如果你也在 怎样代写假设检验Hypothesis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。假设检验Hypothesis是假设检验是统计学中的一种行为,分析者据此检验有关人口参数的假设。分析师采用的方法取决于所用数据的性质和分析的原因。假设检验是通过使用样本数据来评估假设的合理性。
统计假设检验是一种统计推断方法,用于决定手头的数据是否充分支持某一特定假设。
空白假设的早期选择
Paul Meehl认为,无效假设的选择在认识论上的重要性基本上没有得到承认。当无效假设是由理论预测的,一个更精确的实验将是对基础理论的更严格的检验。当无效假设默认为 “无差异 “或 “无影响 “时,一个更精确的实验是对促使进行实验的理论的一个较不严厉的检验。
1778年:皮埃尔-拉普拉斯比较了欧洲多个城市的男孩和女孩的出生率。他说 “很自然地得出结论,这些可能性几乎处于相同的比例”。因此,拉普拉斯的无效假设是,鉴于 “传统智慧”,男孩和女孩的出生率应该是相等的 。
1900: 卡尔-皮尔逊开发了卡方检验,以确定 “给定形式的频率曲线是否能有效地描述从特定人群中抽取的样本”。因此,无效假设是,一个群体是由理论预测的某种分布来描述的。他以韦尔登掷骰子数据中5和6的数量为例 。
1904: 卡尔-皮尔逊提出了 “或然性 “的概念,以确定结果是否独立于某个特定的分类因素。这里的无效假设是默认两件事情是不相关的(例如,疤痕的形成和天花的死亡率)。[16] 这种情况下的无效假设不再是理论或传统智慧的预测,而是导致费雪和其他人否定使用 “反概率 “的冷漠原则。
my-assignmentexpert™ 假设检验Hypothesis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的假设检验Hypothesis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此假设检验Hypothesis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在假设检验Hypothesis作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在假设检验Hypothesis代写方面经验极为丰富,各种假设检验HypothesisProcess相关的作业也就用不着 说。
我们提供的假设检验Hypothesis及其相关学科的代写,服务范围广, 其中包括但不限于:
- 时间序列分析Time-Series Analysis
- 马尔科夫过程 Markov process
- 随机最优控制stochastic optimal control
- 粒子滤波 Particle Filter
- 采样理论 sampling theory
统计代写| 假设检验作业代写Hypothesis testing代考|Graphing Type I and Type II Errors
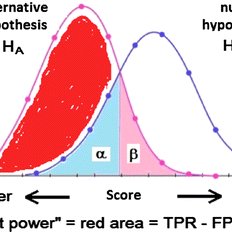
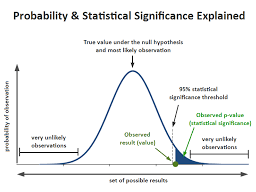
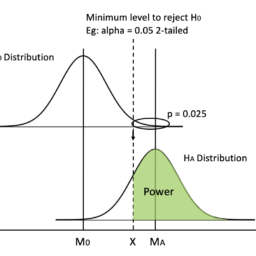
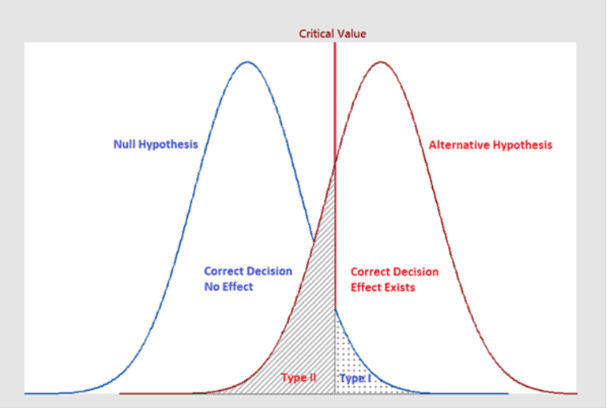
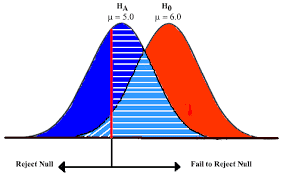
The graph below illustrates the two types of errors using two sampling distributions. The critical region line represents the point at which you reject or fail to reject the null hypothesis. Of course, when you perform the hypothesis test, you don’t know which hypothesis is correct. And, the properties of the distribution for the alternative hypothesis are usually unknown. However, use this graph to understand the general nature of these errors and how they are related.
