如果你也在 怎样代写算法和结构Data Structures and Algorithms 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。算法和结构Data Structures and Algorithms在计算机科学的众多子领域中,可能是最基本的——它似乎是计算机科学的特征,数据结构和算法着眼于如何最好地表示和处理计算机程序的数据。
算法和结构Data Structures and Algorithms数据结构是一种在虚拟系统中组织数据的方法。想想数字序列或数据表:它们都是定义良好的数据结构。算法是由计算机执行的一系列步骤,它接受输入并将其转换为目标输出。数据结构和算法结合在一起,允许程序员构建他们想要的任何计算机程序。对数据结构和算法的深入研究确保了良好优化和高效的代码。有许多用于不同目的的算法。它们以相同的计算复杂度与不同的数据结构交互。将算法视为与静态数据结构交互的动态底层部分。
my-assignmentexpert™数据结构Data Structure代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的数据结构Data Structure作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此数据结构Data Structure作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在计算机Computers代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Computers代写服务。我们的专家在数据结构Data Structure代写方面经验极为丰富,各种数据结构Data Structure相关的作业也就用不着 说。
我们提供的数据结构Data Structure CIS1210及其相关学科的代写,服务范围广, 其中包括但不限于:
计算机代写|算法和结构代考Data Structures and Algorithms代写|The Efficiency of Selection Sort
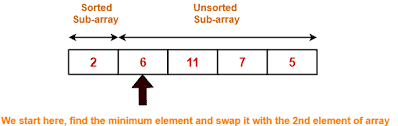
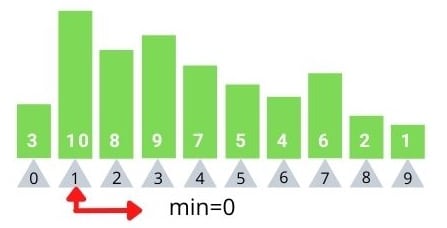
Selection Sort contains two types of steps: comparisons and swaps. That is, we compare each element with the lowest number we’ve encountered in each passthrough, and we swap the lowest number into its correct position.
Looking back at our example of an array containing five elements, we had to make a total of ten comparisons. Let’s break it down.
Passthrough # # of comparisons
$\begin{array}{cc}1 & 4 \text { comparisons } \ 2 & 3 \text { comparisons } \ 3 & 2 \text { comparisons } \ 4 & 1 \text { comparison }\end{array}$
So that’s a grand total of $4+3+2+1=10$ comparisons.
To put it more generally, we’d say that for $\mathrm{N}$ elements, we make $(N-1)+(N-2)+(N-3) \ldots+1$ comparisons.
As for swaps, however, we only need to make a maximum of one swap per passthrough. This is because in each passthrough, we make either one or zero swaps, depending on whether the lowest number of that passthrough is already in the correct position. Contrast this with Bubble Sort, where in a worst-case scenario-an array in descending order-we have to make a swap for each and every comparison.
Here’s the side-by-side comparison between Bubble Sort and Selection Sort:
N elements Max # of steps in Bubble Sort Max # of steps in Selection Sort
$\begin{array}{ccc}5 & 20 & 14 \text { (10 comparisons }+4 \text { swaps) } \ 10 & 90 & 54(45 \text { comparisons }+9 \text { swaps) } \ 20 & 380 & 199(180 \text { comparisons }+19 \text { swaps) } \ 40 & 1560 & 819(780 \text { comparisons }+39 \text { swaps) } \ 80 & 6320 & 3239(3160 \text { comparisons }+79 \text { swaps) }\end{array}$
From this comparison, it’s clear that Selection Sort contains about half the number of steps that Bubble Sort does, indicating that Selection Sort is twice as fast.
计算机代写|算法和结构代考Data Structures and Algorithms代写|Ignoring Constants
But here’s the funny thing: in the world of Big O Notation, Selection Sort and Bubble Sort are described in exactly the same way.
Again, Big O Notation describes how many steps are required relative to the number of data elements. So it would seem at first glance that the number of steps in Selection Sort are roughly half of whatever $N^2$ is. It would therefore seem reasonable that we’d describe the efficiency of Selection Sort as being $\mathrm{O}\left(\mathrm{N}^2 / 2\right)$. That is, for $\mathrm{N}$ data elements, there are $\mathrm{N}^2 / 2$ steps. The following table bears this out:
$\begin{array}{ccc}\text { N elements } & N^2 / 2 & \text { Max # of steps in Selection Sort } \ 5 & 5^2 / 2=12.5 & 14 \ 10 & 10^2 / 2=50 & 54 \ 20 & 20^2 / 2=200 & 199 \ 40 & 40^2 / 2=800 & 819 \ 80 & 80^2 / 2=3200 & 3239\end{array}$
In reality, however, Selection Sort is described in Big $\mathrm{O}$ as $\mathrm{O}\left(\mathrm{N}^2\right)$, just like Bubble Sort. This is because of a major rule of Big $O$ that we’re now introducing for the first time:
Big O Notation ignores constants.
This is simply a mathematical way of saying that Big O Notation never includes regular numbers that aren’t an exponent.
