如果你也在 怎样代写信息论information theory这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。信息论information theory是对数字信息的量化、存储和通信的科学研究。该领域从根本上由哈里-奈奎斯特和拉尔夫-哈特利在20世纪20年代和克劳德-香农在20世纪40年代的作品建立。
信息论information theory的一个关键衡量标准是熵。熵量化了随机变量的值或随机过程的结果中所涉及的不确定性的数量。例如,确定一个公平的抛硬币的结果(有两个同样可能的结果)比确定一个掷骰子的结果(有六个同样可能的结果)提供的信息要少(熵值较低)。信息论中其他一些重要的衡量标准是相互信息、信道容量、误差指数和相对熵。信息论的重要子领域包括源编码、算法复杂性理论、算法信息论和信息论安全。
my-assignmentexpert™信息论information theory代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的信息论information theory作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此信息论information theory作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在信息论information theory代写方面经验极为丰富,各种信息论information theory相关的作业也就用不着 说。
我们提供的信息论information theory及其相关学科的代写,服务范围广, 其中包括但不限于:
数学代写|信息论作业代写information theory代考|The guessing game
As a motivation for these two compression methods, consider the redundancy in a typical English text file. Such files have redundancy at several levels: for example, they contain the ASCII characters with non-equal frequency; certain consecutive pairs of letters are more probable than others; and entire words can be predicted given the context and a semantic understanding of the text.
To illustrate the redundancy of English, and a curious way in which it could be compressed, we can imagine a guessing game in which an English speaker repeatedly attempts to predict the next character in a text file.
For simplicity, let us assume that the allowed alphabet consists of the 26 upper case letters A , B, C, .., Z and a space ‘-‘. The game involves asking the subject to guess the next character repeatedly, the only feedback being whether the guess is correct or not, until the character is correctly guessed. After a correct guess, we note the number of guesses that were made when the character was identified, and ask the subject to guess the next character in the same way.
One sentence gave the following result when a human was asked to guess a sentence. The numbers of guesses are listed below each character.
T HERE – I S – N O-REVERSE-ON-A-MOTORC Y C LE –
$\begin{array}{lllllllllllllllllllllllllllllllllllll}1 & 1 & 1 & 5 & 1 & 1 & 2 & 1 & 1 & 2 & 1 & 1 & 15 & 1 & 17 & 1 & 1 & 1 & 2 & 1 & 3 & 2 & 1 & 2 & 2 & 7 & 1 & 1 & 1 & 1 & 4 & 1 & 1 & 1 & 1 & 1\end{array}$
Notice that in many cases, the next letter is guessed immediately, in one guess. In other cases, particularly at the start of syllables, more guesses are needed.
数学代写|信息论作业代写information theory代考|Arithmetic codes
When we discussed variable-length symbol codes, and the optimal Huffman algorithm for constructing them, we concluded by pointing out two practical and theoretical problems with Huffman codes (section 5.6).
These defects are rectified by arithmetic codes, which were invented by Elias, by Rissanen and by Pasco, and subsequently made practical by Witten et al. (1987). In an arithmetic code, the probabilistic modelling is clearly separated from the encoding operation. The system is rather similar to the guessing game. The human predictor is replaced by a probabilistic model of the source. As each symbol is produced by the source, the probabilistic model supplies a predictive distribution over all possible values of the next symbol, that is, a list of positive numbers $\left{p_{i}\right}$ that sum to one. If we choose to model the source as producing i.i.d. symbols with some known distribution, then the predictive distribution is the same every time; but arithmetic coding can with equal ease handle complex adaptive models that produce context-dependent predictive distributions. The predictive model is usually implemented in a computer program.
数学代写|信息论作业代写INFORMATION THEORY代考|Further applications of arithmetic coding
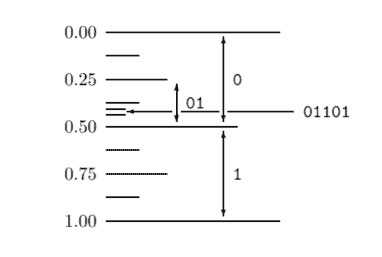
Arithmetic coding not only offers a way to compress strings believed to come from a given model; it also offers a way to generate random strings from a model. Imagine sticking a pin into the unit interval at random, that line having been divided into subintervals in proportion to probabilities $p_{i}$; the probability that your pin will lie in interval $i$ is $p_{i}$.
