如果你也在 怎样代写假设检验Hypothesis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。假设检验Hypothesis是假设检验是统计学中的一种行为,分析者据此检验有关人口参数的假设。分析师采用的方法取决于所用数据的性质和分析的原因。假设检验是通过使用样本数据来评估假设的合理性。
统计假设检验是一种统计推断方法,用于决定手头的数据是否充分支持某一特定假设。
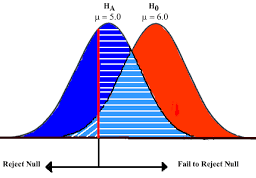
空白假设的早期选择
Paul Meehl认为,无效假设的选择在认识论上的重要性基本上没有得到承认。当无效假设是由理论预测的,一个更精确的实验将是对基础理论的更严格的检验。当无效假设默认为 “无差异 “或 “无影响 “时,一个更精确的实验是对促使进行实验的理论的一个较不严厉的检验。
1778年:皮埃尔-拉普拉斯比较了欧洲多个城市的男孩和女孩的出生率。他说 “很自然地得出结论,这些可能性几乎处于相同的比例”。因此,拉普拉斯的无效假设是,鉴于 “传统智慧”,男孩和女孩的出生率应该是相等的 。
1900: 卡尔-皮尔逊开发了卡方检验,以确定 “给定形式的频率曲线是否能有效地描述从特定人群中抽取的样本”。因此,无效假设是,一个群体是由理论预测的某种分布来描述的。他以韦尔登掷骰子数据中5和6的数量为例 。
1904: 卡尔-皮尔逊提出了 “或然性 “的概念,以确定结果是否独立于某个特定的分类因素。这里的无效假设是默认两件事情是不相关的(例如,疤痕的形成和天花的死亡率)。[16] 这种情况下的无效假设不再是理论或传统智慧的预测,而是导致费雪和其他人否定使用 “反概率 “的冷漠原则。
my-assignmentexpert™ 假设检验Hypothesis作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的假设检验Hypothesis作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此假设检验Hypothesis作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在假设检验Hypothesis作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在假设检验Hypothesis代写方面经验极为丰富,各种假设检验HypothesisProcess相关的作业也就用不着 说。
我们提供的假设检验Hypothesis及其相关学科的代写,服务范围广, 其中包括但不限于:
- 时间序列分析Time-Series Analysis
- 马尔科夫过程 Markov process
- 随机最优控制stochastic optimal control
- 粒子滤波 Particle Filter
- 采样理论 sampling theory
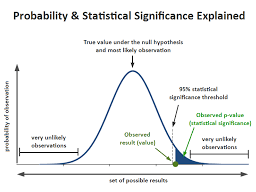
统计代写|假设检验作业代写Hypothesis testing代考|P-values Are NOT an Error Rate
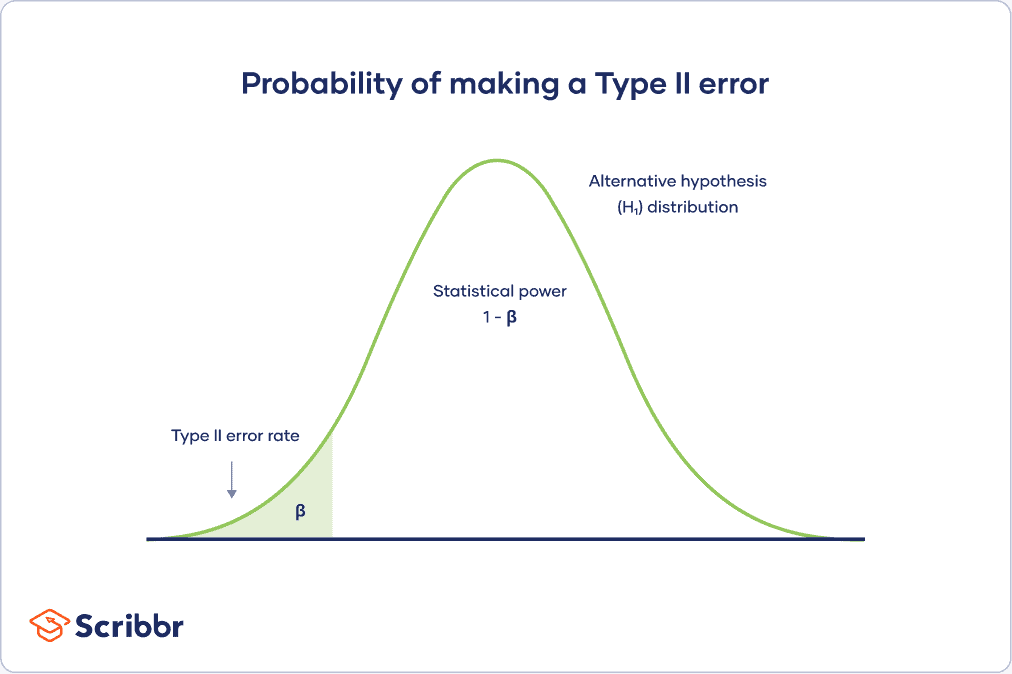
Unfortunately, p-values are frequently misinterpreted. A common mistake is that they represent the likelihood of rejecting a null hypothesis that is actually true (Type I error). The idea that p-values are the probability of making a mistake is WRONG!
