如果你也在 怎样代写高级数据分析Advanced Data Analysis DATA4010这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。高级数据分析Advanced Data Analysis在网络理论的背景下,复杂网络是指具有非微观拓扑特征的图(网络)–这些特征在简单的网络(如格子或随机图)中不会出现,但在代表真实系统的网络中经常出现。复杂网络的研究是一个年轻而活跃的科学研究领域(自2000年以来),主要受到现实世界网络的经验发现的启发,如计算机网络、生物网络、技术网络、大脑网络、气候网络和社会网络。
高级数据分析Advanced Data Analysis大多数社会、生物和技术网络显示出实质性的非微观拓扑特征,其元素之间的连接模式既不是纯粹的规则也不是纯粹的随机。这些特征包括学位分布的重尾、高聚类系数、顶点之间的同态性或异态性、社区结构和层次结构。在有向网络的情况下,这些特征还包括互惠性、三联体重要性概况和其他特征。相比之下,过去研究的许多网络的数学模型,如格子和随机图,并没有显示这些特征。最复杂的结构可以由具有中等数量相互作用的网络实现。这与中等概率获得最大信息含量(熵)的事实相对应。
高级数据分析Advanced Data Analysis代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。最高质量的高级数据分析Advanced Data Analysis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此高级数据分析Advanced Data Analysis作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在统计Statistics代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在高级数据分析Advanced Data Analysis代写方面经验极为丰富,各种高级数据分析Advanced Data Analysis相关的作业也就用不着说。
数据科学代写|数据分析代写Data Analysis代考|Data
The traffic data we considered in our analysis was provided by INE (Instituto Nacional de Estatística/Statistics Portugal) and by IMT (Instituto da Mobilidade e dos Transportes, I.P.). Although there are only tolls in the South-North direction, traffic is also counted in the other direction through sensors placed on the floor. The available data consists in the number of vehicles. No information is available regarding the class of a vehicle and the corresponding load. INE provided an archive of public data with easy online access. Regarding traffic volume, the data obtained from INE consists in the annual and monthly average daily traffic between 1998 and 2019. To study variations in the traffic, including the extreme values, the daily average could be meaningless. Thus, daily (or hourly) observations are more appropriate to make inferences in the right tail. Daily values since January 1, 2010 to December 31, 2018 were provided on request by IMT. We also obtained from IMT annual and monthly average daily data for the years before 1998.
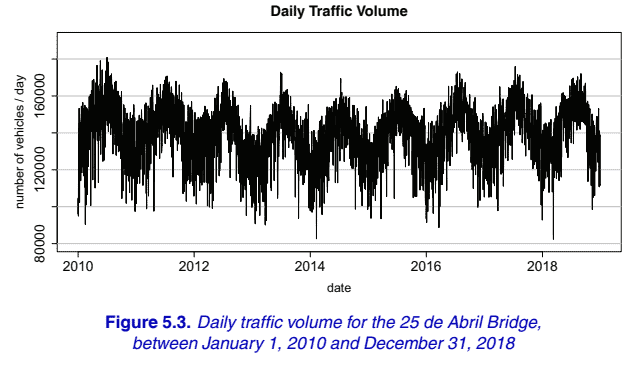
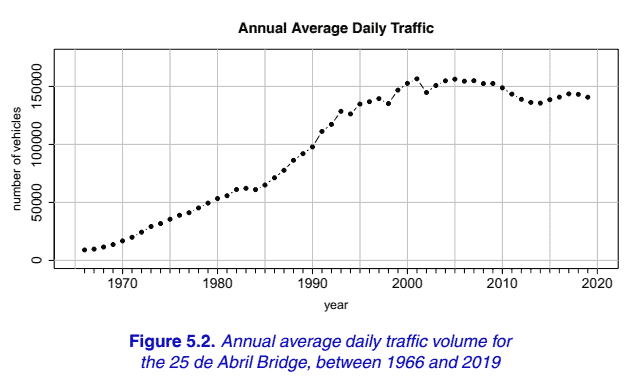
Figure $5.2$ shows the annual average daily traffic from 1966 to 2019 . The years from 1966 to 2001 corresponds to a period of traffic growth. After 2001, the annual average daily traffic number appears to be stationary, with a change point in 2010. Note that the year 2001 corresponds to the beginning of the Portugal economic downturn and 2010 corresponds to the beginning of the sustainability financial crisis. In Figure 5.3, we present the time series plot of the daily traffic volume. The plot evidence shows strong seasonality within each year. The traffic volume is smaller in the winter months (December-February) and higher in the summer months (June-August). The three smallest values occurred on February 9, $2014(82,408$ vehicles), March 20, 2016 (82,654 vehicles) and March 11, 2018 (88,765 vehicles). The smallest number of vehicles was a consequence of the strong wind: the central lanes were closed, and traffic was closed to motorcycles and vehicles with canvas hoods. The other two dates coincide with the Lisbon Half Marathon where the bridge was closed to vehicles for several hours. The highest number of vehicles registered in the period 2010-2018 occurred on July 2, 2010 (180,846 vehicles).