So to generate a sample from a model, all we need to do is feed ordinary random bits into an arithmetic decoder for that model. An infinite random bit sequence corresponds to the selection of a point at random from the $[0,1)$, so the decoder will then select a string at random from the assumed distribution. This arithmetic method is guaranteed to use very nearly the smallest number of random bits possible to make the selection – an important point in communities where random numbers are expensive! This is not a joke. Large amounts of money are spent on generating random bits in software and hardware. Random numbers are valuable.
A simple example of the use of this technique is in the generation of random bits with a nonuniform distribution $\left{p_{0}, p_{1}\right}$.
信息论代考
数学代写|信息论作业代写INFORMATION THEORY代考|THE GUESSING GAME
作为这两种压缩方法的动机,请考虑典型英文文本文件中的冗余。此类文件在多个级别上具有冗余:例如,它们包含频率不等的 ASCII 字符;某些连续的字母对比其他字母更有可能;并且可以根据上下文和对文本的语义理解来预测整个单词。
为了说明英语的冗余性,以及一种可以压缩它的奇怪方式,我们可以想象一个猜谜游戏,其中一个说英语的人反复尝试预测文本文件中的下一个字符。
为简单起见,我们假设允许的字母表由 26 个大写字母 A、B、C、..、Z 和一个空格“-”组成。游戏涉及要求受试者重复猜测下一个角色,唯一的反馈是猜测是否正确,直到正确猜测角色。在正确猜测之后,我们记下在识别字符时进行的猜测次数,并要求受试者以相同的方式猜测下一个字符。
当一个人被要求猜测一个句子时,一个句子给出了以下结果。每个字符下方列出了猜测的数量。
那里 – 是 – 没有 O-REVERSE-ON-A-MOTORC YC LE –
11151121121115117111213212271111411111
请注意,在许多情况下,会立即猜测下一个字母,一次猜测。在其他情况下,特别是在音节的开头,需要更多的猜测。
数学代写|信息论作业代写INFORMATION THEORY代考|ARITHMETIC CODES
当我们讨论可变长度符号码以及构建它们的最佳霍夫曼算法时,我们通过指出霍夫曼码的两个实际和理论问题来总结s和C吨一世这n5.6.
这些缺陷由 Elias、Rissanen 和 Pasco 发明的算术代码纠正,随后被 Witten 等人实用化。1987. 在算术代码中,概率建模与编码操作明显分开。该系统与猜谜游戏非常相似。人类预测器被源的概率模型所取代。由于每个符号都是由源产生的,概率模型提供了对下一个符号的所有可能值的预测分布,即正数列表\left{p_{i}\right}\left{p_{i}\right}总和为一。如果我们选择将源建模为产生具有某种已知分布的独立同分布符号,那么预测分布每次都是相同的;但是算术编码可以同样轻松地处理产生上下文相关预测分布的复杂自适应模型。预测模型通常在计算机程序中实现。
数学代写|信息论作业代写INFORMATION THEORY代考|FURTHER APPLICATIONS OF ARITHMETIC CODING
算术编码不仅提供了一种压缩被认为来自给定模型的字符串的方法;它还提供了一种从模型生成随机字符串的方法。想象一下,将一根大头针随机插入单位区间,该线已按照概率按比例划分为子区间p一世; 您的引脚位于区间内的概率一世是p一世.
因此,要从模型生成样本,我们需要做的就是将普通随机位输入该模型的算术解码器。一个无限的随机位序列对应于从[0,1),因此解码器将从假设的分布中随机选择一个字符串。这种算术方法保证使用几乎尽可能少的随机位来进行选择——这在随机数昂贵的社区中很重要!这并不是一个玩笑。大量的资金被用于在软件和硬件中生成随机位。随机数是有价值的。
使用此技术的一个简单示例是生成具有非均匀分布的随机位\left{p_{0}, p_{1}\right}\left{p_{0}, p_{1}\right}.

数学代写|信息论作业代写information theory代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。