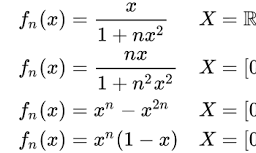如果你也在 怎样代写统计Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计Statistics是数学的一个分支,涉及到矢量空间和线性映射。它包括对线、面和子空间的研究,也涉及所有向量空间的一般属性。
统计学Statistics是一门关于发展和研究收集、分析、解释和展示经验数据的方法的科学。统计Statistics是一个高度跨学科的领域;统计Statistics的研究几乎适用于所有的科学领域,各科学领域的研究问题促使新的统计方法和理论的发展。在开发方法和研究支撑这些方法的理论时,统计学家利用了各种数学和计算工具。
统计Statistics领域的两个基本概念是不确定性和突变。我们在科学(或更广泛的生活)中遇到的许多情况,其结果是不确定的。在某些情况下,不确定性是因为有关的结果尚未确定(例如,我们可能不知道明天是否会下雨),而在其他情况下,不确定性是因为虽然结果已经确定,但我们并不知道(例如,我们可能不知道我们是否通过了某项考试)。
my-assignmentexpert™ 统计Statistics作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计Statistics作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在统计Statistics代写方面经验极为丰富,各种统计Statistics相关的作业也就用不着 说。
我们提供的统计Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Date Analysis数据分析
- Actuarial Science 精算科学
- Bayesian Statistics 贝叶斯统计
- Generalized Linear Model 广义线性模型
- Macroeconomic statistics 宏观统计学
- Microeconomic statistics 微观统计学
- Logistic regression 逻辑回归
- linear regression 线性回归
统计作业代写Statistics代考|variation
These steps are fairly simple using statistical software, but we should say a little more about the second step: choosing a fit measure to compare LRMs. The automated procedures typically rely on $p$-values, nested $F$-tests, or information criterion measures (AIC or BIC; see Chapter 6) to choose the best fitting model. But analysts should also consider other measures, such as the adjusted $R^{2}$ and RMSE. Looking for the largest adjusted $R^{2}$ or the smallest RMSE from among a set of nested models is a reasonable step since, assuming we wish to make good predictions and find strong statistical associations, we’d like to have the most explained variance or the least amount of variation among the residuals.
Another common measure of model fit related to the others is called Mallow’s $C_{p}{ }^{34}$ An important feature of this measure is that it is minimized when the LRM includes only those slope coefficients below a certain $p$-value threshold (e.g., $p<0.05$ ). The formula for Mallow’s $C_{p}$ is shown in Equation 12.8.
$$
C_{p}=\frac{\operatorname{SSE}(p)}{\operatorname{MSE}(k)}-[n-2(p-1)]
$$
where $p=$ number of explanatory variables in the restricted model.
The $\operatorname{SSE}(p)$ is from the restricted model and the $\operatorname{MSE}(k)$ is from the full model. Smaller values of Mallow’s $C_{p}$ designate models that fit the data better. Using this measure does not require a model with all the explanatory variables and some model nested in it. It may include any model that uses subsets of the explanatory variables as long as at least one is nested within another. Mallow’s $C_{p}$ is used most often, though, to compare the full model with various models nested within it.
统计作业代写STATISTICS代考|automated procedures
The lesson from using these procedures is that some of them, such as backward selection, are reasonable tools if the goal is to develop a model that includes the set of explanatory variables that offers the best predictive power. But they cannot substitute for a good theoretical or conceptual model that
not only predicts the outcome variable but, more importantly, explains why it is associated with the explanatory variables. ${ }^{36}$ Automated procedures may also provide misleading results because they are designed to fit the sample data, thus overstating how precise the results appear to be when we wish to make inferences to the population from which the sample was drawn. ${ }^{37}$ This is why many statisticians and data scientists recommend splitting the sample first and then testing the model on both sets. Better yet, use a training dataset to fine-tune the model and then validate it using a testing dataset.
Some other reasons to avoid certain automated procedures include the following:
- The model’s $R^{2}$ values are biased;
- The coefficients’ confidence intervals are biased (they are too narrow);
- The $p$-values are not meaningful-if they’re ever particularly meaningful (see the section on best statistical practices in Chapter 1)without complicated corrections;
- The procedures have problems when collinearity exists among the explanatory variables (see Chapter 10);
- Some of the tests used to compare models (e.g., nested F-tests) are supposed to be used only with pre-specified models; and
- They make us lazy and overconfident: we should focus on the conceptual model and not rely so much on statistical software to make decisions for us.
