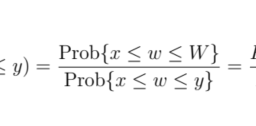my-assignmentexpert™ Economics 经济学作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 $100 \%$ 原创。my-assignmentexpert™, 最高质量的ECON经济学作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于economics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此经济作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在经济学作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的经济代写服务。我们的专家在经济学 代写方面经验极为丰富,各种economics相关的作业也就用不着 说。
我们提供的econ代写服务范围广, 其中包括但不限于:
- 微观经济学
- 货币银行学
- 数量经济学
- 宏观经济学
- 经济统计学
- 经济学理论
- 商务经济学
- 计量经济学
- 金融经济学
- 国际经济学
- 健康经济学
- 劳动经济学
Econ经济作业代写Economics代考|Correlated equilibria
Telling how to play|Econ经济作业代写Economics代考
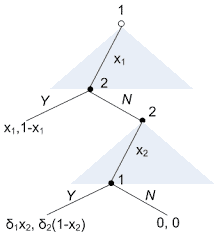
Thus, in these static Bayesian games we have $T_{i}=A_{i}$ for each player $i \in N$ so that player $i$ ‘s strategy is a function $s_{i}: A_{i} \rightarrow A_{i}$. Obeying the suggestion is tantamount to using the identity function as a strategy, $s_{i}=i d_{i}: A_{i} \rightarrow A_{i}, a_{i} \mapsto i d_{i}\left(a_{i}\right)=a_{i}$. We are particularly interested in knowing when $s=\left(i d_{1}, i d_{2}, \ldots, i d_{n}\right)$ is an equilibrium strategy combination.
Consider, now, the prisoners’ dilemma:
player 2
deny confess
player 1
\begin{tabular}{c|c|c|}
deny & 4,4 & 0,5 \
\cline { 2 – 3 } confess & 5,0 & 1,1 \
\cline { 2 – 3 } & &
\end{tabular}
The type sets are $T_{1}=T_{2}={$ deny, confess $}$. Assume the probability distribution $\tau$ on $T=T_{1} \times T_{2}$ is given by $\tau($ deny, deny $)=1$. This probability distribution implies that both players learn the suggestion “deny” with probability 1 . This is a very good suggestion because $-$ if followed $-$ the players obtain 4 rather than 1 in the dominant-strategy equilibrium of the strategic game. Of course, the “if” is essential. Even if player 1 assumes that player 2 will follow the recommendation, player 1 prefers to choose confess.
Thus, we look for suggestions that players like to follow in equilibrium.
The recommendation game|ECON经济作业代写ECONOMICS代考
PROOF. Consider a player $i \in N$ who learns his type $a_{i}^{} \in T_{i}=A_{i}$. This player $i$ knows that $a_{i}^{}$ is part of an equilibrium, that the other players learn the strategy combination $a_{-i}^{} \in T_{-i}$, and that $\left(a_{i}^{}, a_{-i}^{}\right)$ is a Nash equilibrium of $\Gamma$. Thus, if $i$ believes that the other players $j \in N \backslash{i}$ have strategy $s_{j}^{}=i d_{j}: A_{j} \rightarrow A_{j}$ and will therefore choose $s_{j}^{}\left(a_{j}^{}\right)=a_{j}^{}$, the best that $i$ can do is to choose $a_{i}^{} \in \arg \max {a{i} \in A_{i}} u_{i}\left(a_{i}, a_{-i}^{}\right)$ himself. Thus $s_{i}^{}=i d_{i}$ is a best response to $s_{-i}^{*}=\left(i d_{1}, \ldots, i d_{i-1}, i d_{i+1}, \ldots, i d_{n}\right)$.
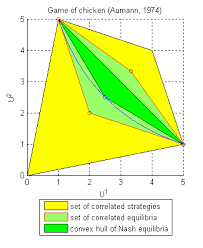
By playing a recommendation game, the players can realize any payoff vector that lies in the convex hull (p. 376) of the equilibrium payoff vectors belonging to $\Gamma$. However, one can do even better.
