如果你也在 怎样代写时间序列分析time series analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。时间序列分析time series analysis在数学中,是按时间顺序索引(或列出或绘制)的一系列数据点。最常见的是,一个时间序列是在连续的、间隔相等的时间点上的序列。因此,它是一个离散时间数据的序列。时间序列的例子是海洋潮汐的高度、太阳黑子的数量和道琼斯工业平均指数的每日收盘值。
时间序列分析time series analysis时间序列经常通过运行图(这是一个时间线图)来绘制。时间序列被用于统计学、信号处理、模式识别、计量经济学、数学金融、天气预报、地震预测、脑电图、控制工程、天文学、通信工程,以及任何涉及时间性测量的应用科学和工程领域。
my-assignmentexpert™时间序列分析time series analysis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的时间序列分析time series analysis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此时间序列分析time series analysis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在时间序列分析time series analysis代写方面经验极为丰富,各种时间序列分析time series analysis相关的作业也就用不着 说。
我们提供的时间序列分析time series analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
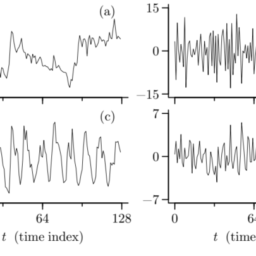
统计代写|时间序列分析作业代写time series analysis代考|Stochastic Processes
Consider the following experiment (see Figure 22): we hook up a resistor to an oscilloscope in such a way that we can examine the voltage variations across the resistor as a function of time. Every time we press a “reset” button on the oscilloscope, it displays the voltage variations for the one-second interval following the reset. Since the voltage variations are presumably caused by such factors as small temperature variations in the resistor, each time we press the reset button, we will observe a different display on the oscilloscope. Owing to the complexity of the factors that influence the display, there is no way that we can use the laws of physics to predict what will appear on the oscilloscope. However, if we repeat this experiment over and over, we soon see that, although we view a different display each time we press the reset button, the displays resemble each other: there is a characteristic “bumpiness” shared by all the displays.
We can model this experiment by considering a large box in which we have placed pictures of all the oscilloscope displays that we could possibly observe. Pushing the reset button corresponds to reaching into the box and choosing “at random” one of the pictures. Loosely speaking, we call the box of all possible pictures together with the mechanism by which we select the pictures a stochastic process. The one particular picture we actually draw out at a given time is called a realization of the stochastic process. The collection of all possible realizations is called the ensemble.
统计代写|时间序列分析作业代写time series analysis代考|Notation
Since it is important to be clear about the type of stochastic process we are discussing, we shall use the following notational conventions throughout this book:
1 $\left{X_{t}\right}$ refers to a real-valued discrete parameter stochastic process whose t th component is $X_{t}$, while
2 ${X(t)}$ refers to a real-valued continuous parameter stochastic process whose component at time t is $X(t)$.
3 When the index set for a stochastic process is not explicitly stated as is the case for both $\left{X_{t}\right}$ and ${X(t)}$, we shall assume that it is the set of all integers Z = {. . . , −2, −1, 0,1, 2, . . .}for a discrete parameter process and the entire real axis R = {t : −∞ < t <∞}for a continuous parameter process. Note that ” t ” is being used in two different ways here: the $t$ in $X_{t}$ is a unitless index referring to the $t$ th element of the process $\left{X_{t}\right}$ , whereas the t in $X(t)$ has physically meaningful units such as seconds or days (hence $X(t)$ is the element occurring at time t of the process ${X(t)}$.
4 On occasion we will need to discuss more than one stochastic process at a time. To distinguish among them, we will either introduce another symbol besides $X$ (such as in $\left{Y_{t}\right}$ or add another index before the time index. For example, {Xj,t} and {Xk,t} refer to the jth and kth discrete parameter processes, while {Xj (t)} and {Xk(t)} refer to two continuous parameter processes. Another way to handle multiple processes is to define a vector whose elements are stochastic processes. This approach leads to what are known as vector-valued stochastic processes or multivariate stochastic processes, which we do not deal with in this book.
5 We reserve the symbol Z for a complex-valued RV whose real and imaginary components are real-valued RVs. With an index added, {Zt} is a complex-valued discrete parameter stochastic process with a tth component formed from, say, the real-valued RVs
X0,t and X1,t; i.e., Zt = X0,t + iX1,t, where idef =√−1 (i.e., i is “equal by definition”to √−1). Likewise, {Z(t)} is a complex-valued continuous parameter stochastic process with a tth component formed from two real-valued RVs, say, X0(t) and X1(t); i.e.,Z(t) = X0(t) + iX1(t).
