如果你也在 怎样代写随机控制理论Stochastic Control ECE684这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。随机控制理论Stochastic Control或随机最优控制是控制理论的一个子领域,它处理观察中或驱动系统进化的噪声中存在的不确定性。系统设计者以贝叶斯概率驱动的方式假设,具有已知概率分布的随机噪声会影响状态变量的演化和观测。随机控制的目的是设计受控变量的时间路径,以最小的成本执行所需的控制任务,尽管存在这种噪声,但以某种方式定义。
随机控制理论Stochastic Control在随机控制中,一个研究得极为透彻的表述是线性二次高斯控制。这里的模型是线性的,目标函数是二次形式的期望值,而干扰是纯加性的。对于只有加性不确定性的离散时间集中系统的一个基本结果是确定性等价特性:即这种情况下的最优控制方案与没有加性干扰时得到的方案相同。这一特性适用于所有具有线性演化方程、二次成本函数和仅以加法方式进入模型的噪声的集中式系统;二次假设允许遵循确定性等价特性的最优控制律是控制器观测值的线性函数。
随机控制理论Stochastic Control代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。最高质量的随机控制理论Stochastic Control作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此随机控制理论Stochastic Control作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在金融 Finaunce代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的金融 Finaunce代写服务。我们的专家在随机控制理论Stochastic Control代写方面经验极为丰富,各种随机控制理论Stochastic Control相关的作业也就用不着 说。
金融代写|随机控制理论代写Stochastic Control代考|Global distributed algorithm
Figure 3 summarizes the main three parts of our complete algorithm to compute optimal commands of a $N$ dimensional optimization problem and to test them in simulation. The first part is the reading of input data files according to the IO strategy introduced in section 3.7. The second part is the optimization solver execution, computing some Bellman values in a backward loop (see sections 1 and 3.1). At each step, a N-cube of Bellman values to compute is split on an hypercube of computing nodes to load balance the computations, a shadow region is identified and gathered on each node, some multithreaded local computations of optimal commands are achieved for each point of the N-cube (see section 4.3), and some temporary results are stored on disk. Then, the third part tests the previously computed commands. This simulation part runs a forward time step loop (see sections 1 and 3.2) and a Monte-Carlo trajectory sub-loop (see section 4.3), and uses the same previous mechanisms than the second part. At each time step, each node reads some temporary results it has stored during the optimization part, gather some shadow regions, achieves some local computations, and stores the final results on disk.
金融代写|随机控制理论代写Stochastic Control代考|Data N-cube splitting and data map setting
During the backward computation loop of the Bellman algorithm (see figure 1) of the optimization part of our application, we need to compute a N-dimensional cube of Bellman values at each time step. This computation is long and requires a large amount of memory to store the $\mathrm{N}$-cube data. So we have to split this $\mathrm{N}$-cube data on a set of computing nodes both to speedup (using more processors) and to size up (using more memory). Moreover, each dimension of this N-cube represents the stock levels of one stock that can change from time step $t_{n+1}$ to $t_n$. Each stock level range can be translated, and/or enlarged or shrunk. So, we have to redistribute our problem at each time step: we have to split a new $\mathrm{N}$-cube of stock point when entering a new time step. Our $\mathrm{N}$-cube splitting algorithm is a critical component of our distributed application that must run quickly. During the forward loop of the simulation part we reread on disk the maps stored during optimization.
The computation of one Bellman value at one point of the $t_n \mathrm{~N}$-cube requires the influence area of this value given by equation 2: the $t_{n+1}$ Bellman values at stocks points belonging to a small sub-cube of the $t_{n+1} \mathrm{~N}$-cube. Computation of the entire $t_n \mathrm{~N}$-sub-cube attached to one computing node requires an influence area that can be a large shadow region, leading to MPI communication of Bellman values stored on many other computing nodes (see figure 4). To minimize the size of this $\mathrm{N}$-dimensional shadow region we favor cubic $\mathrm{N}$-sub-cubes in place of flat ones. So, we aim to achieve cubic split of the $\mathrm{N}$-cube data at each time step.