You can’t use p-values to calculate the error rate directly for several reasons.
First, p-value calculations assume that the null hypothesis is correct. Thus, from the p-value’s point of view, the null hypothesis is $100 \%$ true. Remember, p-values assume that the null is true, and sampling error caused the observed sample effect.
Second, p-values tell you how consistent your sample data are with a true null hypothesis. However, when your data are very inconsistent with the null hypothesis, p-values can’t determine which of the following two possibilities is more probable:
- The null hypothesis is true, but your sample is unusual due to random sampling error.
- The null hypothesis is false.
To figure out which option is right, you must apply expert knowledge of the study area and, very importantly, assess the results of similar studies.
Going back to our medication study, let’s highlight the correct and incorrect way to interpret the p-value of $0.03$ :
- Correct: Assuming the medication has zero effect in the population, you’d obtain the sample effect, or larger, in $3 \%$ of studies because of random sample error.
- Incorrect: There’s a $3 \%$ chance of making a mistake by rejecting the null hypothesis.
Yes, I realize that the incorrect definition seems more straightforward, and that’s why it is so common. Unfortunately, using this definition gives you a false sense of security, as I’ll show you next.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|What Is the True Error Rate?
The difference between the correct and incorrect interpretation is not just a matter of wording. There is a fundamental difference in the amount of evidence against the null hypothesis that each definition implies.
The p-value for our medication study is $0.03$. If you interpret that pvalue as a $3 \%$ chance of making a mistake by rejecting the null hypothesis, you’d feel like you’re on pretty safe ground. However, after reading this section, you should realize that p-values are not an error rate, and you can’t interpret them this way.
If the p-value is not the error rate for our study, what is the error rate? Hint: It’s higher!
As I explained earlier, you can’t directly calculate an error rate based on a p-value, at least not using the frequentist approach that produces p-values. However, you can estimate error rates associated with p-values by using Bayesian methodologies and simulation studies.
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|Why Are P-values Misinterpreted So Frequently?
P-values are commonly misinterpreted. It’s a very slippery concept that requires a lot of background knowledge to understand. Not surprisingly, I’ve received many questions about p-values in hypothesis testing over the years. However, one question stands out. Why are pvalue misinterpretations so prevalent? I answer that question in this section and help you avoid making the same mistakes.
Historical Events Made P-values Confusing
The problem of misinterpreting $\mathrm{p}$-values has existed for nearly a century. The origins go back to two rival camps in the early days of hypothesis testing. On one side, we have Ronald Fisher with his measures of evidence approach (p-values). And, on the other side, we have Jerzy Neyman and Egon Pearson with their error rate method (alpha). Fisher believed that you could use sample data to learn about a population. However, Neyman and Pearson thought that you couldn’t learn from individual studies but only a long series of hypothesis tests.
Textbook publishers and statistics courses have squished together these two incompatible approaches. Today, the familiar hypothesis testing procedure of comparing p-values to alphas seems to fit together perfectly. However, they’re based on irreconcilable methods.
