hands dirty in Bayesian analysis. Its popularity is important since the code base is well maintained and tested.
Whenever appropriate, particularly in Part IV onwards, we include snippets of code in $\mathrm{R}$ and Stan. These are commented thoroughly, which should be self-explanatory.
统计代写|贝叶斯统计代写Bayesian Statistics代考|WHY DON’T MORE PEOPLE USE BAYESIAN STATISTICS?
Many are discouraged from using Bayesian statistics for analysis due to its supposed difficulty and its dependence on mathematics. We argue that this is, in part, a weakness of the existing literature on the subject, which this book seeks to address. It also highlights how many books on Frequentist statistics sweep their inherent complexity and assumptions under the carpet, to make their texts easier to digest. This means that for many practitioners it seems that the path of least resistance is to forge ahead with Frequentist tools.Because of its dependence on the logic of probability, Bayesian statistics superficially appears mathematically complex. What is often lost in introductory texts on Bayesian theory is the intuitive explanations behind the mathematical formulae. Instead, here we consciously choose to shift the emphasis towards the intuition behind the theory. We focus on graphical and illustrative explanations rather than getting lost in the details of the mathematics, which is not necessary for much of modern Bayesian analysis. We hope that by doing so, we shall lose fewer casualties to the mathematical complexity and redress the imbalance between Frequentist and Bayesian analyses.
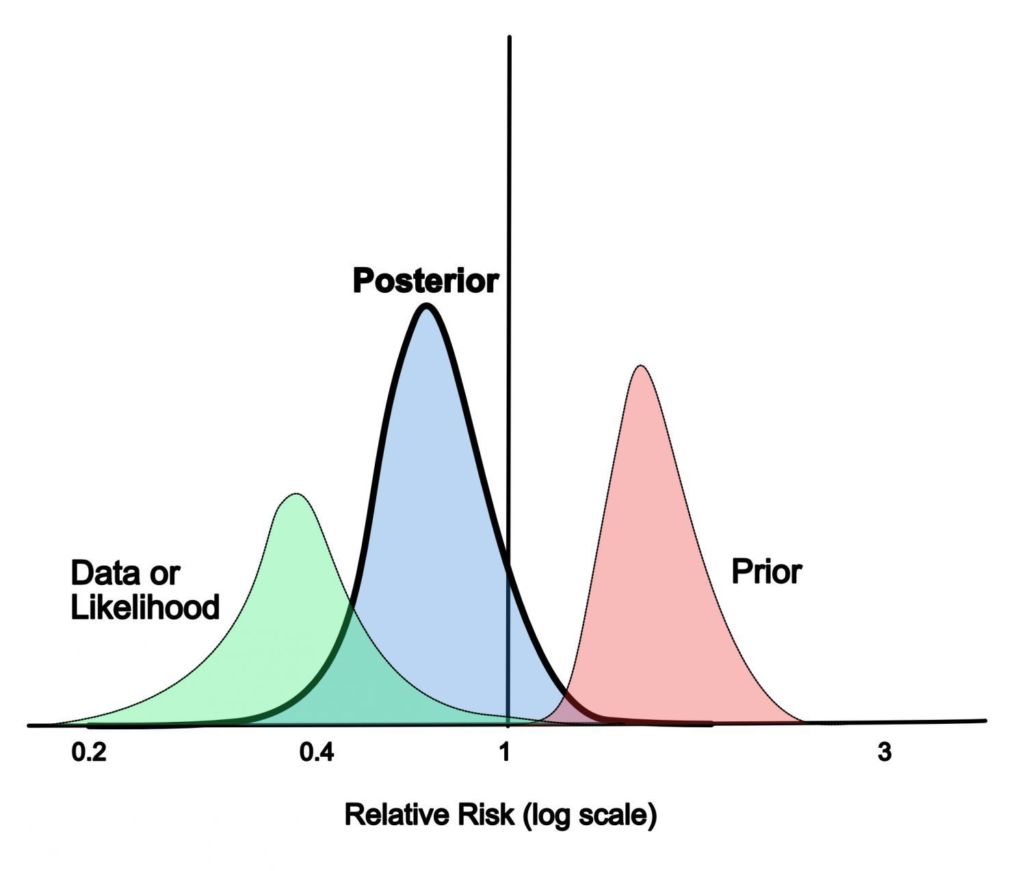
On first appearances, the concept of the prior no doubt leads many to abandon ship early on the path to understanding Bayesian methodologies. This is because some view this aspect of Bayesian inference as wishy-washy and hence a less firm foundation on which to build an analysis. We cover this concept in detail in Chapter 5, which is fully devoted to this subject, where we hope to banish this particular thorn in the side of would-be Bayesian statisticians.