The distribution on the left represents the null hypothesis. When the null hypothesis is correct, you only need to worry about Type I errors, which is the shaded portion of the null hypothesis distribution. The rest of the null distribution shows the correct decision of failing to reject the null.
On the other hand, when the alternative hypothesis is right, you need to worry about Type II errors. The shaded region on the alternative hypothesis distribution represents the Type II error rate. The rest of the alternative distribution depicts the probability of correctly detecting an effect- which is statistical power.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|Is One Error Worse Than the Other?
As you’ve seen, the nature of the two types of error, their causes, and the certainty of their rates of occurrence are all very different.
A common question is whether one type of error is worse than the other? Statisticians designed hypothesis tests to control Type I errors while Type II errors are much less defined. Consequently, many statisticians state that it is better to fail to detect an effect when it exists than to conclude an effect exists when it doesn’t. In other words, there is a tendency to assume that Type I errors are worse.
However, reality is more complicated than that. You should carefully consider the consequences of each type of error for your specific test.
Suppose you are assessing the strength of a new jet engine part that is under consideration. People’s lives are riding on the part’s strength. A false negative in this scenario merely means that the part is strong enough, but the test fails to detect it. This outcome does not put anyone’s life at risk. On the other hand, Type I errors are worse in this situation because they indicate the part is strong enough when it is not.
Now suppose that the jet engine part is already in use, but there are concerns about it failing. In this case, you want the test to be more sensitive to detecting problems even at the risk of false positives. Type
II errors are worse in this scenario because the test fails to detect the problem and leave these problematic parts in use for longer.
Using hypothesis tests effectively requires that you understand their error rates. By setting the significance level and estimating your test’s power, you can manage both error rates so they meet your requirements.
In the next section, we’ll focus on power analysis, a critical process for managing Type II errors before you begin collecting data.
假设检验代写
统计代写| 假设检验作业代写HYPOTHESIS TESTING代考|GRAPHING TYPE I AND TYPE II ERRORS
下图说明了使用两种抽样分布的两种类型的错误。临界区线表示您拒绝或未能拒绝原假设的点。当然,当您执行假设检验时,您不知道哪个假设是正确的。而且,备择假设的分布属性通常是未知的。但是,请使用此图表来了解这些错误的一般性质以及它们之间的关系。
左边的分布代表零假设。当原假设正确时,您只需要担心 I 类错误,即原假设分布的阴影部分。零分布的其余部分显示了未能拒绝零的正确决定。
另一方面,当备择假设正确时,您需要担心 II 型错误。备择假设分布上的阴影区域代表 II 类错误率。替代分布的其余部分描述了正确检测效果的概率 – 这是统计功效。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|IS ONE ERROR WORSE THAN THE OTHER?
如您所见,这两种错误的性质、原因以及发生率的确定性都非常不同。
一个常见的问题是,一种错误是否比另一种更糟糕?统计学家设计了假设检验来控制 I 类错误,而 II 类错误的定义要少得多。因此,许多统计学家表示,与其在不存在效果时断定存在效果,不如在效果存在时未能检测到效果。换句话说,有一种趋势是假设 I 类错误更糟。
然而,现实远比这复杂。对于特定测试,您应该仔细考虑每种错误类型的后果。
假设您正在评估正在考虑的新喷气发动机部件的强度。人们的生活是依靠零件的力量。在这种情况下,假阴性仅意味着该部件足够坚固,但测试无法检测到它。这一结果不会危及任何人的生命。另一方面,在这种情况下,I 类错误更严重,因为它们表明零件足够坚固,而实际上它不是。
现在假设喷气发动机部件已经在使用,但有人担心它会失败。在这种情况下,您希望测试对检测问题更加敏感,即使存在误报的风险。类型
在这种情况下,II 错误更严重,因为测试无法检测到问题并让这些有问题的部件使用更长时间。
有效地使用假设检验需要您了解它们的错误率。通过设置显着性水平和估计测试的功效,您可以管理这两种错误率,使其满足您的要求。
在下一节中,我们将重点介绍功耗分析,这是在开始收集数据之前管理 II 类错误的关键过程。

统计代写| 假设检验作业代写Hypothesis testing代考|Population Parameters vs. Sample Statistics 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析(Numerical Analysis),又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。