如果你也在 怎样代写扩散模型Diffusion Model COMP4702这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。扩散模型Diffusion Model在机器学习中,扩散模型,也被称为扩散概率模型,是一类潜变量模型。这些模型是使用变异推理训练的马尔科夫链。扩散模型的目标是通过对数据点在潜在空间中的扩散方式进行建模来学习数据集的潜在结构。在计算机视觉中,这意味着一个神经网络被训练为通过学习逆转扩散过程来对高斯噪声模糊的图像进行去噪。
扩散模型Diffusion Model可以应用于各种任务,包括图像去噪、画中画、超分辨率和图像生成。例如,一个图像生成模型将从一个随机的噪声图像开始,然后在经过对自然图像的扩散过程进行反转训练后,该模型将能够生成新的自然图像。2022年4月13日宣布的OpenAI的文本到图像模型DALL-E 2是一个最近的例子。它将扩散模型用于模型的先验(产生给定文本标题的图像嵌入)和产生最终图像的解码器。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
计算机代写|扩散模型代写Diffusion Model代考|Evidence Lower Bound
Mathematically, we can imagine the latent variables and the data we observe as modeled by a joint distribution $p(\boldsymbol{x}, \boldsymbol{z})$. Recall one approach of generative modeling, termed “likelihood-based”, is to learn a model to maximize the likelihood $p(\boldsymbol{x})$ of all observed $\boldsymbol{x}$. There are two ways we can manipulate this joint distribution to recover the likelihood of purely our observed data $p(\boldsymbol{x})$; we can explicitly marginalize out the latent variable $z$ :
$$
p(\boldsymbol{x})=\int p(\boldsymbol{x}, \boldsymbol{z}) d \boldsymbol{z}
$$
or, we could also appeal to the chain rule of probability:
$$
p(\boldsymbol{x})=\frac{p(\boldsymbol{x}, \boldsymbol{z})}{p(\boldsymbol{z} \mid \boldsymbol{x})}
$$
Directly computing and maximizing the likelihood $p(\boldsymbol{x})$ is difficult because it either involves integrating out all latent variables $\boldsymbol{z}$ in Equation 1, which is intractable for complex models, or it involves having access to a ground truth latent encoder $p(\boldsymbol{z} \mid \boldsymbol{x})$ in Equation 2. However, using these two equations, we can derive a term called the Evidence Lower Bound (ELBO), which as its name suggests, is a lower bound of the evidence. The evidence is quantified in this case as the $\log$ likelihood of the observed data. Then, maximizing the ELBO becomes a proxy objective with which to optimize a latent variable model; in the best case, when the ELBO is powerfully parameterized and perfectly optimized, it becomes exactly equivalent to the evidence. Formally, the equation of the ELBO is:
$$
\mathbb{E}{q\phi(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{q_{\boldsymbol{\phi}}(\boldsymbol{z} \mid \boldsymbol{x})}\right]
$$
计算机代写|扩散模型代写Diffusion Model代考|Hierarchical Variational Autoencoders
A Hierarchical Variational Autoencoder (HVAE) [2,3] is a generalization of a VAE that extends to multiple hierarchies over latent variables. Under this formulation, latent variables themselves are interpreted as generated from other higher-level, more abstract latents. Intuitively, just as we treat our three-dimensional observed objects as generated from a higher-level abstract latent, the people in Plato’s cave treat threedimensional objects as latents that generate their two-dimensional observations. Therefore, from the perspective of Plato’s cave dwellers, their observations can be treated as modeled by a latent hierarchy of depth two (or more).
