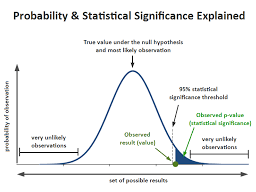
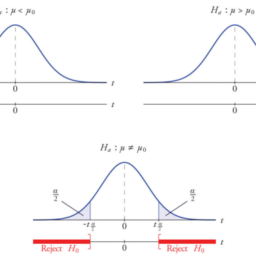
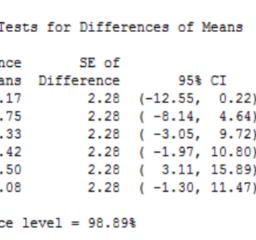
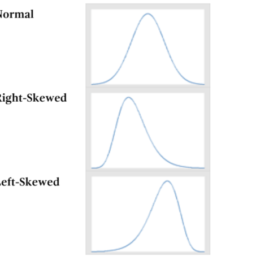
如果你也在 怎样代写假设检验Hypothesis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。假设检验Hypothesis是假设检验是统计学中的一种行为,分析者据此检验有关人口参数的假设。分析师采用的方法取决于所用数据的性质和分析的原因。假设检验是通过使用样本数据来评估假设的合理性。
统计假设检验是一种统计推断方法,用于决定手头的数据是否充分支持某一特定假设。
空白假设的早期选择
Paul Meehl认为,无效假设的选择在认识论上的重要性基本上没有得到承认。当无效假设是由理论预测的,一个更精确的实验将是对基础理论的更严格的检验。当无效假设默认为 “无差异 “或 “无影响 “时,一个更精确的实验是对促使进行实验的理论的一个较不严厉的检验。
1778年:皮埃尔-拉普拉斯比较了欧洲多个城市的男孩和女孩的出生率。他说 “很自然地得出结论,这些可能性几乎处于相同的比例”。因此,拉普拉斯的无效假设是,鉴于 “传统智慧”,男孩和女孩的出生率应该是相等的 。
1900: 卡尔-皮尔逊开发了卡方检验,以确定 “给定形式的频率曲线是否能有效地描述从特定人群中抽取的样本”。因此,无效假设是,一个群体是由理论预测的某种分布来描述的。他以韦尔登掷骰子数据中5和6的数量为例 。
1904: 卡尔-皮尔逊提出了 “或然性 “的概念,以确定结果是否独立于某个特定的分类因素。这里的无效假设是默认两件事情是不相关的(例如,疤痕的形成和天花的死亡率)。[16] 这种情况下的无效假设不再是理论或传统智慧的预测,而是导致费雪和其他人否定使用 “反概率 “的冷漠原则。
my-assignmentexpert™ 假设检验Hypothesis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的假设检验Hypothesis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此假设检验Hypothesis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在假设检验Hypothesis作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在假设检验Hypothesis代写方面经验极为丰富,各种假设检验HypothesisProcess相关的作业也就用不着 说。
我们提供的假设检验Hypothesis及其相关学科的代写,服务范围广, 其中包括但不限于:
- 时间序列分析Time-Series Analysis
- 马尔科夫过程 Markov process
- 随机最优控制stochastic optimal control
- 粒子滤波 Particle Filter
- 采样理论 sampling theory
统计代写| 假设检验作业代写Hypothesis testing代考|Continuous Data
I’ve already defined continuous data in this book. But I’ll do so again so it’s easy to compare to the other data types. The t-tests we’ve been looking at require continuous data, but there are other tests you can perform on continuous data.
Continuous data can take on any numeric value, and it can be meaningfully divided into smaller increments, including fractional and decimal values. There is an infinite number of possible values between any two values. You often measure a continuous variable on a scale. For example, when you measure height, weight, and temperature, you have continuous data.
With continuous variables, you can use hypothesis tests to assess the mean, median, standard deviation, distribution, and correlations of the data.
When you collect continuous data, you usually get more bang for your data buck than for discrete data. The two key advantages of continuous data are that you can:
- Draw conclusions with a smaller sample size.
- Use a wider variety of analyses, which allows you to learn more.
