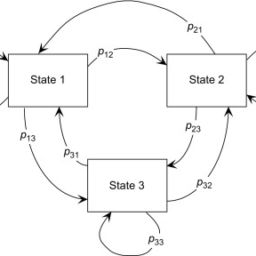
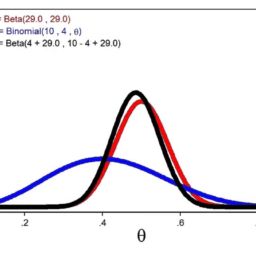
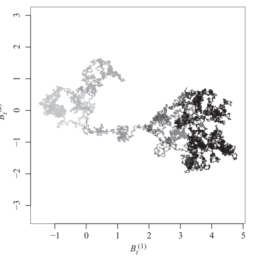
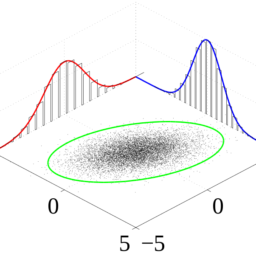
如果你也在 怎样统计计算Statistical Computing这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计计算Statistical Computing是统计学和计算机科学之间的纽带。它意味着通过使用计算方法来实现的统计方法。它是统计学的数学科学所特有的计算科学(或科学计算)的领域。这一领域也在迅速发展,导致人们呼吁应将更广泛的计算概念作为普通统计教育的一部分。与传统统计学一样,其目标是将原始数据转化为知识,[2]但重点在于计算机密集型统计方法,例如具有非常大的样本量和非同质数据集的情况。
许多统计建模和数据分析技术可能难以掌握和应用,因此往往需要使用计算机软件来帮助实施大型数据集并获得有用的结果。S-Plus是公认的最强大和最灵活的统计软件包之一,它使用户能够应用许多统计方法,从简单的回归到时间序列或多变量分析。该文本广泛涵盖了许多基本的和更高级的统计方法,集中于图形检查,并具有逐步说明的特点,以帮助非统计学家充分理解方法。
my-assignmentexpert™统计计算Statistical Computing作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计计算Statistical Computing作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计计算Statistical Computing作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计计算Statistical Computing作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计计算Statistical Computing代写服务。我们的专家在统计计算Statistical Computing代写方面经验极为丰富,各种统计计算Statistical Computing相关的作业也就用不着 说。
我们提供的统计计算Statistical Computing及其相关学科的代写,服务范围广, 其中包括但不限于:
- 随机微积分 Stochastic calculus
- 随机分析 Stochastic analysis
- 随机控制理论 Stochastic control theory
- 微观经济学 Microeconomics
- 数量经济学 Quantitative Economics
- 宏观经济学 Macroeconomics
- 经济统计学 Economic Statistics
- 经济学理论 Economic Theory
- 计量经济学 Econometrics
统计代写
数学代写|统计计算作业代写Statistical Computing代考|Computing Monte Carlo estimates
We can rewrite equation (3.7) as the following very simple algorithm.
Algorithm 3.8 (Monte Carlo estimate)
input:
a function $f$ with values in $\mathbb{R}$
$N \in \mathbb{N}$
randomness used:
i.i.d. copies $\left(X_{j}\right){j \in \mathbb{N}}$ of $X$ output: an estimate $Z{N}^{\mathrm{MC}}$ for $\mathbb{E}(f(X))$
1: $s \leftarrow 0$
2: for $j=1,2, \ldots, N$ do
3: generate $X_{j}$, with the same distribution as $X$ has
4: $\quad s \leftarrow s+f\left(X_{j}\right)$
5: end for
6: return $s / N$
Ignoring the negligible computational cost for the initial assignment of the variable $s$ and of the final division by $N$, the execution time of algorithm $3.8$ is proportional to $N$. On the other hand, by the law of large numbers, we know that the estimate $Z_{N}^{\mathrm{MC}}$ converges to the correct value $\mathbb{E}(f(X))$ only as $N$ increases, and thus the error decreases as $N$ increases. For this reason, choosing the sample size $N$ in algorithm $3.8$ involves a trade-off between computational cost and accuracy of the result. We will discuss this trade-off in more detail in the following section.
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|Monte Carlo error
Since the estimate $Z_{N}^{\mathrm{MC}}$ from definition $3.7$ and algorithm $3.8$ is random, the Monte Carlo error $Z_{N}^{\mathrm{MC}}-\mathbb{E}(f(X))$ is also random. To quantify the magnitude of this random error, we use the concepts of bias and mean squared error from statistics.
Definition 3.9 The bias of an estimator $\hat{\theta}=\hat{\theta}(X)$ for a parameter $\theta$ is given by
$$
\operatorname{bias}(\hat{\theta})=\mathbb{E}{\theta}(\hat{\theta}(X)-\theta)=\mathbb{E}{\theta}(\hat{\theta}(X))-\theta
$$
where the subscript $\theta$ in the expectations on the right-hand side indicates that the sample $X$ in the expectation comes from the distribution with true parameter $\theta$.