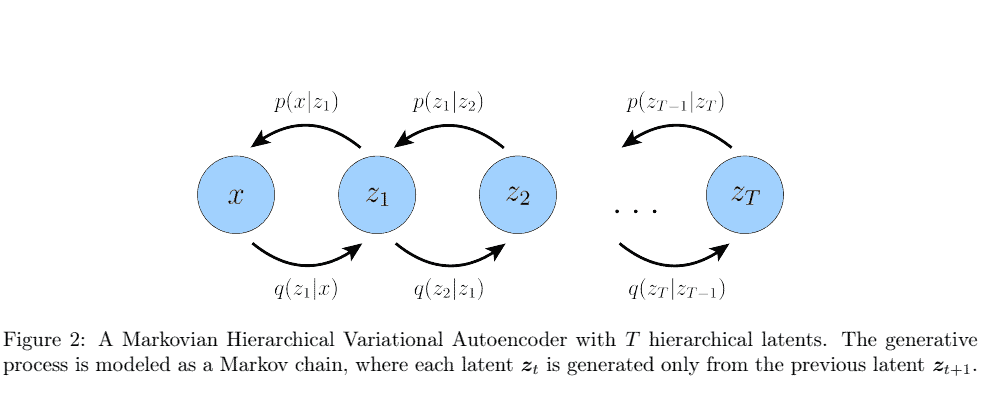
Whereas in the general HVAE with $T$ hierarchical levels, each latent is allowed to condition on all previous latents, in this work we focus on a special case which we call a Markovian HVAE (MHVAE). In a MHVAE, the generative process is a Markov chain; that is, each transition down the hierarchy is Markovian, where decoding each latent $\boldsymbol{z}t$ only conditions on previous latent $\boldsymbol{z}{t+1}$. Intuitively, and visually, this can be seen as simply stacking VAEs on top of each other, as depicted in Figure 2; another appropriate term describing this model is a Recursive VAE. Mathematically, we represent the joint distribution and the posterior of a Markovian HVAE as:
$$
\begin{aligned}
p\left(\boldsymbol{x}, \boldsymbol{z}{1: T}\right) &=p\left(\boldsymbol{z}_T\right) p{\boldsymbol{\theta}}\left(\boldsymbol{x} \mid \boldsymbol{z}1\right) \prod{t=2}^T p_{\boldsymbol{\theta}}\left(\boldsymbol{z}{t-1} \mid \boldsymbol{z}_t\right) \ q{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right) &=q{\boldsymbol{\phi}}\left(\boldsymbol{z}1 \mid \boldsymbol{x}\right) \prod{t=2}^T q_{\boldsymbol{\phi}}\left(\boldsymbol{z}t \mid \boldsymbol{z}{t-1}\right)
\end{aligned}
$$
Then, we can easily extend the ELBO to be:
$$
\begin{aligned}
\log p(\boldsymbol{x}) &=\log \int p\left(\boldsymbol{x}, \boldsymbol{z}{1: T}\right) d \boldsymbol{z}{1: T} & & \text { (Apply Equation 1) } \
&=\log \int \frac{p\left(\boldsymbol{x}, \boldsymbol{z}{1: T}\right) q{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)}{q{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)} d \boldsymbol{z}{1: T} & & \text { (Multiply by } 1=\frac{q_{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)}{q{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)} \ &=\log \mathbb{E}{q_\phi\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)}\left[\frac{p\left(\boldsymbol{x}, \boldsymbol{z}{1: T}\right)}{q_{\boldsymbol{\phi}}\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)}\right] & & \text { (Definition of Expectation) } \ & \geq \mathbb{E}{q_\phi\left(\boldsymbol{z}{1: T} \mid \boldsymbol{x}\right)}\left[\log \frac{p\left(\boldsymbol{x}, \boldsymbol{z}{1: T}\right)}{q_{\boldsymbol{\phi}}\left(\boldsymbol{z}_{1: T} \mid \boldsymbol{x}\right)}\right] & & \text { (Apply Jensen’s Inequality) }
\end{aligned}