In our case, what should technically be $\mathrm{O}\left(\mathrm{N}^2 / 2\right)$ becomes simply $\mathrm{O}\left(\mathrm{N}^2\right)$. Similarly, $\mathrm{O}(2 \mathrm{~N})$ would become $\mathrm{O}(\mathrm{N})$, and $\mathrm{O}(\mathrm{N} / 2$ ) would also become $\mathrm{O}(\mathrm{N})$. Even $\mathrm{O}(100 \mathrm{~N})$, which is 100 times slower than $\mathrm{O}(\mathrm{N})$, would also be referred to as $\mathrm{O}(\mathrm{N})$.
Offhand, it would seem that this rule would render Big O Notation entirely useless, as you can have two algorithms that are described in the same exact way with Big $\mathrm{O}$, and yet one can be 100 times faster than the other. And that’s exactly what we’re seeing here with Selection Sort and Bubble Sort. Both are described in Big $\mathrm{O}$ as $\mathrm{O}\left(\mathrm{N}^2\right)$, but Selection Sort is actually twice as fast as Bubble Sort. And indeed, if given the choice between these two options, Selection Sort is the better choice.
数据结构代写
计算机代写|算法和结构代考DATA STRUCTURES AND ALGORITHMS代写|THE EFFICIENCY OF SELECTION SORT
选择排序包含两种类型的步骤:比较和交换。也就是说,我们将每个元素与我们在每次传递中遇到的最小数字进行比较,并将最小数字交换到正 确的位置。
回顾我们包含五个元素的数组示例,我们总共需要进行十次比较。让我们分解一下。
Passthrough # # 比较
14 comparisons 2 3 comparisons 3 2 comparisons $4 \quad 1$ comparison
所以这是一个总计 $4+3+2+1=10$ 比较。
更一般地说,我们会说 $N$ 元素,我们制作 $(N-1)+(N-2)+(N-3) \cdots+1$ 比较。
然而,对于交换,我们只需要每次传递最多进行一次交换。这是因为在每次传递中,我们都会进行一次或零次交换,具体取决于该传递的最低数 量是否已经处于正确的位置。将此与冒泡排序进行对比,在最坏的情况下一一降序排列的数组一-我们必须为每个比较进行交换。
这是員泡排序和选择排序之间的并排比较:
$\mathrm{N}$ 个元素冒泡排序中的最大步骤数选择排序中的最大步骤数
52014 (10 comparisons +4 swaps) $10 \quad 90 \quad 54(45$ comparisons +9 swaps $) 20 \quad 380 \quad 199(180$ comparisons +19 swaps) 40 从这个比较中可以清楚地看出,选择排序包含的步際数大约是冒泡排序的一半,这表明选择排序的速度是冒泡排序的两倍。
计算机代写|算法和结构代考DATA STRUCTURES AND ALGORITHMS代写|IGNORING CONSTANTS
但有趣的是:在大 O表示法的世界中,选择排序和員泡排序的描述方式完全相同。
同样,Big O Notation 描述了相对于数据元維的数量需要多少步溌。所以乍一看,选择排序的步骤数大约是任何排序的一半 $N^2$ 是。因此,我们将选择排序的效率描 述为是合理的 $\mathrm{O}\left(\mathrm{N}^2 / 2\right)$. 也就是说,对于 $\mathrm{N}$ 数据元表,有 $\mathrm{N}^2 / 2$ 脚步。下表证实了这一点:
$\mathrm{N}$ elements $N^2 / 2 \quad$ Max # of steps in Selection Sort $5 \quad 5^2 / 2=12.5 \quad 1410 \quad 10^2 / 2=50 \quad 5420 \quad 20^2 / 2=200 \quad 19940 \quad 40^2 / 2=800 \quad 81980$
然而,实际上,选择排序在 BigO作为 $\mathrm{O}\left(\mathrm{N}^2\right)$ ,就像員泡排序一样。这是因为 Big 的一个主要规则 $O$ 我们现在首次介绍:
Big 0 Notation ignores constants.
这只是一种数学方式,表明 Big O Notation 从不包含不是指数的常规数字。
在我们的例子中,技术上应该是什么 $\mathrm{O}\left(\mathrm{N}^2 / 2\right)$ 变得简单 $\mathrm{O}\left(\mathrm{N}^2\right)$. 相似地, $\mathrm{O}(2 \mathrm{~N})$ 会成为 $\mathrm{O}(\mathrm{N})$ ,和O(N/2) 也会变成 $\mathrm{O}(\mathrm{N})$. 甚至O(100 $\left.\mathrm{N}\right)$ ,比慢 100 倍 $\mathrm{O}(\mathrm{N})$, 也 称为 $\mathrm{O}(\mathrm{N})$.
顺便说一下,这条规则似乎会使 Big O Notation 完全无用,因为您可以拥有两种以与 Big 完全相同的方式描述的算法O,但一个可以比另一个快 100 倍。这正是我们 在这里看到的选择排序和員泡排序的情况。两者都在 Big 中描述 $\mathrm{O}$ 作为 $\mathrm{O}\left(\mathrm{N}^2\right)$ ,但选择排序实际上是冒泡排序的两倍。事实上,如果在这两个选项之间做出选择, 选择排序是更好的选择。

计算机代写|数据结构Data Structure代写 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。