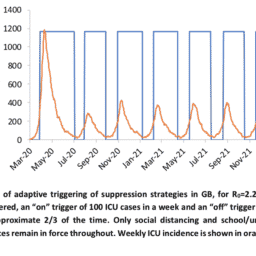
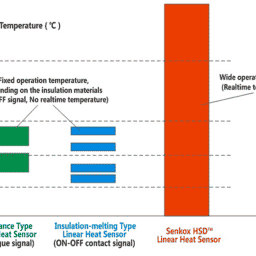
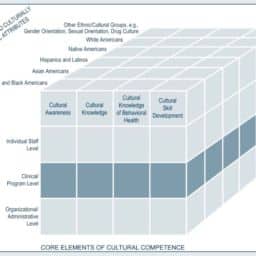
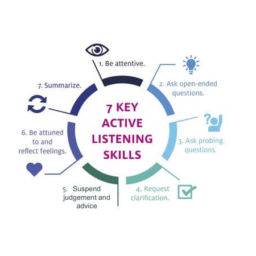
如果你也在 怎样代写假设检验Hypothesis STA2302这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。假设检验Hypothesis是假设检验是统计学中的一种行为,分析者据此检验有关人口参数的假设。分析师采用的方法取决于所用数据的性质和分析的原因。假设检验是通过使用样本数据来评估假设的合理性。
统计假设检验是一种统计推断方法,用于决定手头的数据是否充分支持某一特定假设。Paul Meehl认为,无效假设的选择在认识论上的重要性基本上没有得到承认。当无效假设是由理论预测的,一个更精确的实验将是对基础理论的更严格的检验。当无效假设默认为 “无差异 “或 “无影响 “时,一个更精确的实验是对促使进行实验的理论的一个较不严厉的检验。
1778年:皮埃尔-拉普拉斯比较了欧洲多个城市的男孩和女孩的出生率。他说 “很自然地得出结论,这些可能性几乎处于相同的比例”。因此,拉普拉斯的无效假设是,鉴于 “传统智慧”,男孩和女孩的出生率应该是相等的 。
1900: 卡尔-皮尔逊开发了卡方检验,以确定 “给定形式的频率曲线是否能有效地描述从特定人群中抽取的样本”。因此,无效假设是,一个群体是由理论预测的某种分布来描述的。他以韦尔登掷骰子数据中5和6的数量为例 。
1904: 卡尔-皮尔逊提出了 “或然性 “的概念,以确定结果是否独立于某个特定的分类因素。这里的无效假设是默认两件事情是不相关的(例如,疤痕的形成和天花的死亡率)。[16] 这种情况下的无效假设不再是理论或传统智慧的预测,而是导致费雪和其他人否定使用 “反概率 “的冷漠原则。
my-assignmentexpert™ 假设检验Hypothesis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的假设检验Hypothesis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此假设检验Hypothesis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在假设检验Hypothesis作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在假设检验Hypothesis代写方面经验极为丰富,各种假设检验HypothesisProcess相关的作业也就用不着 说。
我们提供的假设检验Hypothesis及其相关学科的代写,服务范围广, 其中包括但不限于:
- 时间序列分析Time-Series Analysis
- 马尔科夫过程 Markov process
- 随机最优控制stochastic optimal control
- 粒子滤波 Particle Filter
- 采样理论 sampling theory
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|AN ADAPTIVE KERNEL ESTIMATOR
对于大样本量,预期频率曲线通常会给出真实密度的平滑近似值,但对于小样本量,可能会得到相当参差不齐的近似值。平滑估计的一种可能方法是使用自适应内 核估计,已知该自适应核估计可以与已提出的其他估计器很好地竞争 Silverman, 1986;cf. PolitisandRomanoff, 1997. 事实上,自适应核估计器有很多变体, 但这里只介绍一种。跟随西尔弗萝 1986 ,让 $\bar{f}\left(X_i\right)$ 是一个初步估计 $f\left(X_i\right)$. 这里, $\tilde{f}\left(X_i\right)$ 基于预期的频率曲线。让
$$
\log g=\frac{1}{n} \sum \log \tilde{f}\left(X_i\right)
$$
和
$$
\lambda_i=\left(\tilde{f}\left(X_i\right) / g\right)^{-a},
$$
在哪里 $a$ 是满足的灵敏度参数 $0 \leq a \leq 1$. 根据 Silverman 的评论 $1986, a=.5$ 除非另有说明,否则使用。然后自适应核估计 $f$ 被认为是
在哪里
$$
K(t)=\left{\frac{3}{4}\left(1-\frac{1}{5} t^2\right) / \sqrt{5}, \quad|t|<\sqrt{5} 0, \quad\right. \text { otherwise }
$$
是 Epanechnikov 内核,并且,邅循 Silverman1986,pp. 47 – 48, 跨度是
$$
h=1.06 \frac{A}{n^{1 / 5}}
$$
在哪里
$$
A=\min (s, \mathrm{IQR} / 1.34),
$$
$s$ 是样本标准差,IQR 是四分位距。同样,如第 $3.12 .5$ 节所述估计四分位数范围usingwhatarecalledtheidealfourths.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|R AND S-PLUS FUNCTIONS
值得注意的是,两者R和 S-PLUS 有一个称为密度的内置函数,它根据各种选择计算核密度估计 $K$.
