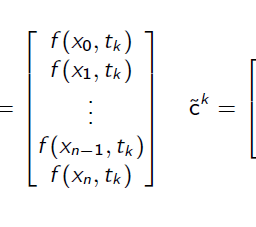数学代写|Basic Concepts in Supervised Machine Learning 数值分析代考
数值分析代写
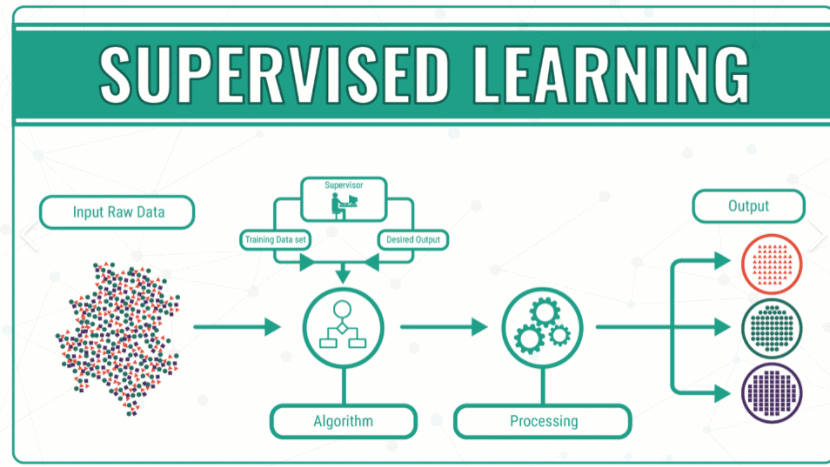
- We wish to learn the relations between some input variable and the output variable
- Denote by $X \in \mathbb{R}^{p}$ inputs, independent variables, features
- Denote by $Y \in \mathbb{R}$ outputs, responses, dependent variables
- Let us say we observe some values of $X$ and $Y$ : we denote the observed values by $x_{i}, y_{i}, i=1, \ldots, N$.
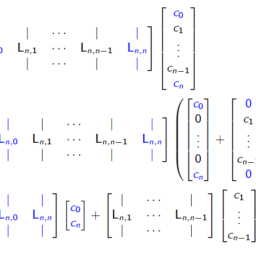
We will write $\mathbf{X}=\left(x_{1}, \ldots, x_{N}\right) \in \mathbb{R}^{N \times p}$ and $\mathbf{y}=\left(y_{1}, \ldots, y_{N}\right) \in \mathbb{R}^{N}$ - We call the set of pairs $\left(x_{i}, y_{i}\right), i=1, \ldots, N$ training data
- The goal is to use the training data to construct a prediction rule.
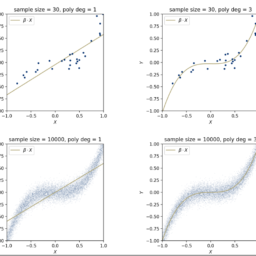
- Now, we find the parameters $\beta$ that minimizes the loss.
- Since the loss is a quadratic function of $\beta$,
$$
\nabla \mathcal{L}(\beta ; f, \mathbf{X}, \mathbf{y})=\mathbf{X}^{T}(\mathbf{y}-\mathbf{X} \beta)
$$
we arrive at the normal equations if we set the gradient zero
$$
\mathbf{X}^{T} \mathbf{X} \beta=\mathbf{X}^{T} \mathbf{y}
$$ - If $\mathbf{X}^{T} \mathbf{X}$ is non-singular (e.g. columns of $\mathbf{X}$ are linearly independent) the that minimizes the loss function is given by
$$
\hat{\beta}=\left(\mathbf{X}^{T} \mathbf{X}\right)^{-1} \mathbf{X}^{T} \mathbf{y}
$$ - In practice, one would take the QR-decomposition of $\mathbf{X}=\mathbf{Q} \mathbf{R}$ then the solution would be
$$
\hat{\beta}=\mathbf{R}^{-1} \mathbf{Q}^{T} \mathbf{y}
$$ - The choice of class of functions $f$ depending on some parameter $\theta$ is crucial
- For example, we can extend the linear model $f(x ; \theta)=x^{T} \theta$ with $\theta=\beta$ by adding suitable set of functions or transformations $h_{k}(x)$
$$
f_{\theta}(x)=\sum_{k=1}^{K} h_{k}(x) \theta_{k}
$$ - $h_{k}(x)$ are for example polynomials like $x_{1}^{2}, x_{1} x_{2}$ or other elemntary functions $\sin \left(x_{2}\right)$, etc.
- If a $h_{k}$ is non-linear, then $f_{\theta}$ is also non-linear in the input variable $x$, whereas it is linear in the parameters $\theta$.
数值分析代考
- 我们希望学习一些输入变量和输出变量之间的关系
- 用 $X \in \mathbb{R}^{p}$ 表示输入、自变量、特征
- 用 $Y \in \mathbb{R}$ 表示输出、响应、因变量
- 假设我们观察到 $X$ 和 $Y$ 的一些值:我们用 $x_{i}, y_{i}, i=1, \ldots, N$ 表示观察到的值。
我们将写 $\mathbf{X}=\left(x_{1}, \ldots, x_{N}\right) \in \mathbb{R}^{N \times p}$ 和 $\mathbf{y} =\left(y_{1}, \ldots, y_{N}\right) \in \mathbb{R}^{N}$ - 我们称这组对 $\left(x_{i}, y_{i}\right), i=1, \ldots, N$ 训练数据
- 目标是使用训练数据构建预测规则。
- 现在,我们找到最小化损失的参数$\beta$。
- 由于损失是$\beta$的二次函数,
$$
\nabla \mathcal{L}(\beta ; f, \mathbf{X}, \mathbf{y})=\mathbf{X}^{T}(\mathbf{y}-\mathbf{X} \beta)
$$
如果我们将梯度设置为零,我们就会得到正规方程
$$
\mathbf{X}^{T} \mathbf{X} \beta=\mathbf{X}^{T} \mathbf{y}
$$ - 如果 $\mathbf{X}^{T} \mathbf{X}$ 是非奇异的(例如 $\mathbf{X}$ 的列是线性独立的),则最小化损失函数由下式给出
$$
\hat{\beta}=\left(\mathbf{X}^{T} \mathbf{X}\right)^{-1} \mathbf{X}^{T} \mathbf{y}
$$ - 在实践中,我们会采用 $\mathbf{X}=\mathbf{Q} \mathbf{R}$ 的 QR 分解,那么解决方案将是
$$
\hat{\beta}=\mathbf{R}^{-1} \mathbf{Q}^{T} \mathbf{y}
$$ - 根据某些参数 $\theta$ 选择函数类 $f$ 至关重要
- 例如,我们可以通过添加合适的函数集或变换 $h_{k}(x )$
$$
f_{\theta}(x)=\sum_{k=1}^{K} h_{k}(x) \theta_{k}
$$ - $h_{k}(x)$ 是例如多项式,如 $x_{1}^{2}、x_{1} x_{2}$ 或其他基本函数 $\sin \left(x_{2}\right )$ 等。
- 如果$h_{k}$ 是非线性的,那么$f_{\theta}$ 在输入变量$x$ 中也是非线性的,而在参数$\theta$ 中是线性的

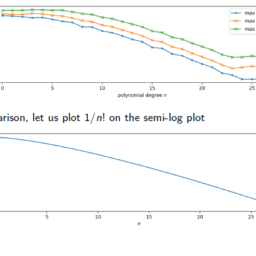
数学代写| Chebyshev polynomials 数值分析代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
时间序列分析代写
统计作业代写
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程