数据科学代写|数据分析代写Data Analysis代考|Main limit results
Let $\left(X_1, \ldots, X_n\right)$ be a sample of independent and identically distributed (iid) random variables from an underlying population with unknown distribution function (df) $F$. Here, and due to the nature of the problem under study, we will always deal with the right tail of $F$. Since:
$$
\min \left(X_1, \ldots, X_n\right)=-\max \left(-X_1, \ldots,-X_n\right),
$$
results for the left tail can be easily derived from the analogous results for the right tail. Fréchet (1927) and Fisher and Tippett (1928) were the first to derive asymptotic probability models for the transformed sample maximum. The first fundamental limit result is due to Gnedenko (1943) who fully characterized the three possible non-degenerate limit distributions of the linearly normalized sample maximum of iid random variables (see also von Mises $(1964)^1$ ). This result is now known as the extremal types theorem. Let $X_{(n)}=\max {1 \leq i \leq n}\left(X_i\right)$ be the sample maximum. Let us also assume that there exist normalizing constants $a_n>0, b_n \in \mathbb{R}$ and some non-degenerate df $G$ such that, for all $x$, $$ \lim {n \rightarrow \infty} P\left(\frac{X_{(n)}-b_n}{a_n} \leq x\right)=G(x)
$$
高级数据分析代写
数据科学代写|数据分析代写DATA ANALYSIS代考|DATA
我们在分析中考虑的流量数据由 INE 提供InstitutoNacionaldeEstatística/StatisticsPortugal并通过 IMTInstitutodaMobilidadeedosTransportes, I. P.. 虽然只有南北方向的通行费,但通过放置在地板上的传感器也会计算另一个方向的交通流量。可用数据包括车辆数量。没有关于车辆美别和相应负载的信息。INE 提供了一个公共数据档宴,可以方便地在线访问。关于交通量,能源中心得到的数据是1998年到2019年的年平均日交通量和月平均日交通量。为了研究交通量的变 化,包括极值,日平均可能没有意义。因此,每天orhourly观崇结果更适合在右尾做出推断。IMT 应要求提供了自 2010 年 1 月 1 日至 2018 年 12 月 31 日的每日 值。我们还从 IMT 中获得了 1998 年之前的年度和月平均每日数据。
数字 $5.2$ 显示了从 1966 年到 2019 年的年平均日流量。从 1966 年到 2001 年对应于流量增长的时期。2001 年之后,年平均每日交通量似乎保持不变,2010 年有一个 变化点。请注意, 2001 年对应于葡萄牙经济橐退的开始,2010 年对应于可持续性金融危机的开始。在图 5.3中,我们展示了每日交通量的时间序列图。情节证据显 示每年都有很强的案节性。冬薛交通流量较小December-February夏季更高 June-August. 三个最小值出现在 2 月 9 日,2014(82, 408车辆),2016年 3 月 20 日 82,654 vehicles 和 2018 年 3 月 11 日 88,765 vehicles. 车辆数量最少是强风的结果: 中央车道关闭,摩托车和带帆布置的车辆禁止通行。另外两个日期恰逢里 斯本半程马拉松赛,当时这座桥对车辆关闭了几个小时。2010-2018 年期间登记的车辆数量最多发生在 2010 年 7 月 2 日 $180,846 v e h i c l e s$.
数据科学代写|数据分析代写DATA ANALYSIS代考|MAIN LIMIT RESULTS
让 $\left(X_1, \ldots, X_n\right)$ 是独立同分布的样本 $i i d$ 来自具有末知分布函数的基础群体的随机变量 $d f F$. 在这里,由于正在研究的问题的性质,我们将始終处理右尾 $F$. 自从:
$$
\min \left(X_1, \ldots, X_n\right)=-\max \left(-X_1, \ldots,-X_n\right),
$$
左尾的结果可以很容易地从右尾的类似结果中推导出来。弗雷谢 1927 费舍尔和蒂皮特1928是第一个推导出变换样本最大值的渐近概率模型的人。第一个基本极限 结果是由于 Gnedenko1943谁充分表征了 iid 随机变量的线性归一化样本最大值的三种可能的非退化极限分布 seealsovonMises\$(1964^1 bethesamplemaximum. Letusalsoassumethatthereexistnormalizingconstantsa_n $>0, \mathrm{~b}{-} \mathrm{n} \backslash$ in $\backslash \mathrm{mathbb}[\mathrm{R}]$ andsomenon – degenerated $\mathrm{G} \mathrm{G}$ suchthat, forallX, $\lim n \rightarrow \infty P\left(\frac{X{(n)}-b_n}{a_n} \leq x\right)=G(x) \$$

数据科学代写|高级数据分析代写Advanced Data Analysis代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。