如果你也在 怎样代写假设检验Hypothesis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。假设检验Hypothesis是假设检验是统计学中的一种行为,分析者据此检验有关人口参数的假设。分析师采用的方法取决于所用数据的性质和分析的原因。假设检验是通过使用样本数据来评估假设的合理性。
统计假设检验是一种统计推断方法,用于决定手头的数据是否充分支持某一特定假设。
空白假设的早期选择
Paul Meehl认为,无效假设的选择在认识论上的重要性基本上没有得到承认。当无效假设是由理论预测的,一个更精确的实验将是对基础理论的更严格的检验。当无效假设默认为 “无差异 “或 “无影响 “时,一个更精确的实验是对促使进行实验的理论的一个较不严厉的检验。
1778年:皮埃尔-拉普拉斯比较了欧洲多个城市的男孩和女孩的出生率。他说 “很自然地得出结论,这些可能性几乎处于相同的比例”。因此,拉普拉斯的无效假设是,鉴于 “传统智慧”,男孩和女孩的出生率应该是相等的 。
1900: 卡尔-皮尔逊开发了卡方检验,以确定 “给定形式的频率曲线是否能有效地描述从特定人群中抽取的样本”。因此,无效假设是,一个群体是由理论预测的某种分布来描述的。他以韦尔登掷骰子数据中5和6的数量为例 。
1904: 卡尔-皮尔逊提出了 “或然性 “的概念,以确定结果是否独立于某个特定的分类因素。这里的无效假设是默认两件事情是不相关的(例如,疤痕的形成和天花的死亡率)。[16] 这种情况下的无效假设不再是理论或传统智慧的预测,而是导致费雪和其他人否定使用 “反概率 “的冷漠原则。
my-assignmentexpert™ 假设检验Hypothesis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的假设检验Hypothesis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此假设检验Hypothesis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在假设检验Hypothesis作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在假设检验Hypothesis代写方面经验极为丰富,各种假设检验HypothesisProcess相关的作业也就用不着 说。
我们提供的假设检验Hypothesis及其相关学科的代写,服务范围广, 其中包括但不限于:
- 时间序列分析Time-Series Analysis
- 马尔科夫过程 Markov process
- 随机最优控制stochastic optimal control
- 粒子滤波 Particle Filter
- 采样理论 sampling theory
统计代写| 假设检验作业代写Hypothesis testing代考|Power and Sample Size Analysis
Statistical power is the opposite of Type II errors, both mathematically $(1-\beta)$ and conceptually. Power is the ability of the test to detect an effect that exists in the population. In other words, the test correctly rejects a false null hypothesis.
For example, if your study has $80 \%$ power, it has an $80 \%$ chance of detecting an effect that exists. Let this point be a reminder that when you work with samples, nothing is guaranteed! When an effect exists in the population, your study might not detect it because you are working with a sample. Samples contain sample error, which can occasionally cause a random sample to misrepresent the population.
$80 \%$ power is a standard benchmark for studies. However, you’ll need to consider standards for your field or industry.
As you learned in the previous sections, while various factors affect power, researchers have the greatest control over sample size.
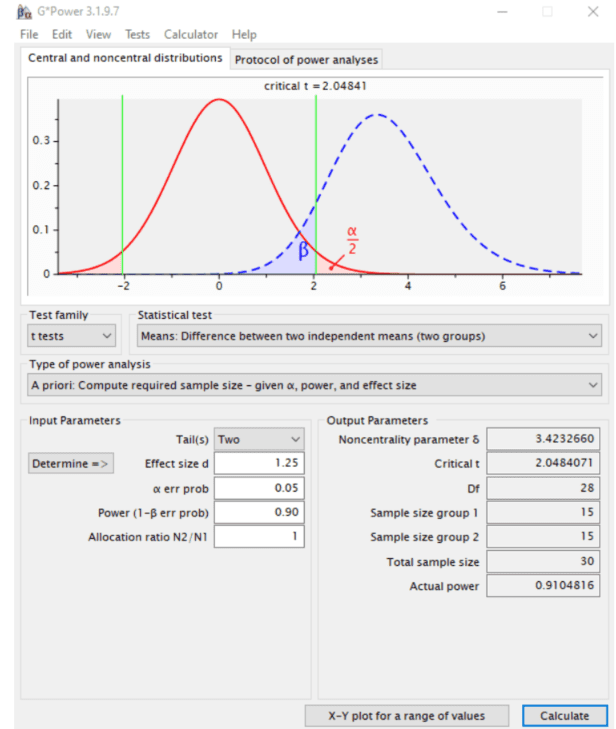
Determining a good sample size for a study is always an important issue. After all, using the wrong sample size can doom your study from the start. Fortunately, power analysis can find the answer for you. Power analysis combines statistical analysis, subject-area knowledge, and your requirements to help you derive the optimal sample size.
As you’ll see in this section, both under-powered and over-powered studies are problematic. Let’s learn how to find the right sample size for your study!
Before data collection and hypothesis testing begin, you must do a lot of preplanning. This planning includes identifying the data you will gather, how you will collect it, and how you will measure it, among many other details. A crucial part of the planning is determining how much data you need to collect. I’ll show you how to estimate the sample size for your study.
Before we get to estimating sample size requirements, let’s review the factors that influence statistical significance. This process will help you see the value of formally going through a power and sample size analysis rather than guessing.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|Low Power Tests Exaggerate Effect Sizes
I’m going to end this chapter with an advanced topic about statistical power. The previous sections of this chapter have shown you that a study with low power is unlikely to detect an effect when it exists. However, there is an additional danger to consider with low powered studies.
