如果你也在 怎样代写神经网络Neural Networks AIML425这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。神经网络Neural Networks理论既有助于更好地确定大脑中的神经元如何运作,也为创造人工智能的努力提供了基础。反映了人脑的行为,使计算机程序能够识别模式并解决人工智能、机器学习和深度学习领域的常见问题。
神经网络Neural Networks也被称为人工神经网络(ANN)或模拟神经网络(SNN),是机器学习的一个子集,是深度学习算法的核心。它们的名称和结构受到人脑的启发,模仿了生物神经元相互之间的信号方式。
my-assignmentexpert™ 神经网络Neural Networks作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的神经网络Neural Networks作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此神经网络Neural Networks作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在机器学习Machine Learning作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的机器学习Machine Learning代写服务。我们的专家在神经网络Neural Networks代写方面经验极为丰富,各种神经网络Neural Networks相关的作业也就用不着 说。
我们提供的神经网络Neural NetworksAIML425及其相关学科的代写,服务范围广, 其中包括但不限于:
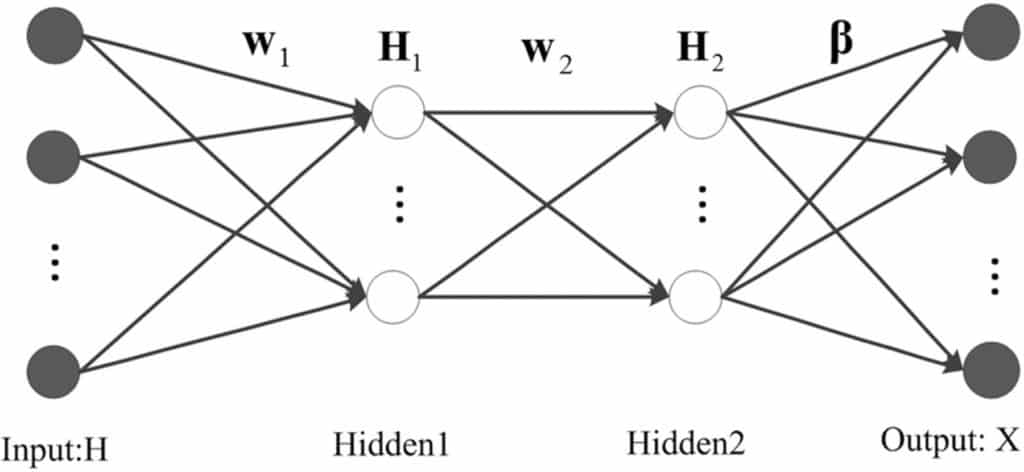
机器学习代写|神经网络代写Neural Networks代考|Representation Learning for Image Processing
Image representation learning is a fundamental problem in understanding the semantics of various visual data, such as photographs, medical images, document scans, and video streams. Normally, the goal of image representation learning for image processing is to bridge the semantic gap between the pixel data and semantics of the images. The successful achievements of image representation learning have enpowered many real-world problems, including but not limited to image search, facial recognition, medical image analysis, photo manipulation and target detection.
In recent years, we have witnessed a fast advancement of image representation learning from handcrafted feature engineering to that from scratch through deep neural network models. Traditionally, the patterns of images are extracted with the help of hand-crafted features by human beings based on prior knowledge. For example, Huang et al (2000) extracted the character’s structure features from the strokes, then use them to recognize the handwritten characters. Rui (2005) adopted the morphology method to improve local feature of the characters, then use PCA to extract features of characters. However, all of these methods need to extract features from images manually and thus the prediction performances strongly rely on the prior knowledge. In the field of computer vision, manual feature extraction is very cumbersome and impractical because of the high dimensionality of feature vectors. Thus, representation learning of images which can automatically extract meaningful, hidden and complex patterns from high-dimension visual data is necessary. Deep learning-based representation learning for images is learned in an end-to-end fashion, which can perform much better than hand-crafted features in the target applications, as long as the training data is of sufficient quality and quantity.
Supervised Representation Learning for image processing. In the domain of image processing, supervised learning algorithm, such as Convolution Neural Network (CNN) and Deep Belief Network (DBN), are commonly applied in solving various tasks. One of the earliest deep-supervised-learning-based works was proposed in 2006 (Hinton et al, 2006), which is focused on the MNIST digit image classification problem, outperforming the state-of-the-art SVMs. Following this, deep convolutional neural networks (ConvNets) showed amazing performance which is greatly depends on their properties of shift in-variance, weights sharing and local pattern capturing. Different types of network architectures were developed to increase the capacity of network models, and larger and larger datasets were collected these days. Various networks including AlexNet (Krizhevsky et al, 2012), VGG (Simonyan and Zisserman, 2014b), GoogLeNet (Szegedy et al, 2015), ResNet (He et al, 2016a), and DenseNet (Huang et al, 2017a) and large scale datasets, such as ImageNet and OpenImage, have been proposed to train very deep convolutional neural networks. With the sophisticated architectures and large-scale datasets, the performance of convolutional neural networks keeps outperforming the state-of-the-arts in various computer vision tasks.
