如果你也在 怎样代写机器学习Machine Learning ENGG3300这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。

机器学习代考_Machine Learning代考_Explaining Text Models with Sentence Highlighting
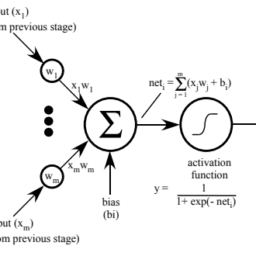
Sentence highlighting consists of assigning a score to every word based on the importance of that word in the final prediction. Formally, a sentence highlighting (SH) is modeled as a vector $s$ that explains a classification $\mathrm{y}=\mathrm{b}(\mathrm{x})$ of a black-box $\mathrm{b}$ on $\mathrm{x}$. The dimensions of $s$ are the words present in the sentence $\mathrm{x}$ we want to explain, and the si value is the saliency value of the word $i$. The greater the value of si, the greater the importance of that word. A positive value indicates a positive contribution toward y, while a negative one means that the word has contributed negatively.
ELI5 is a Python library that allows to visualize and debug various machine learning models using unified API. It has built-in support for several ML frameworks and provides a way to explain black-box models.
We are working with the Stack Overflow data set to explain how ELI5 works for the text data. This data set contains posts and the corresponding tag for the post.
This is a balanced data set and thus suited well for our purpose of understanding. First, use a simple scikit-learn pipeline to build a text classifier, which we interpret later. This pipeline uses a simple count vectorizer and logistic regression.
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import make_pipeline# Creating train-test Split
$X=$ sodata[[‘post’ $]]$
$y=$ sodata[[‘tags’]]x_train, X_test, y_train, y_test = train_test_split $(\mathrm{X}$,
$y$, test_size $=0.2$, random_state $=0) #$ fitting the classifier
vec $=$ CountVectorizer ()
$\mathrm{clf}=$ LogisticRegressionCV ()
pipe = make_pipeline $($ vec, clf $)$
pipe.fit(X_train.post, y_train.tags)
机器学习代考_Machine Learning代考_The Role of Data in Interpretability
Now, let’s try to understand what lies beyond the methods and modeling techniques.
This chapter attempts to find answers to the following questions.
- How does data complexity affect model explainability?
- If different tools generate the explanations, are they the same or different?
In the last few chapters, we studied the methods built on a framework of feature importance. We evaluated methods like CIU, DALEX, ELI5, SHAP, and Skater. Each of these methods works on some common theme to generate global importance measures for ranking features of the model.
Let’s elaborate on the preceding two questions. The tools mentioned earlier explain black-box models. Can it be deduced that they similarly generate the global feature importance of the same data sets, or is there a mismatch between the explanations generated for the same data set? On similar lines, are the generation of similar explanations related to specific properties of the data set?
This chapter answers the earlier two questions and whether data set complexity matters for interpretability. This is done by choosing tabular data sets, clustering the data sets based on various predefined properties, building models and explainability methods on these data sets, and then calculating the correlation between pairs of different methods to analyze the results.
The data sets ${ }^1$ were australian, phishing websites, spec, satellite, anal-catdata lawsuit, banknote authentication, blood transfusion service center, churn, climate model simulation crashes, credit-g, delta ailerons, diabetes, eeg-eye-state, haberman, heartstatlog, ilpd, ionosphere, jEdit-4.0-4.2, kc1, kc2, kc3, kr-vs-kp, mcl, monks-problems-1, monks-problems-2, monks-problems-3, mozilla4, mwl, ozone-level-8hr, pc1, pc2, pc3, pc4, phoneme, prnn crabs, qsar-biodeg, sonar, spambase, steel-plates-fault, and tic-tactoe e wdbc.
The following preprocessing steps were done to prepare the data sets for modeling purposes.
- Convert categorical features to ordinal values based on frequency.
- Convert boolean features to numerical ( 0 and 1$)$.
- Use min-max normalization to values between 0 and 1 .
机器学习代写
机器学习代考_MACHINE LEARNING代考_EXPLAINING TEXT MODELS WITH SENTENCE HIGHLIGHTING
句子突出显示包括根据每个词在最终预测中的重要性为每个词分配一个分数。形式上,一句话高亮 $S H$ 被建模为向量 $s$ 解释分类 $\mathrm{y}=\mathrm{b}(\mathrm{x})$ 一个黑匣子 上 $\mathrm{b}$. 的尺寸 $s$ 是句子中出现的单词x我们要解释, si值就是词的显着性值 $i$. si 的值越大,该词的重要性就越大。正值表示对 y 的正贡献,而负值表示该词有负贡献。 ELI5 是一个 Python 库,允许使用统一的 API 可视化和调试各种机器学习模型。它内置了对多个 ML框架的支持,并提供了一种解释黑盒模型的方法。 我们正在使用 Stack Overflow 数据集来解释 EL15如何处理文本数据。该数据集包含帖子和帖子的相应标签。
这是一个平衡的数据集,因此非常适合我们的理解目的。首先,使用一个简单的 scikit-learn 管道构建一个文本分类器,我们稍后对其进行解释。该管道使用简单的 计数向量化器和逻辑回归。
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import make_pipeline# 创建训练测试拆分 $X=$ 苏打
机器学习代考_MACHINE LEARNING代考_THE ROLE OF DATA IN INTERPRETABILITY
现在,让我们尝试了解方法和建模技术之外的内容。
本章试图找到以下问题的答案。
- 数据复杂性如何影响模型的可解释性?
- 如果不同的工具生成解释,它们是相同的还是不同的?
在最后几章中,我们研究了建立在特征重要性框架上的方法。我们评估了 CIU、DALEX、ELI5、SHAP和 Skater 等方法。这些方法中的每一种都针对一些共同 的主题来生成全局重要性度量来对模型的特征进行排名。
下面就前两个问题进行详细说明。前面提到的工具解释了黑㿾模型。是否可以推断出它们类似地生成了相同数据集的全局特征重要性,或者为相同数据集生成的解 释之间是否存在不匹配? 类似地,类似解释的产生是否与数据集的特定属性有关?
本章回答了前面的两个问题,以及数据集的复杂性是否对可解释性有影响。这是通过选择表格数据集,根据各种预定义属性对数据集进行聚类,在这些数据集上构 建模型和可解释性方法,然后计算不同方法对之间的相关性来分析结果来完成的。
数据集 ${ }^1$ 澳大利亚人、网络钓鱼网站、规格、卫星、肛门猫数据诉讼、钞票认证、输血服务中心、流失、气候模型模拟崩溃、credit-g、delta 副翼、糖尿病、eegeye-state、haberman、,heartstatlog、ilpd, 电离层, jEdit-4.0-4.2, kc1, kc2, kc3, kr-vs-kp, mcl, monks-problems-1, monks-problems-2, monks-problems-3, mozilla4, mwl, ozone-level-8hr, pc1, pc2, pc3, pc4, phoneme, prnn crabs, qsar-biodeg, sonar, spambase, steel-plates-fault, and tic-tactoe e wdbc.
完成以下预处理步骤以准备用于建模目的的数据集。
- 根据频率将分类特征转换为序数值。
- 将布尔特征转换为数值 $0 \mathrm{and} 1 \$ \$$.
- 对 0 和 1 之间的值使用最小-最大归一化。

机器学习代考_Machine Learning代考_ 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。