We decided to split our $\mathrm{N}$-cube data on $P_{\max }=2^{d_{\max }}$ computing nodes. We successively split in two equal parts some dimensions of the N-cube, up to obtain $2^{d_{\max }}$ sub-cubes, or to have reach the limits of the division of the N-cube. Our algorithm includes 3 sub-steps:
- We split the dimensions of the $\mathrm{N}$-cube in order to obtain sub-cubes with close dimension sizes. We start to sort the $N^{\prime}$ divisible dimensions in decreasing order, and attempt to split the first one in 2 equal parts with sizes close to size of the second dimension. Then we attempt to split again the size of the 2 first dimensions to reduce their sizes close to the size of the third one. This splitting operation fails if it leads to a sub-cube dimension size smaller than a minimal size, set to avoid to process too small data sub-cubes. The splitting operation is repeated up to achieve $d_{\max }$ splits, or up to reduce the sizes of the $N^{\prime}-1$ first dimensions close to the size of the smallest one. Then, if we have not obtained $2^{d_{\max }}$ sub-cubes we run the second sub-step.
- Previously we have obtained sub-cubes with $N^{\prime}$ close dimension sizes. Now we sort these $N^{\prime}$ divisible dimensions in decreasing order, considering their split dimension sizes. We attempt to split again in 2 equal parts each divisible dimension in a round robin way, up to achieve $d_{\max }$ splits, or up to reach the limit of the minimal size for each divisible dimension. Then, if we have not obtained $2^{d_{\max }}$ sub-cubes we run the third sub-step.
- If it is specified to exceed the minimal size limit, then we split again in 2 equal parts each divisible dimension in a round robin way, up to achieve $d_{\max }$ splits, or up to reach dimension sizes equal to 1 . In our application, the minimal size value is set before to split a N-cube, and a command line option allows the user to respect or to exceed this limit. So, when processing small problems on large numbers of computing nodes, some experiments are required and can be rapidly conducted to point out the right tuning of our splitting algorithm.
