如果你也在 怎样代写图像压缩image compression这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。图像压缩image compression是一种应用于数字图像的数据压缩,以减少其存储或传输的成本。算法可以利用视觉感知和图像数据的统计特性,与用于其他数字数据的通用数据压缩方法相比,提供更优越的结果。
图像压缩image compression可以是有损或无损的。无损压缩是存档的首选,通常用于医学成像、技术图纸、剪贴画或漫画。有损压缩方法,特别是在低比特率下使用时,会引入压缩伪影。有损方法特别适用于自然图像,如照片,在这种应用中,为了实现比特率的大幅降低,可以接受微小的(有时难以察觉的)保真度损失。产生可忽略的差异的有损压缩可以被称为视觉上的无损。
my-assignmentexpert™ 图像压缩image compression作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的图像压缩image compression作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此图像压缩image compression作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图像压缩image compression代写方面经验极为丰富,各种图像压缩image compression相关的作业也就用不着 说。
我们提供的图像压缩image compression及其相关学科的代写,服务范围广, 其中包括但不限于:

数学代写|图像压缩代写image compression代考|Stereo Video
The stereo concept is related to the creation of depth illusion in the observed images. Such a functionality is provided by stereoscopic systems which exploit the binocular vision, specifically by separately presenting two slightly different images to the left and right eyes of the viewer. The human brain combines the two received images to give the perception of $3 \mathrm{D}$ depth in the observed scene. The stereo video is the conventional 3D representation format for stereoscopic systems [99]. This format simply uses two video views, which is the minimum number of views required to provide depth perception. Because of this, stereo video is also the simplest solution for 3D representation.
Typically, the acquisition of stereo video requires two capturing sensors installed in one or two independent video cameras. The two video views present significant similarities, since they represent the same scene captured from slightly different viewpoints. The distance between the left and right camera sensors (baseline distance) often corresponds to the average distance between the human eyes.
Each view of the stereo video can be separately encoded and transmitted, in a process known as simulcast coding. Although it provides backward compatibility with existing compression algorithms, this approach does not exploit redundant information present between views, requiring approximately double the rate of a single-view video. To improve the compression of stereo video, extensions to the state-of-the-art coding algorithms, such as H.264/AVC and HEVC, have been deployed. These stereo extensions introduce inter-view prediction methods that exploit the redundancy between views. Typically, the stereo video codecs independently encode the first view using the traditional single-view coding techniques, while the second view is dependently encoded using the same coding tools plus inter-view prediction methods that exploit similar information from the first view. To further improve the compression of stereo video, an uneven bitrate allocation between the two views can be also performed. This procedure is motivated by the binocular suppression theory $[100]$, which states that the stereo vision quality is dominated by the quality of the higher fidelity view.
数学代写|图像压缩代写image compression代考|Multiview Video
While the stereo video only uses two views, the multiview video format involves a larger number of views representing the same 3D scene. The use of multiple views is important to provide more interactive applications, that allow to change the observation point of the scene. Typically, the multiview video is captured using an array of cameras, that may be configured using different arrangements and densities 107.
The deployment of a multi-camera system is a challenging task, mainly due to the difficulties related to the synchronisation of the cameras and the handling of large amounts of data, specially in real time applications. However, for the case of static scenes, this capturing process can be highly simplified. Instead of using multiple cameras, a single camera can be used to record the same scene from several positions at different temporal instants, given that the lighting conditions do not change. Possible solutions include the use of robots to change the camera position or turn tables to rotate the scene.
Multiview video systems tend to produce huge amounts of data that need to be processed and transmitted. The processing stage usually involves the correction of some discrepancies and artefacts that exist between the captured views, namely by using algorithms for geometrical calibration, colour correction or to adjust lens distortion 75. These systems often require the use of advanced computer clusters, mainly for the case of highly dense camera arrangements.
Due to the increased amount of data associated to the multiple views, it is crucial to use efficient compression algorithms for the multiview video format. The state-ofthe-art coding approaches exploit the inter-view dependencies across several views, in addition to the spatial and temporal redundancies. The Multiview Video Coding (MVC) 12,36,69 is an amendment to the H.264/AVC standard for multiview video coding, that enables efficient inter-view prediction by adding decoded frames of other views to the reference picture list. A multiview extension for the HEVC standard has been also standardised with the designation of MV-HEVC 81,104. Although the multiview extensions of current state-of-the-art standards provide significant coding gains, the complex dependencies associated to the temporal and inter-view prediction limit the random access capabilities and increase the system delay, memory requirements and computational complexity of the encoder.
For displaying multiview video contents, autostereoscopic displays based on multiple views, typically eight or sixteen views, are used. These displays do not require the use of glasses, since they perform spatial multiplexing of distinct views into each eye using a light-directing mechanism. By using many views, the autostereoscopic displays may provide free navigation within some limited spatial range as well as motion parallax effect.
The autostereoscopic displays can be classified as active, when they track the head position of the user, or passive, when a large number of views is displayed simultaneously based on spatial multiplexing 44. Two technologies are commonly used by autostereoscopic displays, namely the parallax barrier, based on slits in opaque sheet, and the lenticular screen, which uses thin cylindrical lenses 44. The main drawback of these displaying technologies is the blurring effect caused due to pixel crosstalk.