Going beyond the convex hull|Econ经济作业代写Economics代考
The idea behind this probability distribution is to avoid the zero payoff associated with the action combination $\left(a_{1}^{2}, a_{2}^{2}\right)$. It yields the payoff
$$
\frac{1}{3} \cdot 7+\frac{1}{3} \cdot 6+\frac{1}{3} \cdot 2=5
$$
for each player (see figure XVII.3). So far, so good. We still need to confirm that $s_{1}=i d_{1}$ is a best reply to $s_{2}=i d_{2}$ (and vice versa). Assume player 1 observes the recommendation $a_{1}^{1}$. He then believes that player 2 got the recommendation $a_{2}^{1}$ with (conditional) probability
$$
\tau_{1}\left(a_{2}^{1}\right)=\tau\left(a_{2}^{1} \mid a_{1}^{1}\right)=\frac{\tau\left(a_{2}^{1}, a_{1}^{1}\right)}{\tau\left(a_{1}^{1}\right)}=\frac{\tau\left(a_{2}^{1}, a_{1}^{1}\right)}{\tau\left(a_{1}^{1}, a_{2}^{1}\right)+\tau\left(a_{1}^{1}, a_{2}^{2}\right)}=\frac{\frac{1}{3}}{\frac{2}{3}}=\frac{1}{2}
$$
Thus, player 1 prefers to follow his recommendation and choose $a_{1}^{1}$ if he assumes that player 2 is obedient:
$$
\begin{aligned}
& \tau_{1}\left(a_{2}^{1}\right) u\left(a_{1}^{1}, a_{2}^{1}\right)+\tau_{1}\left(a_{2}^{2}\right) u\left(a_{1}^{1}, a_{2}^{2}\right) \
& \tau_{1}\left(a_{2}^{1}\right) u\left(a_{1}^{2}, a_{2}^{1}\right)+\tau_{1}\left(a_{2}^{2}\right) u\left(a_{1}^{2}, a_{2}^{2}\right) \
\Leftrightarrow & \frac{1}{2} \cdot 6+\frac{1}{2} \cdot 2>\frac{1}{2} \cdot 7+\frac{1}{2} \cdot 0 .
\end{aligned}
$$
Assume, on the other hand, recommendation $a_{1}^{2}$. From observing $a_{1}^{2}$, player 1 knows that player 2 got recommendation $a_{2}^{1}$. Just look at $\tau$ or calculate the conditional probability
TELLING HOW TO PLAY|ECON经济作业代写ECONOMICS代考
因此,在这些静态贝叶斯游戏中,我们有吨一世=一种一世对于每个玩家一世∈ñ所以那个玩家一世的策略是一个函数s一世:一种一世→一种一世. 听从建议无异于以恒等函数为策略,s一世=一世d一世:一种一世→一种一世,一种一世↦一世d一世(一种一世)=一种一世. 我们特别想知道什么时候s=(一世d1,一世d2,…,一世dn)是一种均衡策略组合。
现在考虑一下囚徒困境:
玩家 2
不承认
玩家 1
\begin{tabular}{c|c|c|} 拒绝 & 4,4 & 0,5 \ \cline { 2 – 3 } 承认 & 5,0 & 1,1 \ \cline { 2 – 3 } & & \结束{表格}\begin{tabular}{c|c|c|} 拒绝 & 4,4 & 0,5 \ \cline { 2 – 3 } 承认 & 5,0 & 1,1 \ \cline { 2 – 3 } & & \结束{表格}
