如果你也在 怎样代写数据可视化Data visualization 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。数据可视化Data visualization(data viz或info viz)是一个跨学科的领域,处理数据和信息的图形表示。当数据或信息数量众多时,它是一种特别有效的交流方式,例如时间序列。
数据可视化Data visualization领域是 “从人机交互、计算机科学、图形学、视觉设计、心理学和商业方法的研究中产生的。它越来越多地被用作科学研究、数字图书馆、数据挖掘、金融数据分析、市场研究、制造业生产控制和药物发现的一个重要组成部分”。
my-assignmentexpert™数据可视化Data visualization代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的数据可视化Data visualization作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此数据可视化Data visualization作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
统计代写|数据可视化代考Data visualization代考Previous Work
Tetrahedral meshes constructed by longest-edge bisection have been used in many visualization applications due to their simple, elegant, and crack-preventing adaptive refinement properties. In [5], fine-to-coarse and coarse-to-fine mesh refinement is used to adaptively extract isosurfaces from volume datasets. Gerstner and $\mathrm{Pa}-$ jarola [7] present an algorithm for preserving the topology of an extracted isosurface using a coarse-to-fine refinement scheme assuming linear interpolation within a tetrahedron. Their algorithm can be used to extract topology-preserving isosurfaces or to perform controlled topology simplification. In [6], Gerstner shows how to render multiple transparent isosurfaces using these tetrahedral meshes, and in [8], Gerstner and Rumpf parallelize the isosurface extraction by assigning portions of the binary tree created by the tetrahedral refinement to different processors. Roxborough and Nielson [16] describe a method for adaptively modeling 3D ultrasound data. They create a model of the volume that conforms to the local complexity of the underlying data. A least-squares fitting algorithm is used to construct a best piecewise linear approximation of the data.
Contouring quadratic functions defined over triangular domains is discussed in $[1,14,17]$. Worsey and Farin [14] use Bernstein-Bézier polynomials which provide a higher degree of numerical stability compared to the monomial basis used by Marlow and Powell [17]. Bloomquist [1] provides a foundation for finding contours in quadratic elements.
In [19] and [20], quadratic functions are used for hierarchical approximation over triangular and tetrahedral domains. The approximation scheme uses the normalequations approach described in [3] and computes the best least-squares approximation. A dataset is approximated with an initial set of quadratic triangles or tetrahedra. The initial mesh is repeatedly subdivided in regions of high error to improve the approximation. The quadratic elements are visualized by subdividing them into linear elements.
Our technique for constructing a quadratic approximation differs from [19] and [20] as we use univariate approximations along a tetrahedron’s edges to define the coefficients for an approximating tetrahedron. We extract an isosurface directly from a quadratic tetrahedron by creating a set of rational-quadratic patches that approximates the isosurface. The technique we use for isosurfacing quadratic tetrahedra is described in [21].
统计代写|数据可视化代考Data visualization代考|Quadratic Tetrahedra
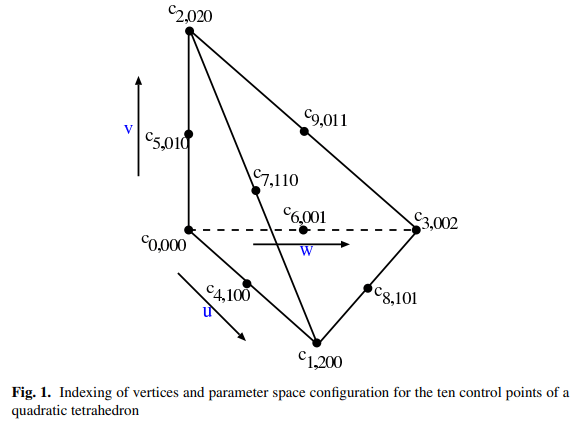
A linear tetrahedron $T_L(u, v, w)$ having four coefficients $f_i$ at its vertices $\mathbf{V}i$ is defined as $$ \begin{aligned} T_L(u, v, w)= & f_0 u+f_1 v+f_2 w \ & +f_3(1-u-v-w) . \end{aligned} $$ The quadratic tetrahedron $T_Q(u, v, w)$ (called $\left.T_Q\right)$ that we use as our decomposition element has linearly defined edges such that its domain is completely described by four vertices (the same as a conventional linear tetrahedron). The function over $T_Q$ is defined by a quadratic polynomial. We call this element a linear-edge quadratic tetrahedron or quadratic tetrahedron. The quadratic polynomial is defined, in BernsteinBézier form, by ten coefficients $c_m, 0 \leq m \leq 9$, as $$ T_Q(u, v, w)=\sum{k=0}^1 \sum_{j=0}^{2-k} \sum_{i=0}^{2-k-j} c_{i j k} B_{i j k}^2(u, v, w)
$$
The Bernstein-Bézier basis functions $B_{i j k}^2(u, v, w)$ are
$$
\begin{aligned}
B_{i j k}^2= & \frac{2 !}{(2-i-j-k) ! i ! j ! k !} \
& (1-u-v-w)^{2-i-j-k} u^i v^j w^k
\end{aligned}
$$
The indexing of the coefficients is shown in Fig. 1.