数学代写|图像压缩代写IMAGE COMPRESSION代考|Multiview Video +Depth
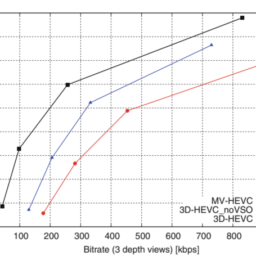
One of the main problems of the multiview video is the large number of views that need to be encoded and transmitted. Despite the significant RD gains provided by the multiview extensions for the state-of-the-art video coding standards, the total bitrate tends to increase linearly with the number of views. An alternative solution for $3 \mathrm{D}$ video representation makes use of the geometry information of the scene to reduce the number of required views $[79,98]$. The idea is to transmit fewer texture views and render the missing ones, using the well-known Depth Image Based Rendering (DIBR) algorithm $[32,42]$. This algorithm makes use of the geometry information, usually provided by the depth maps, to warp the few transmitted texture views to the desired virtual camera positions, and thus generate the virtual texture views. This kind of 3D video representation, that combines the multiview video with depth information, is known as Multiview Video +Depth format (MVD).
图像压缩代写
数学代写|图像压缩代写IMAGE COMPRESSION代考|STEREO VIDEO
立体概念与在观察到的图像中创建深度错觉有关。这种功能由利用双目视觉的立体系统提供,特别是通过分别向观看者的左眼和右眼呈现两个稍微不同的图像。人脑将接收到的两幅图像结合起来,以感知3D观察场景的深度。立体视频是立体系统的传统 3D 表示格式99. 此格式仅使用两个视频视图,这是提供深度感知所需的最小视图数。正因为如此,立体视频也是 3D 表示最简单的解决方案。
通常,立体视频的采集需要安装在一个或两个独立摄像机中的两个捕捉传感器。这两个视频视图呈现出显着的相似性,因为它们代表了从稍微不同的视点捕获的相同场景。左右摄像头传感器之间的距离b一种s和l一世n和d一世s吨一种nC和通常对应于人眼之间的平均距离。
立体视频的每个视图都可以在称为联播编码的过程中单独编码和传输。尽管它提供了与现有压缩算法的向后兼容性,但这种方法并没有利用视图之间存在的冗余信息,需要大约是单视图视频的两倍。为了改进立体视频的压缩,已经部署了对最先进编码算法的扩展,例如 H.264/AVC 和 HEVC。这些立体扩展引入了利用视图之间冗余的视图间预测方法。通常,立体视频编解码器使用传统的单视图编码技术对第一个视图进行独立编码,而第二个视图使用相同的编码工具以及利用来自第一个视图的相似信息的视图间预测方法进行独立编码。为了进一步改进立体视频的压缩,还可以在两个视图之间执行不均匀的比特率分配。这个过程是由双目抑制理论推动的[100],这表明立体视觉质量由更高保真度视图的质量决定。
数学代写|图像压缩代写IMAGE COMPRESSION代考|MULTIVIEW VIDEO
虽然立体视频仅使用两个视图,但多视图视频格式涉及表示相同 3D 场景的大量视图。使用多个视图对于提供更多交互式应用程序非常重要,这些应用程序允许更改场景的观察点。通常,使用可以使用不同布置和密度107配置的相机阵列来捕获多视图视频。
多摄像头系统的部署是一项具有挑战性的任务,主要是由于与摄像头同步和处理大量数据相关的困难,特别是在实时应用中。然而,对于静态场景的情况,这个捕捉过程可以高度简化。假设照明条件不变,则可以使用单个摄像机在不同时间瞬间从多个位置记录同一场景,而不是使用多个摄像机。可能的解决方案包括使用机器人来改变相机位置或使用转台来旋转场景。
多视图视频系统往往会产生大量需要处理和传输的数据。处理阶段通常涉及校正捕获视图之间存在的一些差异和伪影,即通过使用几何校准算法、颜色校正或调整镜头畸变 75。这些系统通常需要使用先进的计算机集群,主要用于高密度摄像机布置的情况。
由于与多视图相关的数据量增加,因此对多视图视频格式使用有效的压缩算法至关重要。除了空间和时间冗余之外,最先进的编码方法还利用多个视图之间的视图间依赖关系。多视图视频编码米在C12,36,69 是对多视图视频编码的 H.264/AVC 标准的修订,它通过将其他视图的解码帧添加到参考图片列表来实现高效的视图间预测。HEVC 标准的多视图扩展也已标准化,命名为 MV-HEVC 81,104。尽管当前最先进标准的多视图扩展提供了显着的编码增益,但与时间和视图间预测相关的复杂依赖性限制了随机访问能力并增加了编码器的系统延迟、内存需求和计算复杂度.
为了显示多视图视频内容,使用基于多视图的自动立体显示器,通常是八个或十六个视图。这些显示器不需要使用眼镜,因为它们使用光引导机制将不同的视图空间复用到每只眼睛中。通过使用许多视图,自动立体显示器可以在一些有限的空间范围内提供自由导航以及运动视差效应。
自动立体显示器可分为主动式(当它们跟踪用户的头部位置时)或被动式(当基于空间复用44同时显示大量视图时)。自动立体显示器通常使用两种技术,即视差屏障,基于不透明片中的狭缝,以及使用薄柱面透镜44的柱状屏幕。这些显示技术的主要缺点是由于像素串扰引起的模糊效果。
数学代写|图像压缩代写IMAGE COMPRESSION代考|MULTIVIEW VIDEO +DEPTH
多视图视频的主要问题之一是需要编码和传输的大量视图。尽管多视图扩展为最先进的视频编码标准提供了显着的 RD 增益,但总比特率倾向于随视图数量线性增加。替代解决方案3D视频表示利用场景的几何信息来减少所需视图的数量[79,98]. 这个想法是使用众所周知的基于深度图像的渲染来传输更少的纹理视图并渲染丢失的视图D一世乙R算法[32,42]. 该算法利用通常由深度图提供的几何信息,将少数传输的纹理视图扭曲到所需的虚拟相机位置,从而生成虚拟纹理视图。这种将多视图视频与深度信息相结合的 3D 视频表示,称为多视图视频 + 深度格式米在D.

数学代写|图像压缩代写image compression代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。