Since the bias as given in definition $3.9$ depends on the value of $\theta$, sometimes the notation $\operatorname{bias}_{\theta}(\hat{\theta})$ is used to indicate the dependence on $\theta$. While the bias measures how far off the estimate is on average, a small value of the bias does not necessarily indicate a useful estimator: even when the estimator is correct on average, the actual values of the estimator may fluctuate so wildly around $\theta$ that they are not useful in practice. For this reason, the size of fluctuations of an estimator is considered.
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|Choice of sample size
The error bound from proposition $3.14$ can be used to guide the choice of sample size $N$ in the Monte Carlo method from algorithm 3.8. The most direct way to use the proposition in this context is to use equation (3.8) to determine the error of the result after a run of algorithm $3.8$ has completed. If the error is too large, another run with a larger value of $N$ can be started, until the required precision is reached. The bound of equation (3.8) can only be applied directly, if the sample variance $\operatorname{Var}(f(X))$ is known. If the sample variance is unknown, it can be estimated together during the computation of the Monte Carlo estimate: The estimate $Z_{N}^{\mathrm{MC}}$ has mean squared error
$$
\operatorname{MSE}\left(Z_{N}^{\mathrm{MC}}\right)=\frac{\operatorname{Var}(f(X))}{N} \approx \frac{\hat{\sigma}^{2}}{N}
$$
where
$$
\hat{\sigma}^{2}=\frac{1}{N-1} \sum_{j=1}^{N}\left(f\left(X_{j}\right)-Z_{N}^{\mathrm{MC}}\right)^{2}
$$
is the sample variance of the generated values $f\left(X_{1}\right), \ldots, f\left(X_{N}\right)$.
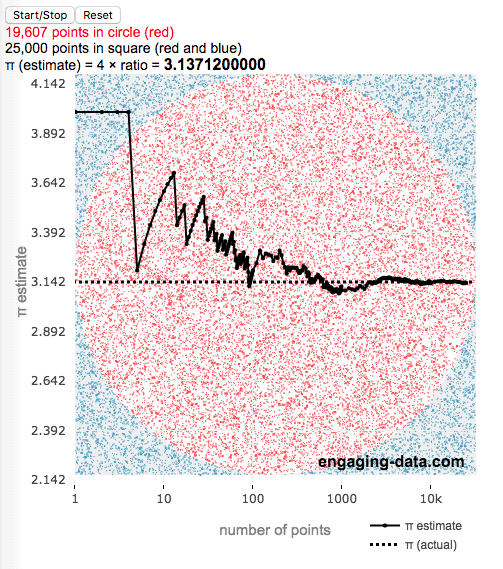
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|COMPUTING MONTE CARLO ESTIMATES
我们可以重写方程3.7作为以下非常简单的算法。
算法 3.8米○n吨和C一种r一世○和s吨一世米一种吨和
输入:
一个函数F与值R
ñ∈ñ
使用的随机性:
Ignoring the negligible computational cost for the initial assignment of the variable $s$ and of the final division by $N$, the execution time of algorithm $3.8$ is proportional to $N$. On the other hand, by the law of large numbers, we know that the estimate $Z_{N}^{\mathrm{MC}}$ converges to the correct value $\mathbb{E}(f(X))$ only as $N$ increases, and thus the error decreases as $N$ increases. For this reason, choosing the sample size $N$ in algorithm $3.8$ 涉及计算成本和结果准确性之间的权衡。我们将在下一节中更详细地讨论这种权衡。
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|MONTE CARLO ERROR
由于估计和ñ米C从定义3.7和算法3.8是随机的,蒙特卡洛误差和ñ米C−和(F(X))也是随机的。为了量化这种随机误差的大小,我们使用统计数据中的偏差和均方误差的概念。
定义 3.9 估计量的偏差θ^=θ^(X)对于一个参数θ由
$$
\operatorname{bias} 给出θ^=\mathbb{E} {\theta}θ^(X-\theta)=\mathbb{E} {\theta}θ^(X)-\theta
$$
其中下标θ右侧的期望值表示样本X期望来自具有真实参数的分布θ.
由于定义中给出的偏差3.9取决于的价值θ, 有时记号偏见θ(θ^)用于表示依赖θ. 虽然偏差衡量的是估计值平均偏离了多远,但偏差的小值并不一定表示一个有用的估计量:即使估计量平均正确,估计量的实际值也可能在θ它们在实践中没有用。为此,要考虑估计量的波动大小。
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|CHOICE OF SAMPLE SIZE
命题的误差界3.14可用于指导样本量的选择ñ在算法 3.8 的蒙特卡洛方法中。在这种情况下使用命题的最直接方法是使用方程3.8在运行算法后确定结果的误差3.8已完成。如果误差太大,再运行一个更大的值ñ可以启动,直到达到所需的精度。方程的界3.8只能直接应用,如果样本方差在哪里(F(X))是已知的。如果样本方差未知,可以在计算 Monte Carlo 估计时一起估计: 估计和ñ米C有均方误差
MSE(和ñ米C)=在哪里(F(X))ñ≈σ^2ñ
在哪里
σ^2=1ñ−1∑j=1ñ(F(Xj)−和ñ米C)2
是生成值的样本方差F(X1),…,F(Xñ).

计量经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
微观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
宏观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写