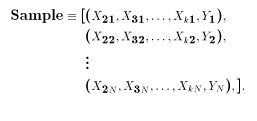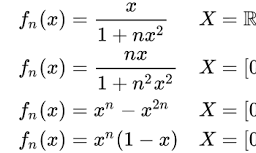如果你也在 怎样代写统计Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计Statistics是数学的一个分支,涉及到矢量空间和线性映射。它包括对线、面和子空间的研究,也涉及所有向量空间的一般属性。
统计学Statistics是一门关于发展和研究收集、分析、解释和展示经验数据的方法的科学。统计Statistics是一个高度跨学科的领域;统计Statistics的研究几乎适用于所有的科学领域,各科学领域的研究问题促使新的统计方法和理论的发展。在开发方法和研究支撑这些方法的理论时,统计学家利用了各种数学和计算工具。
统计Statistics领域的两个基本概念是不确定性和突变。我们在科学(或更广泛的生活)中遇到的许多情况,其结果是不确定的。在某些情况下,不确定性是因为有关的结果尚未确定(例如,我们可能不知道明天是否会下雨),而在其他情况下,不确定性是因为虽然结果已经确定,但我们并不知道(例如,我们可能不知道我们是否通过了某项考试)。
my-assignmentexpert™ 统计Statistics作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计Statistics作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在统计Statistics代写方面经验极为丰富,各种统计Statistics相关的作业也就用不着 说。
我们提供的统计Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Date Analysis数据分析
- Actuarial Science 精算科学
- Bayesian Statistics 贝叶斯统计
- Generalized Linear Model 广义线性模型
- Macroeconomic statistics 宏观统计学
- Microeconomic statistics 微观统计学
- Logistic regression 逻辑回归
- linear regression 线性回归
统计作业代写Statistics代考|The mean has a couple of interesting features
not always the best, but the most common measure is the arithmetic mean, ${ }^{6}$ which is computed using the formulas in Equation 2.1.
$$
\mathrm{E}[\mathrm{X}]=\mu=\frac{\sum X_{i}}{N} \text { (population) or } \bar{x}=\frac{\sum x_{i}}{n} \text { (sample) }
$$
The term on the left-hand side of the first equation, $E[X]$, is a symbolic way of expressing the expected value of variable $X$, which is often used to represent the mean. We could also list this term as $E[$ weight in ounces], but, as long as it’s clear that $X=$ weight in ounces, using $E[X]$ is satisfactory. The Greek letter $\mu$ represents the population mean, whereas $\bar{x}$ in the second part of the equation is the sample mean. The formula for computing the mean is simple. Add all the values of the variable and divide the sum by the number of observations. The cumbersome symbol that looks like an overgrown $E$ in the numerator of Equation $2.1$ is the summation sign; it tells us to add whatever is next to it. The symbol $X_{i}$ or $x_{i} \mathrm{~ s i g n i f i e s ~ s p e c i f i c ~ v a l u e s ~ o f ~ t h e}$ observation. The letter $N$ or $n$ is the number of observations. This may be repobservation. The letter $N$ or $n$ is the number of observations. This may be represented as $i \ldots n$. If $n=5$, then five individual observations are in the sample. letters represent sample values. $E[X]=\bar{x}$ implies that the sample mean is designed to estimate the population expected value or the population mean. Here’s a simple example. Our Siberian Husky, Steppenwolf, sires a litter of puppies. We weigh them and record the following: [48, 52, 58, 62, 70]. The sum of this set is $[48+52+58+62+70]=290$, with a sample mean of $290 / 5=58$ ounces. The mean is also called the center of gravity. Suppose we have a plank of wood that is of uniform weight across its span. We order the puppies from lightest to heaviest-trying to space them out proportional to their weights-and place them on the plank of wood. The mean is the point of balance, or the point at which we would place a fulcrum underneath the plank to balance the puppies.
The mean has a couple of interesting features:
- It is measured in the same units as the observations. If the observations are not all measured in the same unit (e.g., some puppies’ weights are in grams, others in ounces), then the mean is not interpretable.
- The mean provides a suitable measure of central tendency if the variable is measured continuously and is normally distributed.
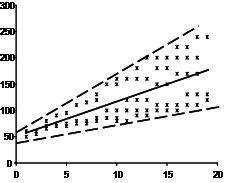
统计作业代写Statistics代考|distribution of annual income
Simulated right-skewed distribution of annual income.