$$
扩散模型代写
计算机代写|扩散模型代写DIFFUSION MODEL代考|EVIDENCE LOWER BOUND
在数学上,我们可以想象潜在变量和我们观察到的数据是由联合分布建模的 $p(\boldsymbol{x}, \boldsymbol{z})$. 回想一下生成建模的一种方法,称为 “基于可能性”,是学习一个模型以最大化 可能性 $p(\boldsymbol{x})$ 在所有观察到的 $\boldsymbol{x}$. 有两种方法可以操纵这种联合分布来恢复纯䊉我们观察到的数据的可能性 $p(\boldsymbol{x})$; 我们可以明确地边缘化潜在变量 $z$ :
$$
p(\boldsymbol{x})=\int p(\boldsymbol{x}, \boldsymbol{z}) d \boldsymbol{z}
$$
或者,我们也可以诉诸概率链规则:
$$
p(\boldsymbol{x})=\frac{p(\boldsymbol{x}, \boldsymbol{z})}{p(\boldsymbol{z} \mid \boldsymbol{x})}
$$
直接计算并最大化似然性 $p(\boldsymbol{x})$ 很困难,因为它要么涉及整合所有潜在变量 $z$ 在等式 1 中,这对于复杂模型来说是难以处理的,或者它涉及访问地面实况潜在编码器 $p(\boldsymbol{z} \mid \boldsymbol{x})$ 在等式 2 中。然而,使用这两个等式,我们可以推导出一个称为证据下限的项 $E L B O$ ,顾名思义,是证据的下限。在这种情况下,证据被量化为 $l 0 \mathrm{~g}$ 观测 数据的可能性。然后,最大化 ELBO 成为优化潜变量模型的代理目标; 在最好的情况下,当 ELBO 被强大的参数化和完美优化时,它变得与证据完全等价。形式 上,ELBO 的方程是:
$\$$
$\backslash$ mathbb ${$ E $}{q \backslash$ phiz $\mid \boldsymbol{x}} \backslash$ 剩下
计算机代写|扩散模型代写DIFFUSION MODEL代 考|HIERARCHICAL VARIATIONAL AUTOENCODERS
分层变分自动编码器 $H V A E$
2,3
是 VAE 的推广,它扩展到潜在变量上的多个层次结构。在这个公式下,漑在变量本身被解释为从其他更高级别、更抽象的潜在变量中生成的。直观地说,正如我们 将观察到的三维物体视为从更高层次的抽象潜在对象中生成的一样,柏拉图洞穴中的人们将三维对象视为生成二维观察的潜在对象。因此,从柏拉图的穴居人的角 度来看,他们的观察可以被视为由深度二的潜在层次结构建模ormore.
而在一般 HVAE 中 $T$ 分层级别,每个潜在都可以以所有先前的潜在为条件,在这项工作中,我们专注于一种特殊情况,我们称之为马尔可夫 HVAE $M H V A E$. 在 MHVAE 中,生成过程是马尔可夫链; 也就是说,层次结构中的每个转换都是马尔可夫的,其中解码每个洹在的 $z t$ 仅对先前潜在的条件 $z t+1$. 从直观上看,这可以
$$
p(\boldsymbol{x}, \boldsymbol{z} 1: T)=p\left(\boldsymbol{z}T\right) p \boldsymbol{\theta}(\boldsymbol{x} \mid \boldsymbol{z} 1) \prod t=2^T p{\boldsymbol{\theta}}\left(\boldsymbol{z} t-1 \mid \boldsymbol{z}t\right) q \boldsymbol{\phi}(\boldsymbol{z} 1: T \mid \boldsymbol{x}) \quad=q \boldsymbol{\phi}(\boldsymbol{z} 1 \mid \boldsymbol{x}) \prod t=2^T q\phi(\boldsymbol{z} t \mid \boldsymbol{z} t-1)
$$
然后,我们可以轻松地将 ELBO 扩展为:
$\log p(\boldsymbol{x})=\log \int p(\boldsymbol{x}, \boldsymbol{z} 1: T) d \boldsymbol{z} 1: T \quad$ (Apply Equation 1$) \quad=\log \int \frac{p(\boldsymbol{x}, \boldsymbol{z} 1: T) q \boldsymbol{\phi}(\boldsymbol{z} 1: T \mid \boldsymbol{x})}{q \boldsymbol{\phi}(\boldsymbol{z} 1: T \mid \boldsymbol{x})} d \boldsymbol{z} 1: T \quad$ (Multiply by $1=\frac{q_\phi(\boldsymbol{z} 1: T \mid \boldsymbol{x})}{q \boldsymbol{\phi}(\boldsymbol{z} 1: T \mid \boldsymbol{x})}$

计算机代写|扩散模型代写Diffusion Model代考 . exambang™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。