I could say a lot about this forced merger. For the topic of this section, an important outcome is that p-values became associated with the Type I error rate, which is incorrect. A p-value is NOT an error rate, but alpha IS an error rate. By directly comparing the two values in a hypothesis test, it’s easy to think they’re both error rates. This misconception leads to the most common misinterpretations of p-values.
Fisher spent decades of his life trying to clarify the misunderstanding but to no avail.
假设检验代写
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|P-VALUES ARE NOT AN ERROR RATE
不幸的是,p 值经常被误解。一个常见的错误是它们代表了拒绝实际上为真的原假设的可能性吨和p和一世和rr○r. p 值是犯错概率的想法是错误的!
出于多种原因,您不能使用 p 值直接计算错误率。
首先,p 值计算假设原假设是正确的。因此,从 p 值的角度来看,原假设是100%真的。请记住,p 值假设 null 为真,并且采样误差导致了观察到的样本效应。
其次,p 值告诉您样本数据与真零假设的一致性程度。但是,当您的数据与原假设非常不一致时,p 值无法确定以下两种可能性中的哪一种更可能:
- 原假设为真,但由于随机抽样误差,您的样本不寻常。
- 原假设是错误的。
要确定哪个选项是正确的,您必须运用研究领域的专业知识,并且非常重要的是,评估类似研究的结果。
回到我们的药物研究,让我们强调解释 p 值的正确和错误方法0.03:
- 正确:假设药物对人群的影响为零,您将获得样本效应,或更大,在3%由于随机样本误差的研究。
- 错误:有一个3%拒绝原假设出错的概率。
是的,我意识到不正确的定义似乎更直接,这就是它如此普遍的原因。不幸的是,使用这个定义会给你一种错误的安全感,接下来我将向你展示。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|WHAT IS THE TRUE ERROR RATE?
正确和错误解释之间的区别不仅仅是措辞问题。每个定义所暗示的反对零假设的证据数量存在根本差异。
我们药物研究的 p 值为0.03. 如果您将该 pvalue 解释为3%通过拒绝零假设来犯错误的机会,你会觉得你在相当安全的基础上。但是,阅读本节后,您应该意识到 p 值不是错误率,您不能这样解释它们。
如果 p 值不是我们研究的错误率,那么错误率是多少?提示:更高!
正如我之前解释的,您不能直接根据 p 值计算错误率,至少不能使用产生 p 值的频率论方法。但是,您可以使用贝叶斯方法和模拟研究来估计与 p 值相关的错误率。
统计代写|假设检验作业代写HYPOTHESIS TESTING代考|WHY ARE P-VALUES MISINTERPRETED SO FREQUENTLY?
P 值通常被误解。这是一个非常模糊的概念,需要大量的背景知识才能理解。毫不奇怪,这些年来我收到了很多关于假设检验中 p 值的问题。但是,有一个问题很突出。为什么 pvalue 误解如此普遍?我将在本节中回答这个问题,并帮助您避免犯同样的错误。
历史事件使 P 值混乱
误解的问题p价值观已经存在了近一个世纪。起源可以追溯到假设检验早期的两个敌对阵营。一方面,我们有罗纳德·费舍尔(Ronald Fisher)的证据测量方法p−v一种一世你和s. 另一方面,我们有 Jerzy Neyman 和 Egon Pearson 的错误率方法一种一世pH一种. 费舍尔认为您可以使用样本数据来了解总体。然而,内曼和皮尔森认为,你不能从个别研究中学习,而只能从一长串的假设检验中学习。
教科书出版商和统计学课程将这两种不相容的方法挤在一起。今天,将 p 值与 alpha 进行比较的常见假设检验程序似乎完美地结合在一起。但是,它们基于不可调和的方法。
关于这次强制合并,我可以说很多。对于本节的主题,一个重要的结果是 p 值与 I 类错误率相关联,这是不正确的。p 值不是错误率,但 alpha 是错误率。通过直接比较假设检验中的两个值,很容易认为它们都是错误率。这种误解导致对 p 值最常见的误解。
费舍尔花了几十年的时间试图澄清误解,但无济于事。

统计代写| 假设检验作业代写Hypothesis testing代考|Population Parameters vs. Sample Statistics 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析(Numerical Analysis),又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。