a variable that has a long right tail using the natural logarithm results in a normal distribution. The square root or cube root may also work to normalize a right-skewed distribution. We’ll examine some examples in Chapter $11 .$
Second, some measures of central tendency are more appropriate than the mean when a variable is not normally distributed or includes extreme values. For example, the median, which is the middle value of a distribution, is not as affected as the mean by extreme values and is thus a robust statistic. ${ }^{10}$ To determine the median, order the values of the variable from lowest to highest. If the number of observations is odd, choose the middle value; if it’s even, take the average of the middle two values. You might recall that the median designates the 50 th percentile of a distribution. For example, imagine two puppy weight variables, one that follows a normal distribution (or something close to it) and another that has an extreme value:
Litter 1: $[40,45,50,55,60,65,70]$
Litter 2: $[40,45,49,56,60,66,175]$
Litter 1 has a mean of 55 and a median of 55 , so the estimate of its central value is the same regardless of which measure is used. In contrast, litter 2 has

统计作业代写STATISTICS代考|THE MEAN HAS A COUPLE OF INTERESTING FEATURES
并不总是最好的,但最常见的衡量标准是算术平均值,6使用公式 2.1 中的公式计算得出。
和[X]=μ=∑X一世ñ (人口)或 X¯=∑X一世n (样本)
第一个等式左边的项,和[X], 是表示变量期望值的符号方式X,通常用于表示均值。我们也可以将此术语列为和[以盎司为单位的重量],但是,只要很清楚X=以盎司为单位的重量,使用和[X]是令人满意的。希腊字母μ代表总体平均值,而X¯等式的第二部分是样本均值。计算平均值的公式很简单。将变量的所有值相加,然后将总和除以观察数。看起来像杂草丛生的笨重符号和在方程的分子中2.1是求和符号;它告诉我们添加它旁边的任何内容。符号X一世要么X一世 s一世Gn一世F一世和s sp和C一世F一世C v一种一世你和s ○F 吨H和观察。信ñ要么n是观察次数。这可能是重新观察。信ñ要么n是观察次数。这可以表示为一世…n. 如果n=5,则样本中有五个单独的观察值。字母代表样本值。和[X]=X¯意味着样本均值旨在估计总体预期值或总体均值。这是一个简单的例子。我们的西伯利亚雪橇犬 Steppenwolf 育有一窝小狗。我们对它们进行称重并记录以下内容:[48, 52, 58, 62, 70]。这组的总和是[48+52+58+62+70]=290, 样本均值为290/5=58盎司。平均值也称为重心。假设我们有一块在其跨度上重量均匀的木板。我们将幼犬从最轻到最重排序——试图按照它们的重量将它们分开——然后把它们放在木板上。平均值是平衡点,或者我们将在木板下方放置一个支点以平衡幼犬的点。
均值有几个有趣的特征:
- 它的测量单位与观测值相同。如果观察结果并非全部以相同的单位测量(例如,一些幼犬的体重以克为单位,另一些以盎司为单位),则平均值无法解释。
- 如果变量是连续测量的并且是正态分布的,则平均值提供了一种合适的集中趋势度量。
统计作业代写STATISTICS代考|DISTRIBUTION OF ANNUAL INCOME
模拟的年收入右偏分布。
使用自然对数的具有长右尾的变量会导致正态分布。平方根或立方根也可以用于标准化右偏分布。我们将在本章中研究一些例子11.
其次,当变量不是正态分布或包含极值时,一些集中趋势度量比平均值更合适。例如,中位数是分布的中间值,它不像平均值那样受极值的影响,因此是一个稳健的统计量。10要确定中位数,请将变量的值从最低到最高排序。如果观测数为奇数,则选择中间值;如果是偶数,取中间两个值的平均值。您可能还记得,中位数表示分布的第 50 个百分位。例如,假设有两个小狗体重变量,一个服从正态分布(或接近正态分布),另一个具有极值:
第 1 窝:[40,45,50,55,60,65,70]
垃圾2:[40,45,49,56,60,66,175]
Litter 1 的平均值为 55 ,中位数为 55 ,因此无论使用哪种度量,其中心值的估计值都是相同的。相比之下,垃圾 2 有

统计作业代写Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
matlab代写
MATLAB是一个编程和数值计算平台,被数百万工程师和科学家用来分析数据、开发算法和创建模型。
MATLAB is a programming and numeric computing platform used by millions of engineers and scientists to analyze data, develop algorithms, and create models.
统计代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
统计作业代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
my-assignmentexpert™这边统计代写的质量怎么样?保不保分?靠不靠谱? 一般能写到多少分?
各国各学校的学术标准都有所差异,即使是统计作业,给分也存在一定的主观性因素,有时Teacher和TA的改分并不能够做到完全公正,所有的作业分数都存在一定的运气成分,TA对于步骤把控的严格程度可能和给分的TA今天的心情以及他的性格正相关。一般情况下,MY-ASSIGNMENTEXPERT™出品的作业平均正确率在93%以上。
我在MY-ASSIGNMENTEXPERT™这里购买了代写服务,然后最后这门课的成绩挂了怎么办?
若是因为各种因素结合导致在此购买的统计作业的成绩未达到事先指定的标准,MY-ASSIGNMENTEXPERT™承诺免费重写/修改,并且无条件退款。
最快什么时候写完? 很急的任务可以做吗?
最急的统计论文,可在24小时以内完成,加急的论文价格会比普通的订单稍贵,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计quiz和统计exam代考,在写手档期ok的情况下,可以在下单之后一小时之内进行,不过不提倡这样临时找人,因为加急的quiz和exam代考价格会比普通的订单贵更重要的是可能找不到人,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计assignment,在写手档期ok的情况下,可以在下单之后三小时之内完成,价格在一般的assignment基础上收一个加急费用,如果一份assignment发下来不确定自己能不能完成也能提前和我们联系,报价是不收取任何费用的,如果后续有需要,也方便我们安排写手档期。