如果你也在 怎样代写统计计算Statistical Computing这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计计算Statistical Computing是统计学和计算机科学之间的纽带。它意味着通过使用计算方法来实现的统计方法。它是统计学的数学科学所特有的计算科学(或科学计算)的领域。这一领域也在迅速发展,导致人们呼吁应将更广泛的计算概念作为普通统计教育的一部分来教授 。
统计计算Statistical Computing与传统统计学一样,其目标是将原始数据转化为知识,但重点在于计算机密集型的统计方法,例如具有非常大的样本量和非同质数据集的情况 。计算统计 “和 “统计计算 “这两个词经常被交替使用,尽管卡罗-劳罗(国际统计计算协会的前主席)提议作出区分,将 “统计计算 “定义为 “计算机科学在统计学中的应用”,而将 “计算统计 “定义为 “旨在设计在计算机上实现统计方法的算法,包括那些在计算机时代之前无法想象的方法(例如自举法、模拟),以及应对分析上难以解决的问题”。
my-assignmentexpert™统计计算Statistical Computing代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计计算Statistical Computing作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计计算Statistical Computing作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在澳洲代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的澳洲代写服务。我们的专家在统计计算Statistical Computing代写方面经验极为丰富,各种统计计算Statistical Computing相关的作业也就用不着 说。
我们提供的统计计算Statistical Computing及其相关学科的代写,服务范围广, 其中包括但不限于:
澳洲代写|统计计算代写Statistical Computing代写|Flt Analysis for 2024-T4 Fatigue Life Data
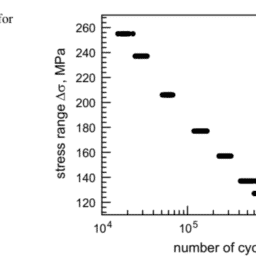
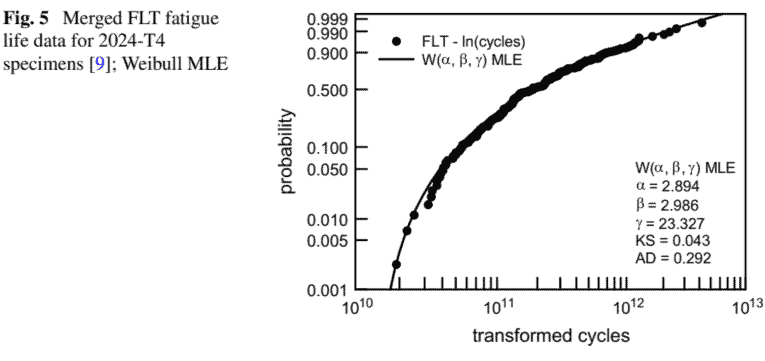
To evaluate the effectiveness of the proposed FLT methodology, the fatigue life data summarized in Table 1 and shown on Fig. 1 is considered. Recall that the FLT is applied to the natural logarithm of the fatigue data; see Eq. (3). The arbitrarily chosen values for $N_{A}$ and $s_{A}$ are 26 and 1 , respectively. The rather large value for $N_{A}$ was chosen to assure that $z_{k, j}$ in Eq. (4) is positive. The 222 FLT data are shown on Fig. 4, where the axes are labeled to be easily read. Each set of data for a given $\Delta \sigma_{k}$ are transformed using FLT. These transformed data are well grouped so that it is reasonable to merge them. Figure 5 shows the entire 222 FLT values merged into a common sample space. The FLT merged data contain approximately 7-10 times more data than those for each given $\Delta \sigma_{k}$. Thus, estimation for the cdf is necessarily more accurate which results in a better characterization of its lower tail. Also, notice that the cycles are transformed using the FLT procedure; they are not actual cycles to failure, i.e., they are not equivalent to the data shown on Fig. 1. The solid line is the maximum likelihood estimation (MLE) for a three-parameter Weibull cdf $\mathrm{W}(\alpha, \beta, \gamma)$, where $\alpha$ is the shape parameter, $\beta$ is the scale parameter, and $\gamma$ is the location parameter. The form of $\mathrm{W}(\alpha, \beta, \gamma)$ is
$$
F(x)=1-\exp \left{-[(x-\gamma) / \beta]^{\alpha}\right}, x \geq \gamma
$$
澳洲代写|统计计算代写Statistical Computing代写|FLT Analysis for ASTM A969 Fatigue Life Data
The second applications of the FLT method is for the ASTM A969 fatigue data. Again, the arbitrarily chosen values for $N_{A}$ and $s_{A}$ are 26 and 1 , respectively. Figure 8 shows the entire 69 FLT values merged into a common sample space. The solid line is the MLE W $(\alpha, \beta, \gamma)$, Eq. (6). The KS and AD goodness of fit test statistics are $0.047$ and $0.524$, respectively. The MLE is acceptable according to the KS test for any significance level $\alpha_{s}$ less than 0.3. For the AD test, however, it is acceptable only for $\alpha_{\mathrm{s}}$ less than $0.2$ because there is some deviation between the data and the MLE in the lower tail. Even so, the FLT data are well represented by the MLE W $(\alpha, \beta, \gamma)$ cdf. The MLE estimated parameters are $\hat{\alpha}=3.057 ; \hat{\beta}=2.964 ;$ and $\hat{\gamma}=23.289$.