统计代写|时间序列分析作业代写time series analysis代考|Basic Theory for Stochastic Processes
Let us first consider the real-valued discrete parameter stochastic process $\left{X_{t}\right}$. Since, for $t$ fixed, $X_{t}$ is an RV, it has an associated cumulative probability distribution function (CPDF) given by
$$
F_{t}(a)=\mathbf{P}\left[X_{t} \leq a\right],
$$
where the notation $\mathbf{P}[A]$ indicates the probability that the event $A$ will occur. Because $\left{X_{t}\right}$ is a stochastic process, our primary interest is in the relationships amongst the various RVs that are part of it. These are expressed by various higher-order CPDFs. For example, for any $t_{0}$ and $t_{1}$ in the index set $T$,
$$
F_{t_{0}, t_{1}}\left(a_{0}, a_{1}\right)=\mathbf{P}\left[X_{t_{0}} \leq a_{0}, X_{t_{1}} \leq a_{1}\right]
$$
gives the bivariate CPDF for $X_{t_{0}}$ and $X_{t_{1}}$, where the notation $\mathbf{P}\left[A_{0}, A_{1}\right]$ refers to the probability of the intersection of the events $A_{0}$ and $A_{1}$. More generally, for any integer $N \geq 1$ and any $t_{0}, t_{1}, \ldots, t_{N-1}$ in the index set, we can define the $N$-dimensional CPDF by
$$
F_{t_{0}, t_{1}, \ldots, t_{N-1}}\left(a_{0}, a_{1}, \ldots, a_{N-1}\right)=\mathbf{P}\left[X_{t_{0}} \leq a_{0}, X_{t_{1}} \leq a_{1}, \ldots, X_{t_{N-1}} \leq a_{N-1}\right]
$$
时间序列分析代写
统计代写|时间序列分析作业代写TIME SERIES ANALYSIS代考|STOCHASTIC PROCESSES
考虑以下实验s和和F一世G在r和22:我们将电阻器连接到示波器,以便我们可以检查电阻器两端的电压变化作为时间的函数。每次我们按下示波器上的“复位”按钮时,它都会显示复位后一秒间隔内的电压变化。由于电压变化可能是由电阻器的微小温度变化等因素引起的,因此每次按下复位按钮时,我们都会在示波器上观察到不同的显示。由于影响显示的因素的复杂性,我们无法使用物理定律来预测示波器上会出现什么。然而,如果我们一遍又一遍地重复这个实验,我们很快就会发现,虽然每次按下重置按钮时我们看到的显示不同,但显示彼此相似:
我们可以通过考虑一个大盒子来模拟这个实验,我们在其中放置了我们可能观察到的所有示波器显示的图片。按下重置按钮对应于进入盒子并“随机”选择其中一张图片。粗略地说,我们将所有可能图片的框以及我们选择图片的机制称为随机过程。我们在给定时间实际绘制的一张特定图片称为随机过程的实现。所有可能实现的集合称为集成。
统计代写|时间序列分析作业代写TIME SERIES ANALYSIS代考|NOTATION
由于清楚我们正在讨论的随机过程的类型很重要,因此我们将在本书中使用以下符号约定:
1\left{X_{t}\right}\left{X_{t}\right}指的是一个实值离散参数随机过程,其第 t 个分量是X吨, 而
2X(吨)指实值连续参数随机过程,其在时间 t 的分量为X(吨).
3 当随机过程的指数集没有像两者一样明确说明时\left{X_{t}\right}\left{X_{t}\right}和X(吨),我们假设它是所有整数 Z = { 的集合。. . , -2, -1, 0,1, 2, . . .}对于离散参数过程,整个实轴 R = {t : −∞ < t <∞}对于连续参数过程。请注意,“t”在这里以两种不同的方式使用:吨在X吨是一个无单位索引,指的是吨过程的要素\left{X_{t}\right}\left{X_{t}\right},而 t 在X(吨)具有物理意义的单位,例如秒或天H和nC和$X(吨一世s吨H和和l和米和n吨这CC在rr一世nG一种吨吨一世米和吨这F吨H和pr这C和ss{X吨}.4这n这CC一种s一世这n在和在一世lln和和d吨这d一世sC在ss米这r和吨H一种n这n和s吨这CH一种s吨一世Cpr这C和ss一种吨一种吨一世米和.吨这d一世s吨一世nG在一世sH一种米这nG吨H和米,在和在一世ll和一世吨H和r一世n吨r这d在C和一种n这吨H和rs是米b这lb和s一世d和sX(s在CH一种s一世n\left{Y_{t}\right}$ 或在时间索引之前添加另一个索引。例如,{Xj,t} 和 {Xk,t} 指的是第 j 个和第 k 个离散参数过程,而 {Xj吨} 和 {Xk吨} 指的是两个连续的参数过程。处理多个过程的另一种方法是定义一个向量,其元素是随机过程。这种方法导致了所谓的向量值随机过程或多元随机过程,我们在本书中不涉及。
5 我们为复值 RV 保留符号 Z,其实部和虚部都是实值 RV。添加索引后,{Zt} 是复值离散参数随机过程,其第 t 个分量由实值 RV
X0,t 和 X1,t 形成;即,Zt = X0,t + iX1,t,其中 idef =√−1一世.和.,一世一世s“和q在一种lb是d和F一世n一世吨一世这n”吨这√−1. 同样,{Z吨} 是一个复值连续参数随机过程,其第 t 个分量由两个实值 RV 组成,例如 X0吨和 X1吨; 即,Z吨 = X0吨+ IX1吨.
统计代写|时间序列分析作业代写TIME SERIES ANALYSIS代考|BASIC THEORY FOR STOCHASTIC PROCESSES
让我们首先考虑实值离散参数随机过程\left{X_{t}\right}\left{X_{t}\right}. 因此吨固定的,X吨是一个 RV,它有一个相关的累积概率分布函数C磷DF由
F吨(一种)=磷[X吨≤一种],
符号在哪里磷[一种]表示事件发生的概率一种会发生。因为\left{X_{t}\right}\left{X_{t}\right}是一个随机过程,我们的主要兴趣在于作为其中一部分的各种 RV 之间的关系。这些由各种高阶 CPDF 表示。例如,对于任何吨0和吨1在索引集中吨,
F吨0,吨1(一种0,一种1)=磷[X吨0≤一种0,X吨1≤一种1]
给出二元 CPDFX吨0和X吨1, 其中符号磷[一种0,一种1]指事件相交的概率一种0和一种1. 更一般地,对于任何整数ñ≥1和任何吨0,吨1,…,吨ñ−1在索引集中,我们可以定义ñ-维 CPDF 由
F吨0,吨1,…,吨ñ−1(一种0,一种1,…,一种ñ−1)=磷[X吨0≤一种0,X吨1≤一种1,…,X吨ñ−1≤一种ñ−1]

统计代写|时间序列分析作业代写time series analysis代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。