如果你也在 怎样统计计算Statistical Computing这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计计算Statistical Computing是统计学和计算机科学之间的纽带。它意味着通过使用计算方法来实现的统计方法。它是统计学的数学科学所特有的计算科学(或科学计算)的领域。这一领域也在迅速发展,导致人们呼吁应将更广泛的计算概念作为普通统计教育的一部分。与传统统计学一样,其目标是将原始数据转化为知识,[2]但重点在于计算机密集型统计方法,例如具有非常大的样本量和非同质数据集的情况。
许多统计建模和数据分析技术可能难以掌握和应用,因此往往需要使用计算机软件来帮助实施大型数据集并获得有用的结果。S-Plus是公认的最强大和最灵活的统计软件包之一,它使用户能够应用许多统计方法,从简单的回归到时间序列或多变量分析。该文本广泛涵盖了许多基本的和更高级的统计方法,集中于图形检查,并具有逐步说明的特点,以帮助非统计学家充分理解方法。
my-assignmentexpert™统计计算Statistical Computing作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计计算Statistical Computing作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计计算Statistical Computing作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计计算Statistical Computing作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计计算Statistical Computing代写服务。我们的专家在统计计算Statistical Computing代写方面经验极为丰富,各种统计计算Statistical Computing相关的作业也就用不着 说。
我们提供的统计计算Statistical Computing及其相关学科的代写,服务范围广, 其中包括但不限于:
- 随机微积分 Stochastic calculus
- 随机分析 Stochastic analysis
- 随机控制理论 Stochastic control theory
- 微观经济学 Microeconomics
- 数量经济学 Quantitative Economics
- 宏观经济学 Macroeconomics
- 经济统计学 Economic Statistics
- 经济学理论 Economic Theory
- 计量经济学 Econometrics
统计代写
数学代写|统计计算作业代写Statistical Computing代考|Time discretisation
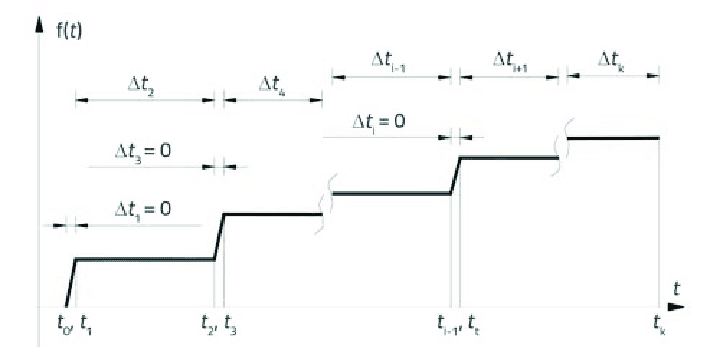
Compared with the situation of discrete-time processes, for example the Markov chains considered in Section 2.3, simulation in continuous-time introduces new challenges. Consider a stochastic process $\left(X_{t}\right){t \in I}$ where $I \subseteq \mathbb{R}$ is a time interval, for example $I=[0, \infty)$ or $I=[0, T]$ for some time horizon $T>0$. Even if the time interval $I$ is bounded, the trajectory $\left(X{t}\right){t \in I}$ consists of uncountably many values. Since computers only have finite storage capacity, it is impossible to store the whole trajectory of a continuous-time process on a computer. Even computing values for all $X{t}$ would take an infinite amount of time. For these reasons, we restrict ourselves to simulate $X$ only for times $t \in I_{n}$ where $I_{n}=\left{t_{1}, t_{2}, \ldots, t_{n}\right} \subset I$ is finite. This procedure is called time discretisation.
In many cases we can simulate the process $X$ by iterating through the times $t_{1}, t_{2}, \ldots, t_{n} \in I_{n}$ : we first simulate $X_{t_{1}}$, next we use the value of $X_{t_{1}}$ to simulate $X_{t_{2}}$, then we use the values $X_{t_{1}}$ and $X_{t_{2}}$ to simulate $X_{t_{3}}$ and so on. The final step in this procedure is to use the values $X_{t_{1}}, \ldots, X_{t_{n-1}}$ to simulate $X_{t_{n}}$. One problem with this approach is that often the distribution of $X_{t_{k}}$ does not only depend on $X_{t_{i}}$ for $i=1,2, \ldots, k-1$, but also on (unknown to us) values $X_{t}$ where $t \notin I_{n}$. For this reason, most continuous-time processes cannot be simulated exactly on a computer and we have to resort to approximate solutions instead. The error introduced by these approximations is called discretisation error.
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|TIME DISCRETISATION
与离散时间过程的情况相比,例如第 2.3 节中考虑的马尔可夫链,连续时间的模拟引入了新的挑战。考虑一个随机过程 $\left(X_{t}\right){t \in I}$ where $I \subseteq \mathbb{R}$ is a time interval, for example $I=[0, \infty)$ or $I=[0, T]$ for some time horizon $T>0$. Even if the time interval $I$ is bounded, the trajectory $\left(X{t}\right){t \in I}$ consists of uncountably many values. Since computers only have finite storage capacity, it is impossible to store the whole trajectory of a continuous-time process on a computer. Even computing values for all $X{t}$ would take an infinite amount of time. For these reasons, we restrict ourselves to simulate $X$ only for times $t \in I_{n}$ where $I_{n}=\left{t_{1}, t_{2}, \ldots, t_{n}\right} \subset I$ 是有限的。这个过程称为时间离散。
很多情况下我们可以模拟这个过程X通过时代的迭代吨1,吨2,…,吨n∈一世n: 我们先模拟X吨1,接下来我们使用X吨1模拟X吨2,然后我们使用值X吨1和X吨2模拟X吨3等等。此过程的最后一步是使用这些值X吨1,…,X吨n−1模拟X吨n. 这种方法的一个问题是,通常X吨到不仅取决于X吨一世为了一世=1,2,…,到−1,而且在你n到n○在n吨○你s价值观X吨在哪里吨∉一世n. 出于这个原因,大多数连续时间过程无法在计算机上精确模拟,我们不得不求助于近似解。这些近似引入的误差称为离散化误差。

计量经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
微观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
宏观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写