数据可视化代写
统计代写|数据可视化代考Data visualization代考Previous Work
由最长边等分构造的四面体网格由于其简单、美观和防止裂纹的自适应细化特性,在许多可视化应用中得到了应用。在[5]中,采用从细到粗和从粗到细的网格细化方法从体数据集中自适应提取等值面。Gerstner和$\mathrm{Pa}-$ jarola[7]提出了一种算法,该算法使用假设四面体内线性插值的粗细细化方案来保留提取的等值面的拓扑结构。他们的算法可用于提取拓扑保持等值面或执行控制拓扑简化。在[6]中,Gerstner展示了如何使用这些四面体网格渲染多个透明等值面,在[8]中,Gerstner和Rumpf通过将四面体细化生成的二叉树的部分分配给不同的处理器来并行化等值面提取。Roxborough和Nielson[16]描述了一种自适应三维超声数据建模的方法。它们创建一个符合底层数据的局部复杂性的卷模型。采用最小二乘拟合算法构造数据的最佳分段线性逼近。
在$[1,14,17]$中讨论了在三角形域上定义的轮廓二次函数。Worsey和Farin[14]使用bernstein – bsamzier多项式,与Marlow和Powell[17]使用的一元基相比,它提供了更高程度的数值稳定性。Bloomquist[1]为在二次元中求等值线提供了基础。
在[19]和[20]中,二次函数用于在三角形和四面体域上进行分层逼近。近似方案使用[3]中描述的正态方程方法,并计算最佳最小二乘近似。数据集是用一组初始的二次三角形或四面体来近似的。在高误差区域对初始网格进行重复细分,以提高逼近性。二次元通过将其细分为线性元来可视化。
我们构建二次逼近的技术与[19]和[20]不同,因为我们使用沿四面体边缘的单变量逼近来定义近似四面体的系数。我们通过创建一组近似于等值面的有理二次块,直接从二次四面体提取等值面。我们用于等面二次四面体的技术在[21]中有描述。
统计代写|数据可视化代考Data visualization代考|Quadratic Tetrahedra
一个线性四面体$T_L(u, v, w)$在其顶点处有四个系数$f_i$$\mathbf{V}i$定义为$$ \begin{aligned} T_L(u, v, w)= & f_0 u+f_1 v+f_2 w \ & +f_3(1-u-v-w) . \end{aligned} $$二次四面体$T_Q(u, v, w)$(称为$\left.T_Q\right)$,我们使用它作为分解元素)具有线性定义的边缘,这样它的域完全由四个顶点描述(与传统的线性四面体相同)。$T_Q$上的函数由二次多项式定义。我们称这种元素为线性边缘二次四面体或二次四面体。在bernsteinbsamzier形式中,二次多项式由十个系数$c_m, 0 \leq m \leq 9$定义为$$ T_Q(u, v, w)=\sum{k=0}^1 \sum_{j=0}^{2-k} \sum_{i=0}^{2-k-j} c_{i j k} B_{i j k}^2(u, v, w)
$$
bernstein – bsamzier基函数$B_{i j k}^2(u, v, w)$是
$$
\begin{aligned}
B_{i j k}^2= & \frac{2 !}{(2-i-j-k) ! i ! j ! k !} \
& (1-u-v-w)^{2-i-j-k} u^i v^j w^k
\end{aligned}
$$
系数索引如图1所示。

统计代写|数据可视化代考Data visualization代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。