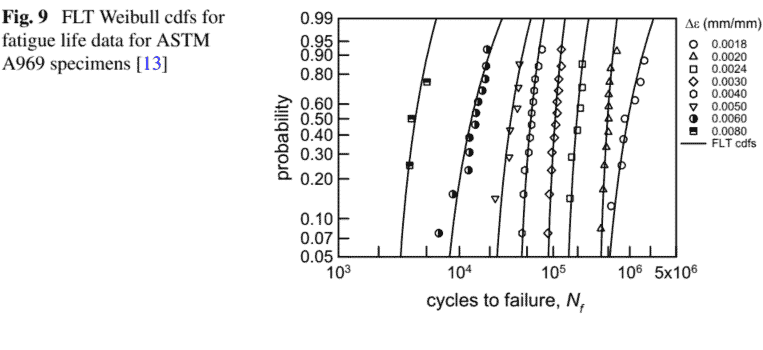
Using Eqs. (7)-(9), Fig. 9 has the ASTM A969 data with the FLT cdfs W $\left(\alpha, \beta_{k}\right.$, $\gamma_{k}$ ). Graphically, the FLT cdfs appear to characterize the data well. In fact, the KS test indicates that all these cdfs are acceptable for any $\alpha_{s}$ less than $0.3$. The AD test, however, implies that the FLT cdfs are marginal, at best. Clearly, the FLT cdfs are not as accurate in the tails. No doubt, larger samples for each $\Delta \varepsilon_{k}$ would help with characterization of the extremes. Using Eq. (10), Fig. 10 is an $\mathrm{S}-\mathrm{N}$ graph, identical to Fig. 2, with the addition of the FLT estimated median, and the FLT estimated $99 \%$ percentile bounds. The $99 \%$ bounds are very tight, and the all the data are within the bounds for each $\Delta \varepsilon_{k}$. They are somewhat jagged because they follow the pattern of the $\mathrm{S}-\mathrm{N}$ data. The analysis is not as crisp as that for the 2024-T4 data; however, there seems to be merit in using the FLT approach for the ASTM A969 fatigue data.
统计计算代写
澳洲代写|统计计算代写STATISTICAL COMPUTING代写|FLT ANALYSIS FOR 2024-T4 FATIGUE LIFE DATA
为了评估所提出的 FLT 方法的有效性,考虑了表 1 中总结并显示在图 1 中的疲劳寿命数据。回想一下 FLT 应用于疲劳数据的自然对数;见方程式。3. 任意选择的值ñ一个和s一个分别是 26 和 1 。相当大的价值ñ一个被选中以确保和ķ,j在等式。4是积极的。222 FLT 数据如图 4 所示,其中轴被标记为易于读取。给定的每组数据Δσķ使用 FLT 进行转换。这些转换后的数据被很好地分组,因此合并它们是合理的。图 5 显示了合并到一个公共样本空间中的全部 222 个 FLT 值。FLT 合并数据包含的数据大约是每个给定数据的 7-10 倍Δσķ. 因此,对 cdf 的估计必然更准确,从而更好地表征其下尾。另外,请注意循环是使用 FLT 过程转换的;它们不是实际的失效周期,即它们不等于图 1 所示的数据。实线是最大似然估计米大号和对于三参数 Weibull cdf在(一个,b,C), 在哪里一个是形状参数,b是尺度参数,并且C是位置参数。的形式在(一个,b,C)是
F(x)=1-\exp \left{-[(x-\gamma) / \beta]^{\alpha}\right}, x \geq \gammaF(x)=1-\exp \left{-[(x-\gamma) / \beta]^{\alpha}\right}, x \geq \gamma
澳洲代写|统计计算代写STATISTICAL COMPUTING代写|FLT ANALYSIS FOR ASTM A969 FATIGUE LIFE DATA
FLT 方法的第二个应用是用于 ASTM A969 疲劳数据。同样,任意选择的值ñ一个和s一个分别是 26 和 1 。图 8 显示了合并到一个公共样本空间中的全部 69 个 FLT 值。实线是 MLE W(一个,b,C), 方程。6. KS 和 AD 拟合优度检验统计量为0.047和0.524, 分别。根据任何显着性水平的 KS 检验,MLE 是可以接受的一个s小于 0.3。但是,对于 AD 测试,它仅适用于一个s少于0.2因为下尾的数据和 MLE 之间存在一些偏差。即便如此,FLT 数据也很好地由 MLE W 表示(一个,b,C)cdf。MLE 估计参数为一个^=3.057;b^=2.964;和C^=23.289.
使用方程式。7-9, 图 9 具有 ASTM A969 数据与 FLT cdfs W(一个,bķ, Cķ)。从图形上看,FLT cdfs 似乎很好地表征了数据。事实上,KS 测试表明所有这些 cdf 对任何一个s少于0.3. 然而,AD 测试意味着 FLT cdfs 充其量是边际的。显然,FLT cdfs 在尾部并不准确。毫无疑问,每个样本都有更大的样本Δeķ将有助于表征极端情况。使用方程式。10, 图 10 是一个小号−ñ图,与图 2 相同,增加了 FLT 估计中位数和 FLT 估计99%百分位界限。这99%界限非常严格,所有数据都在每个界限内Δeķ. 它们有些参差不齐,因为它们遵循小号−ñ数据。分析不如 2024-T4 数据清晰;然而,对 ASTM A969 疲劳数据使用 FLT 方法似乎是有好处的。

澳洲代写|统计计算代写STATISTICAL COMPUTING代写 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。