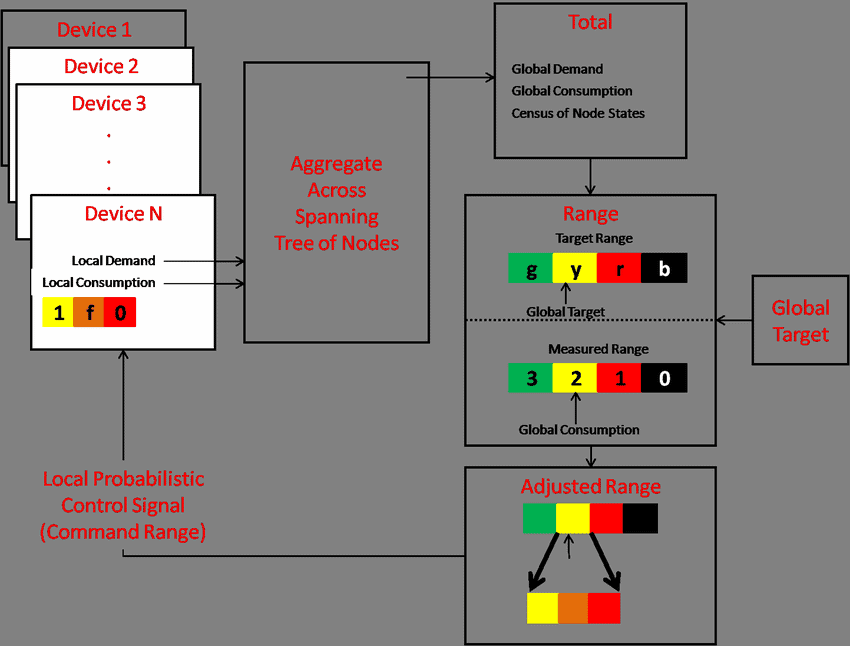
随机控制理论代写
金融代写|随机控制理论代写STOCHASTIC CONTROL代 考|GLOBAL DISTRIBUTED ALGORITHM
图 3 总结了我们完整算法的主要三个部分,用于计算 $a$ 的最优命令 $N$ 维优化问题并在仿真中对其进行测试. 第一部分是根据3.7节介绍的10策略续取输入数据文件。
相同的先前机制。在每个时间步,每个节点读取它在优化部分存储的一些临时结果,收集一些影子区域,实现一些本地计算,并将最終结果存储在磁盘上。
金融代写|随机控制理论代写STOCHASTIC CONTROL代考|DATA N-CUBE SPLITTING AND DATA MAP SETTING
在贝尔曼算法的反向计算循环中seefigure1在我们应用程序的优化部分,我们需要在每个时间步计算 Bellman 值的 $N$ 维立方体。这个计算很长,需要大量的内存 来存储 $\mathrm{N}$-立方体数据。所以我们必须分开这个 $\mathrm{N}$-一组计算节点上的立方体数据都可以加速usingmoreprocessors并放大usingmorememory. 此外,这个 $\mathrm{N}$ 立方 体的每个维度都代表一只股票的库存水平,它可以随时间步长变化 $t_{n+1}$ 到 $t_n$. 每个库存水平范围都可以转换和/或放大或缩小。所以,我们必须在每个时间步重新分 配我们的问题:我们必须拆分一个新的 $\mathrm{N}$-进入新时间步长时存货点的立方体。我们的 $\mathrm{N}$-立方体分裂算法是我们必须快速运行的分布式应用程序的关键组件。在模 拟部分的前向循环中,我们重新读取磁盘上优化期间存储的地图。
在某一点计算一个贝尔曼值 $t_n \mathrm{~N}$-cube 需要由等式 2 给出的该值的影响区域: $t_{n+1}$ Bellman 值属于 $t_{n+1} \mathrm{~N}$-立方体。整个计算 $t_n \mathrm{~N}$ – 附加到一个计算节点的子立方体 需要一个可以是大阴影区域的影响区域,从而导致存储在许多其他计算节点上的 Bellman 值的 MPI 通信seefigure4. 为了尽量减少这个尺寸N-dimensional 阴影区 域,我们喜欢 cubicN-子立方体代替平面立方体。所以,我们的目标是实现立方分裂 $\mathrm{N}$-每个时间步长的立方体数据。
我们决定分开我们的 $\mathrm{N}$-立方体数据 $P_{\text {max }}=2^{d_{\text {max }}}$ 计算节点。我们依次将 $\mathrm{N}$-立方体的一些维度分成两等份,直到得到 $2^{d_{\max }}$ 子立方体,或已达到 $\mathrm{N}$ 立方体划分的极 限。我们的算法包括 3 个子步踃:
- 我们拆分的维度 $N$-cube 以获得尺寸相近的子立方体。我们开始排序 $N^{\prime}$ 按降序排列的可分维度,并尝试将第一个维度分成大小接近第二个维度大小的两个相 等部分。然后我们営试再次拆分 2 个第一个维度的大小,以将它们的大小减小到接近第三个维度的大小。如果导致子立方体维度尺寸小于最小尺寸,则此拆 分操作失败,设置以避免处理太小的数据子立方体。重复拆分操作,达到 $d_{\max }$ 分裂,或向上减少的大小 $N^{\prime}-1$ 第一个尺寸接近最小尺寸的尺寸。那么,如果 我们还没有获得 $2^{d_{\max }}$ 子多維数据集我们运行第二个子步㡜。
- 之前我们已经获得了子立方体 $N^{\prime}$ 关闭维度大小。现在我们对这些进行排序 $N^{\prime}$ 考虑到它们的分割尺寸大小,按降序排列的可分割尺寸。我们尝试以循环方式 将每个可分割的维度再次分成 2 个相等的部分,直到达到 $d_{\text {max }}$ 拆分,或达到每个可分割维度的最小大小的限制。那么,如果我们还没有获得 $2^{d_{\text {max }}}$ 子多维数据 集我们运行第三个子步骤。
- 如果指定超过最小尺寸限制,那么我们再次将每个可分割的维度以循环的方式分成2等份,直到达到 $d_{\text {max }}$ 拆分,或达到等于 1 的维度大小。在我们的应用程序 中,在拆分 $N$ 立方体之前设置了最小大小值,命令行选项允许用户遷守或超过此限制。因此,当在大量计算节点上处理小问题时,需要进行一些实验并且可 以快速进行以指出我们的分裂算法的正确调整。

金融代写|随机控制理论代写Stochastic Control代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。