统计作业代写STATISTICS代考|VARIATION
这些步骤使用统计软件相当简单,但我们应该多说一点关于第二步:选择适合的度量来比较 LRM。自动化程序通常依赖于p-值,嵌套F-测试或信息标准测量(AIC 或 BIC;参见第 6 章)来选择最佳拟合模型。但分析师还应该考虑其他措施,例如调整后的R2和 RMSE。寻找最大的调整R2或一组嵌套模型中最小的 RMSE 是一个合理的步骤,因为假设我们希望做出良好的预测并找到强大的统计关联,我们希望得到解释最多的方差或残差之间的最小变化量。
与其他模型相关的另一种常见的模型拟合度量称为 Mallow’sCp34该度量的一个重要特征是,当 LRM 仅包含低于某个特定值的斜率系数时,它会被最小化。p-值阈值(例如,p<0.05)。马洛的公式Cp如公式 12.8 所示。
Cp=上证所(p)MSE(到)−[n−2(p−1)]
在哪里p=受限模型中的解释变量数。
这上证所(p)来自受限模型和MSE(到)来自完整模型。较小的 Mallow 值Cp指定更适合数据的模型。使用此度量不需要包含所有解释变量的模型和嵌套在其中的某些模型。它可以包括使用解释变量子集的任何模型,只要至少一个嵌套在另一个中即可。锦葵的Cp但是,最常用于将完整模型与嵌套在其中的各种模型进行比较。
统计作业代写STATISTICS代考|AUTOMATED PROCEDURES
使用这些程序的教训是,如果目标是开发一个模型,其中包括提供最佳预测能力的一组解释变量,那么其中一些程序(例如向后选择)是合理的工具。但它们不能替代一个好的理论或概念模型
不仅预测结果变量,更重要的是,解释了为什么它与解释变量相关联。36自动化程序也可能提供误导性结果,因为它们旨在拟合样本数据,从而夸大了当我们希望对抽取样本的总体进行推断时结果的精确程度。37这就是为什么许多统计学家和数据科学家建议先拆分样本,然后在两组上测试模型的原因。更好的是,使用训练数据集对模型进行微调,然后使用测试数据集对其进行验证。
避免某些自动化程序的其他一些原因包括:
- 该模型的R2价值观有偏差;
- 系数的置信区间有偏差(它们太窄);
- 这p- 值没有意义——如果它们特别有意义(参见第 1 章中关于最佳统计实践的部分)没有复杂的修正;
- 当解释变量之间存在共线性时,程序会出现问题(见第 10 章);
- 一些用于比较模型的检验(例如嵌套 F 检验)应该只用于预先指定的模型;和
- 它们让我们变得懒惰和过度自信:我们应该专注于概念模型,而不是过于依赖统计软件来为我们做决定。
统计作业代写Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
matlab代写
MATLAB是一个编程和数值计算平台,被数百万工程师和科学家用来分析数据、开发算法和创建模型。
MATLAB is a programming and numeric computing platform used by millions of engineers and scientists to analyze data, develop algorithms, and create models.
统计代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
统计作业代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
my-assignmentexpert™这边统计代写的质量怎么样?保不保分?靠不靠谱? 一般能写到多少分?
各国各学校的学术标准都有所差异,即使是统计作业,给分也存在一定的主观性因素,有时Teacher和TA的改分并不能够做到完全公正,所有的作业分数都存在一定的运气成分,TA对于步骤把控的严格程度可能和给分的TA今天的心情以及他的性格正相关。一般情况下,MY-ASSIGNMENTEXPERT™出品的作业平均正确率在93%以上。
我在MY-ASSIGNMENTEXPERT™这里购买了代写服务,然后最后这门课的成绩挂了怎么办?
若是因为各种因素结合导致在此购买的统计作业的成绩未达到事先指定的标准,MY-ASSIGNMENTEXPERT™承诺免费重写/修改,并且无条件退款。
最快什么时候写完? 很急的任务可以做吗?
最急的统计论文,可在24小时以内完成,加急的论文价格会比普通的订单稍贵,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计quiz和统计exam代考,在写手档期ok的情况下,可以在下单之后一小时之内进行,不过不提倡这样临时找人,因为加急的quiz和exam代考价格会比普通的订单贵更重要的是可能找不到人,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计assignment,在写手档期ok的情况下,可以在下单之后三小时之内完成,价格在一般的assignment基础上收一个加急费用,如果一份assignment发下来不确定自己能不能完成也能提前和我们联系,报价是不收取任何费用的,如果后续有需要,也方便我们安排写手档期。