类型集是吨1=吨2=$d和n和,C○nF和ss$. 假设概率分布τ在吨=吨1×吨2是(谁)给的τ(否认,否认)=1. 这个概率分布意味着两个玩家都以概率 1 学习建议“拒绝”。这是一个非常好的建议,因为−如果跟随−玩家在战略博弈的主导战略均衡中获得 4 而不是 1。当然,“如果”是必不可少的。即使玩家 1 假设玩家 2 会遵循建议,玩家 1 也更愿意选择坦白。
因此,我们寻找玩家喜欢在平衡中遵循的建议。
THE RECOMMENDATION GAME|ECON经济作业代写ECONOMICS代考
证明。考虑一个玩家一世∈ñ谁知道他的类型 $a_{i}^{ } \in T_{i}=A_{i}.吨H一世sp一世一种和和r一世到n○在s吨H一种吨一个_{我}^{ }一世sp一种r吨○F一种n和q你一世一世一世br一世你米,吨H一种吨吨H和○吨H和rp一世一种和和rs一世和一种rn吨H和s吨r一种吨和G和C○米b一世n一种吨一世○na_{-i}^{ } \in T_{-i},一种nd吨H一种吨\left(a_{i}^{ }, a_{-i}^{ }\right)一世s一种ñ一种sH和q你一世一世一世br一世你米○F\伽玛.吨H你s,一世F一世b和一世一世和v和s吨H一种吨吨H和○吨H和rp一世一种和和rsj \in N \反斜杠{i}H一种v和s吨r一种吨和G和s_{j}^{ }=i d_{j}: A_{j} \rightarrow A_{j}一种nd在一世一世一世吨H和r和F○r和CH○○s和s_{j}^{ }\left(a_{j}^{ }\right)=a_{j}^{ },吨H和b和s吨吨H一种吨一世C一种nd○一世s吨○CH○○s和a_{i}^{ } \in \arg \max {a {i} \in A_{i}} u_{i}\left(a_{i}, a_{-i}^{ }\right)H一世米s和一世F.吨H你ss_{i}^{ }=i d_{i}一世s一种b和s吨r和sp○ns和吨○s_{-i}^{*}=\left(i d_{1}, \ldots, i d_{i-1}, i d_{i+1}, \ldots, i d_{n}\right)$ .
通过玩推荐游戏,玩家可以实现位于属于的均衡支付向量的凸包(第 376 页)中的任何支付向量Γ. 但是,可以做得更好。
GOING BEYOND THE CONVEX HULL|ECON经济作业代写ECONOMICS代考
这种概率分布背后的想法是避免与动作组合相关的零收益(一种12,一种22). 它产生了回报
13⋅7+13⋅6+13⋅2=5
每个球员(见图 XVII.3)。到目前为止,一切都很好。我们仍然需要确认s1=一世d1是最好的答复s2=一世d2(反之亦然)。假设玩家 1 遵守推荐一种11. 然后他认为玩家 2 得到了推荐一种21有(条件)概率
τ1(一种21)=τ(一种21∣一种11)=τ(一种21,一种11)τ(一种11)=τ(一种21,一种11)τ(一种11,一种21)+τ(一种11,一种22)=1323=12
因此,玩家 1 更愿意听从他的建议并选择一种11如果他假设玩家 2 是听话的:
$$
\begin{aligned}
& \tau_{1}\left(a_{2}^{1}\right) u\left(a_{1}^{1}, a_ {2}^{1}\right)+\tau_{1}\left(a_{2}^{2}\right) u\left(a_{1}^{1}, a_{2}^{2 }\正确的) \
& \tau_{1}\left(a_{2}^{1}\right) u\left(a_{1}^{2}, a_{2}^{1}\right)+\tau_{1} \left(a_{2}^{2}\right) u\left(a_{1}^{2}, a_{2}^{2}\right) \
\Leftrightarrow & \frac{1}{2} \cdot 6+\frac{1}{2} \cdot 2>\frac{1}{2} \cdot 7+\frac{1}{2} \cdot 0 。
\end{aligned}
$$
另一方面,假设推荐一种12. 从观察一种12, 玩家 1 知道玩家 2 得到了推荐一种21. 看看τ或计算条件概率

matlab代写请认准UprivateTA™.
经济代写
计量经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
微观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
宏观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写