Clearly, a high-powered study is a good thing just for being able to identify these effects. Low power reduces your chances of discovering real findings. However, many analysts don’t realize that low power also tends to exaggerate the effect size when they detect effects.
In this section, I show how this unexpected relationship between power and exaggerated effect sizes exists. I’ll also tie it to other issues, such as the bias of effects published in journals and other matters about statistical power. I think this topic will be eye-opening and thought provoking! As always, I’ll use many graphs rather than equations.
Hypothetical Study Scenario
To illustrate how this effect size inflation works, I’ll simulate a study and conduct it many times at three power levels.
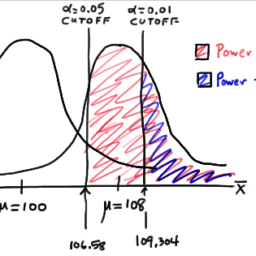
Imagine that we’re studying a fictitious medication that promises to increase your intelligence (IQ). Our experiment has two groups-a control group that doesn’t take the pill and the treatment group that does. Then, each group takes the same IQ test and we compare the results. The effect size is the difference between group means.
Because we’re simulating these studies, we can control the effect size and other properties of the population. I’ll set the effect size at 10 IQ points and define the two populations as follows:
- Control group: Normal distribution with a mean of 100 and a standard deviation of 15 .
- Treatment group: Normal distribution with a mean of 110 and a standard deviation of 15 .
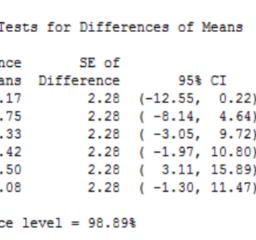
I calculated the sample sizes I need to produce statistical power of $0.3$, $0.55$, and 0.8. The first two values represent low power studies, while the third value is a standard target value. The output below shows the power analysis results.
假设检验代写
统计代写| 假设检验作业代写HYPOTHESIS TESTING代考|POWER AND SAMPLE SIZE ANALYSIS
统计功效与 II 型错误相反,无论是在数学上(1−b)和概念上。功效是检验检测总体中存在的效应的能力。换句话说,测试正确地拒绝了错误的零假设。
例如,如果您的研究有80%力量,它有一个80%检测到存在的影响的机会。让这一点提醒您,当您使用样品时,没有任何保证!当总体中存在影响时,您的研究可能无法检测到它,因为您正在处理样本。样本包含样本错误,这有时会导致随机样本歪曲总体。
80%功率是研究的标准基准。但是,您需要考虑您所在领域或行业的标准。
正如您在前几节中所了解的,虽然各种因素会影响功效,但研究人员对样本量的控制最大。
确定研究的良好样本量始终是一个重要问题。毕竟,使用错误的样本量可能会从一开始就毁掉你的研究。幸运的是,功率分析可以为您找到答案。功效分析结合了统计分析、学科领域知识和您的要求,可帮助您得出最佳样本量。
正如您将在本节中看到的那样,功率不足和功率过高的研究都是有问题的。让我们学习如何为您的研究找到合适的样本量!
在数据收集和假设检验开始之前,您必须做很多预先计划。该计划包括确定您将收集的数据、您将如何收集以及如何衡量它,以及许多其他细节。计划的一个关键部分是确定您需要收集多少数据。我将向您展示如何估计您的研究的样本量。
在我们开始估计样本量要求之前,让我们回顾一下影响统计显着性的因素。此过程将帮助您了解正式通过功效和样本量分析而不是猜测的价值。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|LOW POWER TESTS EXAGGERATE EFFECT SIZES
我将以一个关于统计功效的高级主题结束本章。本章前面的部分已经向您展示了低功效研究不太可能检测到存在的影响。然而,低功率研究还有一个额外的危险需要考虑。
显然,高强度的研究只是为了能够识别这些影响是一件好事。低功耗会降低您发现真实发现的机会。然而,许多分析人员没有意识到,当他们检测到效应时,低功率也往往会夸大效应大小。
在本节中,我将展示权力和夸大效应之间的这种意想不到的关系是如何存在的。我还将把它与其他问题联系起来,例如发表在期刊上的效果偏差和其他关于统计功效的问题。我认为这个话题会令人大开眼界和发人深省!与往常一样,我将使用许多图表而不是方程式。
假设的研究场景
为了说明这种效应量膨胀的工作原理,我将模拟一项研究,并在三个功率水平下进行多次。
想象一下,我们正在研究一种有望提高你智力的虚构药物一世问. 我们的实验有两组——不吃药的对照组和吃药的治疗组。然后,每组进行相同的智商测试,我们比较结果。效应大小是组均值之间的差异。
因为我们正在模拟这些研究,所以我们可以控制人群的效应大小和其他属性。我将影响大小设置为 10 个 IQ 点,并将两个群体定义如下:
- 对照组:正态分布,平均值为 100,标准差为 15。
- 治疗组:正态分布,平均值为 110,标准差为 15。
我计算了产生统计功效所需的样本量0.3,0.55, 和 0.8。前两个值代表低功效研究,而第三个值是标准目标值。下面的输出显示了功率分析结果。

统计代写| 假设检验作业代写Hypothesis testing代考|Population Parameters vs. Sample Statistics 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析(Numerical Analysis),又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。