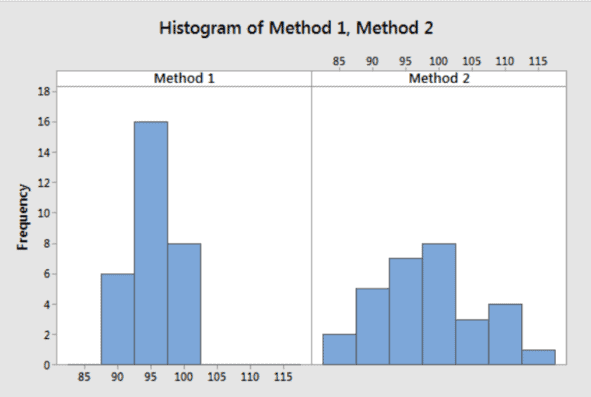
Suppose we have two production methods and our goal is to determine which one produces a stronger product. To evaluate the two methods, we draw a random sample of 30 products from each production line and measure each unit’s strength. Before performing any analyses, it’s always smart to graph the data because it provides an excellent overview.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|Binary Data
Binary data can have only two values. If you can place an observation into only two categories, you have a binary variable. Statisticians also refer to binary data as both dichotomous data and indicator variables. For example, pass/fail, male/female, and the presence/absence of a characteristic are all binary data. Quality improvement practitioners often use binary data to record defective units.
Binary data are useful for calculating proportions or percentages, such as the proportion of defective products in a sample. You simply take the number of defective products and divide by the sample size. Hypothesis tests that assess proportions require binary data and allow you to use sample data to make inferences about the proportions of populations.
Suppose we take a random sample of our product from two production lines. Inspectors evaluate each product and either accept or reject it. We can use hypothesis tests to compare the proportion of defects between samples.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|Count Data
Count data can have only non-negative integers (e.g., $0,1,2$, etc.). In statistics, we often model count data using the Poisson distribution. Poisson data are a count of the presence of a characteristic, result, or activity over a constant amount of time, area, or other length of observation. For example, you can use count data to record the number of defects per item or defective units per batch. With Poisson data, you can assess the rate of occurrence.
Imagine that we receive shipments of parts from two different suppliers. Each supplier sends the parts in the same sized batch. Inspectors count the number of defective items per batch. We need to determine whether one supplier produces fewer defects per batch than the other supplier.
假设检验代写
统计代写| 假设检验作业代写HYPOTHESIS TESTING代考|CONTINUOUS DATA
我已经在本书中定义了连续数据。但我会再次这样做,以便与其他数据类型进行比较。我们一直在研究的 t 检验需要连续数据,但是您可以对连续数据执行其他测试。
连续数据可以采用任何数值,并且可以有意义地划分为更小的增量,包括小数和小数。任意两个值之间存在无限多个可能的值。你经常在一个尺度上测量一个连续变量。例如,当您测量身高、体重和温度时,您有连续的数据。
对于连续变量,您可以使用假设检验来评估数据的均值、中位数、标准差、分布和相关性。
当您收集连续数据时,您的数据降压通常比离散数据获得更多收益。连续数据的两个主要优点是您可以:
- 用较小的样本量得出结论。
- 使用更广泛的分析,让您了解更多。
假设我们有两种生产方法,我们的目标是确定哪一种生产更强的产品。为了评估这两种方法,我们从每条生产线上随机抽取 30 个产品样本,并测量每个单元的强度。在执行任何分析之前,绘制数据图表总是很明智的,因为它提供了一个很好的概览。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|BINARY DATA
二进制数据只能有两个值。如果您只能将观察分为两类,则您有一个二元变量。统计学家还将二进制数据称为二分数据和指标变量。例如,通过/失败、男性/女性以及特征的存在/不存在都是二进制数据。质量改进从业者经常使用二进制数据来记录有缺陷的单元。
二进制数据可用于计算比例或百分比,例如样本中缺陷产品的比例。您只需将缺陷产品的数量除以样本量即可。评估比例的假设检验需要二进制数据,并允许您使用样本数据来推断总体比例。
假设我们从两条生产线上随机抽取我们的产品样本。检查员评估每个产品并接受或拒绝它。我们可以使用假设检验来比较样本之间的缺陷比例。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|COUNT DATA
计数数据只能有非负整数和.G.,$0,1,2$,和吨C.. 在统计学中,我们经常使用泊松分布对计数数据进行建模。泊松数据是在恒定的时间、区域或其他观察长度内存在的特征、结果或活动的计数。例如,您可以使用计数数据来记录每个项目的缺陷数或每个批次的缺陷单元数。使用泊松数据,您可以评估发生率。
想象一下,我们收到来自两个不同供应商的零件发货。每个供应商都以相同大小的批次发送零件。检查员计算每批有缺陷的物品数量。我们需要确定一个供应商每批次产生的缺陷是否比另一个供应商少。

统计代写| 假设检验作业代写Hypothesis testing代考|Population Parameters vs. Sample Statistics 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析(Numerical Analysis),又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。