The reliance on computing, in particular simulation, is also seen to inflate the complexity of Bayesian approaches. While Bayesian statistics is reliant on computers, we should recognise that, nowadays, the same is true for Frequentist statistics. No applied statistician does research using only pen and paper. We also argue that the modern algorithms used for simulation in Bayesian inference are straightforward to understand and, with modern software, easy to implement. Furthermore, the added complexity of simulation methods is compensated for by the straightforward extension of Bayesian models to handle arbitrarily complex situations. Like most things worth studying, there is a slight learning curve to become acquainted with a language used to write modern Bayesian simulations. We hope to make this curve sufficiently shallow by introducing the elements used in these computational applications incrementally.
贝叶斯统计代写
统计代写|贝叶斯统计代写BAYESIAN STATISTICS代考|R AND STAN
现代贝叶斯数据分析使用计算机。幸运的是,对于贝叶斯统计的学生来说,最新和最有用的软件包都是开源的,这意味着它们可以免费使用。在本书中,我们只使用这种类型的软件。
最新出现的、功能强大的软件是由 Andrew Gelman 等人开发的 Stan。[8,34]. 这个软件的语言不难理解,而且代码比它的竞争对手更容易编写和调试。Stan 允许用户将复杂的模型拟合到数据集,而无需等待一段时间才能得到结果。对于大多数使用贝叶斯统计的研究人员来说,它现在是 MCMC 建模软件的实际选择。这反映在引用 Stan 的论文数量和使用 Stan 作为他们选择的编程语言的教科书数量上。这种受欢迎程度很重要。这意味着该语言将继续存在,并且可能会继续改进。这也意味着有一个活跃的用户论坛在H一世CH一世s米一个n一个G和db是小号吨一个nd和在和l○p和rs您通常可以通过在问题库中搜索来找到问题的答案,或者,如果没有解决问题,您可以自己提出问题。简而言之,如果您在代码中遇到问题或在采样时遇到问题,那么您可以去很多地方寻找解决方案C○在和r和d一世nd和吨一个一世l一世nCH一个p吨和r16.
Stan 通常通过另一个“帮助”软件运行。虽然有许多替代方案可用,但我们选择使用R因为它是开源的并且被广泛使用。这意味着任何拥有现代计算机的人都可以进行贝叶斯分析。它的受欢迎程度很重要,因为代码库得到了很好的维护和测试。
在适当的时候,特别是在第四部分之后,我们会在其中包含代码片段R和斯坦。对这些进行了彻底的评论,这应该是不言自明的。
统计代写|贝叶斯统计代写BAYESIAN STATISTICS代考|WHY DON’T MORE PEOPLE USE BAYESIAN STATISTICS?
许多人不鼓励使用贝叶斯统计进行分析,因为它假定的困难和对数学的依赖。我们认为,这在一定程度上是关于该主题的现有文献的一个弱点,本书试图解决这一问题。它还强调了有多少关于频率统计的书籍将其固有的复杂性和假设隐藏在地毯下,以使其文本更易于消化。这意味着,对于许多从业者来说,阻力最小的路径似乎是使用频率工具进取。由于它依赖于概率逻辑,贝叶斯统计在数学上表面上看起来很复杂。在贝叶斯理论的介绍性文本中经常丢失的是数学公式背后的直观解释。反而,在这里,我们有意识地选择将重点转移到理论背后的直觉上。我们专注于图形和说明性的解释,而不是迷失在数学的细节中,这对于现代贝叶斯分析的大部分来说是不必要的。我们希望通过这样做,我们将在数学复杂性中损失更少的伤亡,并纠正频率分析和贝叶斯分析之间的不平衡。
在第一次出现时,先验的概念无疑会导致许多人在理解贝叶斯方法的道路上早早放弃。这是因为有些人认为贝叶斯推理的这一方面是空洞的,因此建立分析的基础不太牢固。我们将在第 5 章详细介绍这个概念,该章完全致力于这个主题,我们希望在其中消除潜在的贝叶斯统计学家的这一特殊刺。
对计算的依赖,特别是模拟,也被认为增加了贝叶斯方法的复杂性。虽然贝叶斯统计依赖于计算机,但我们应该认识到,如今,频率统计也是如此。没有应用统计学家只使用笔和纸进行研究。我们还认为,用于贝叶斯推理模拟的现代算法易于理解,并且使用现代软件易于实现。此外,通过直接扩展贝叶斯模型来处理任意复杂的情况,可以补偿模拟方法增加的复杂性。像大多数值得研究的东西一样,熟悉用于编写现代贝叶斯模拟的语言需要一点学习曲线。

统计代写|贝叶斯统计代写Bayesian Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。