Thisfunctionalsocontainsvariousoptionsnotcoveredhere. 默认,K被视为标准正态密度。在这里,S-PLUSandR功能
$$
\operatorname{skerd}(x, o p=T)
$$
如果希望根据此估计量集合绘制数据,则提供。什么时候 $o p=T$ ,该函数使用 S-PLUS采用的默认密度估计器; 否则它使用 Venables 和 Ripley推䓔的方法 2002,p.127. With , thedefaultdensityestimatordiffers fromtheoneusedby $S-P L U S$, butwith $\$$ op $=F, R \$$ andS $-P L U S u s e t h e s a m e m e t h o d$. 功能
$$
\operatorname{kerden}(x, q=.5, x v a l=0),
$$
为本书而写,计算核密度估计 $f\left(x_q\right)$ 对于存储在 $\mathrm{R}$ or $S-P L U S$ 向量x使用第 3.2.2 节中描述的 Rosenblatt 移位直方图方法。
Again, seeSection $\$ 1.8$ \$onhowtoobtainthe functionswritten forthisbook. 如果末指定, $\mathrm{q}$ 默认为. $.5$. 参数 $\mathrm{xval}$ 被忽略,除非 $\mathrm{q}=0$, 在这种情况下函数估计 f什 么时候 $x$ 等于参数指定的值 $x v a l$. 功能
$$
\operatorname{kdplot}(x, r v a l=15)
$$
绘制估计值 $f(x)$ 基于函数 kerden,其中参数 rval 指示将使用多少个分位数。默认值 15 表示 $f(x)$ 估计有 15 个分位数均匀分布在.01和.99,然后函数绘制估计值以形 成估计值 $f(x)$.
S-PLUSandR功能
$$
\operatorname{rdplot}(\mathrm{x}, \mathrm{fr}=\mathrm{NA}, \text { plotit }=\mathrm{T}, \mathrm{pts}=\mathrm{NA}, \text { pyhat }=\mathrm{F})
$$
假设检验代写
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|AN ADAPTIVE KERNEL ESTIMATOR
对于大样本量,预期频率曲线通常会给出真实密度的平滑近似值,但对于小样本量,可能会得到相当参差不齐的近似值。平滑估计的一种可能方法是使用自适应内 核估计,已知该自适应核估计可以与已提出的其他估计器很好地竞争 Silverman, 1986;cf. PolitisandRomanoff, 1997. 事实上,自适应核估计器有很多变体,但这里只 介绍一种。跟随西尔弗萝 1986 ,让 $\bar{f}\left(X_i\right)$ 是一个初步估计 $f\left(X_i\right)$. 这里, $\tilde{f}\left(X_i\right)$ 基于预期的频率曲线。让
$$
\log g=\frac{1}{n} \sum \log \tilde{f}\left(X_i\right)
$$
和
$$
\lambda_i=\left(\tilde{f}\left(X_i\right) / g\right)^{-a},
$$
在哪里 $a$ 是满足的灵敏度参数 $0 \leq a \leq 1$. 根据 Silverman 的评论 $1986, a=.5$ 除非另有说明,否则使用。然后自适应核估计 $f$ 被认为是 在哪里
$\$ \$$
是Epanechnikov内核,并且,邅循Silverman 1986, pp. 47-48, 跨度是
$\mathrm{h}=1.06 \backslash \operatorname{frac}{A}\left{\mathrm{n}^{\wedge}{1 / 5}\right}$
在哪里
$\mathrm{A}=\backslash \min s, \mathrm{IQR} / 1.34$,
$\$ \$$
$s$ 是样本标准差,IQR 是四分位距。同样,如第 $3.12 .5$ 节所述估计四分位数范围usingwhatarecalledtheidealfourths.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|R AND S-PLUS FUNCTIONS
值得注意的是,两者R和 S-PLUS 有一个称为密度的内置函数,它根据各种选择计算核密度估计 $K$.
Thisfunctionalsocontainsvariousoptionsnotcoveredhere. 默认,K被视为标准正态密度。在这里,S-PLUSandR功能
$$
\operatorname{skerd}(x, o p=T)
$$
如果希望根据此估计量集合绘制数据,则提供。什么时候 $o p=T$ ,该函数使用 S-PLUS采用的默认密度估计器; 否则它使用 Venables 和 Ripley推苃的方法 2002,p.127. With, thedefaultdensityestimatordiffers fromtheoneusedby $S-P L U S$, 但是 $\$$ 上 $=F, R \$$ 和S $-P L U S u$ sethesamemethod. 功能
$$
\operatorname{kerden}(x, q=.5, x v a l=0) \text {, }
$$
为本书而写,计算核密度估计 $f\left(x_q\right)$ 对于存储在 R或者 $S-P L U S$ 向量x使用第 3.2.2 节中描述的 Rosenblatt移位直方图方法。
Again, seeSection $\$ 1.8$ \$onhowtoobtainthe functionswritten forthisbook. 如果末指定, $\mathrm{q}$ 默认为. . . 参数 xval 被忽略,除非 $\mathrm{q}=0$, 在这种情况下函数估计 ff十 么时候 $x$ 等于参数指定的值 $x v a l$. 功能
$$
\mathrm{kdplot}(x, \text { rval }=15)
$$
绘制估计值 $f(x)$ 基于函数 kerden,其中参数 rval 指示将使用多少个分位数。默认值 15 表示 $f(x)$ 估计有 15 个分位数均匀分布在.01和.99,然后函数绘制估计值以 形 成估计值 $f(x)$.
S-PLUSandR功能
$$
\operatorname{rdplot}(\mathrm{x}, \mathrm{fr}=\mathrm{NA}, \text { plotit }=\mathrm{T}, \mathrm{pts}=\mathrm{NA}, \text { pyhat }=\mathrm{F})
$$

统计代写| 假设检验作业代写Hypothesis testing代考|Population Parameters vs. Sample Statistics 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析(Numerical Analysis),又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。