机器学习代写|神经网络代写Neural Networks代考|Representation Learning for Speech Recognition
Nowadays, speech interfaces or systems have become widely developed and integrated into various real-life applications and devices. Services like Siri ${ }^{1}$, Cortana ${ }^{2}$, and Google Voice Search ${ }^{3}$ have become a part of our daily life and are used by millions of users. The exploration in speech recognition and analysis has always been motivated by a desire to enable machines to participate in verbal human-machine interactions. The research goals of enabling machines to understand human speech, identify speakers, and detect human emotion have attracted researchers’ attention for more than sixty years across several distinct research areas, including but not limited to Automatic Speech Recognition (ASR), Speaker Recognition (SR), and Speaker Emotion Recognition (SER).
Analyzing and processing speech has been a key application of machine learning (ML) algorithms. Research on speech recognition has traditionally considered the task of designing hand-crafted acoustic features as a separate distinct problem from the task of designing efficient models to accomplish prediction and classification decisions. There are two main drawbacks of this approach: First, the feature engineering is cumbersome and requires human knowledge as introduced above; and second, the designed features might not be the best for the specific speech recognition tasks at hand. This has motivated the adoption of recent trends in the speech community towards the utilization of representation learning techniques, which can learn an intermediate representation of the input signal automatically that better fits into the task at hand and hence lead to improved performance. Among all these successes, deep learning-based speech representations play an important role. One of the major reasons for the utilization of representation learning techniques in speech technology is that speech data is fundamentally different from two-dimensional image data. Images can be analyzed as a whole or in patches, but speech has to be formatted sequentially to capture temporal dependency and patterns.
神经网络代写
机器学习代写|神经网络代写NEURAL NETWORKS代考|REPRESENTATION LEARNING FOR IMAGE PROCESSING
图像表示学习是理解各种视觉数据语义的一个基本问题,例如照片、医学图像、文档扫描和视频流。通常,用于图像处理的图像表示学习的目标是弥合像素数据和图像语义之间的语义鸿沟。图像表示学习的成功成就为许多现实世界的问题提供了支持,包括但不限于图像搜索、面部识别、医学图像分析、照片处理和目标检测。
近年来,我们见证了图像表示学习从手工特征工程到通过深度神经网络模型从零开始的快速发展。传统上,图像的模式是在人类基于先验知识的手工特征的帮助下提取的。例如,黄等人2000从笔画中提取汉字的结构特征,然后用它们来识别手写字符。瑞2005采用形态学方法改进字符的局部特征,然后使用PCA提取字符的特征。然而,所有这些方法都需要手动从图像中提取特征,因此预测性能强烈依赖于先验知识。在计算机视觉领域,由于特征向量的高维性,人工提取特征非常繁琐且不切实际。因此,能够从高维视觉数据中自动提取有意义、隐藏和复杂模式的图像表示学习是必要的。基于深度学习的图像表示学习是以端到端的方式学习的,只要训练数据的质量和数量足够,它在目标应用程序中的表现就比手工制作的特征要好得多。
用于图像处理的监督表示学习。在图像处理领域,监督学习算法,如卷积神经网络Cññ和深度信念网络D乙ñ, 通常用于解决各种任务。最早的基于深度监督学习的作品之一是在 2006 年提出的H一世n吨○n和吨一个l,2006,它专注于 MNIST 数字图像分类问题,优于最先进的 SVM。在此之后,深度卷积神经网络C○n在ñ和吨s展示了惊人的性能,这在很大程度上取决于它们的平移不变性、权重共享和局部模式捕获的特性。为了增加网络模型的容量,开发了不同类型的网络架构,并且收集了越来越大的数据集。包括 AlexNet 在内的各种网络ķr一世和H和在sķ是和吨一个l,2012, VGG小号一世米○n是一个n一个nd从一世ss和r米一个n,2014b, 谷歌网络小号和和G和d是和吨一个l,2015, 资源网H和和吨一个l,2016一个, 和 DenseNetH在一个nG和吨一个l,2017一个和大规模数据集,如 ImageNet 和 OpenImage,已被提出来训练非常深的卷积神经网络。凭借复杂的架构和大规模的数据集,卷积神经网络的性能在各种计算机视觉任务中不断超越最先进的技术。
机器学习代写|神经网络代写NEURAL NETWORKS代考|REPRESENTATION LEARNING FOR SPEECH RECOGNITION
如今,语音接口或系统已得到广泛开发并集成到各种现实生活中的应用程序和设备中。Siri 等服务1, 小娜2和谷歌语音搜索3已成为我们日常生活的一部分,并被数百万用户使用。语音识别和分析的探索一直是由希望机器参与人机交互的愿望所推动的。使机器能够理解人类语音、识别说话者和检测人类情感的研究目标在 60 多年来吸引了多个不同研究领域的研究人员的关注,包括但不限于自动语音识别一个小号R, 说话人识别小号R, 和说话者情绪识别小号和R.
分析和处理语音一直是机器学习的关键应用米大号算法。语音识别研究传统上认为设计手工声学特征的任务与设计有效模型以完成预测和分类决策的任务是分开的不同问题。这种方法有两个主要缺点:首先,特征工程很麻烦,需要上面介绍的人类知识;其次,设计的功能可能不是手头特定语音识别任务的最佳选择。这促使语音社区采用表示学习技术的最新趋势,该技术可以自动学习输入信号的中间表示,以更好地适应手头的任务,从而提高性能。在所有这些成功中,基于深度学习的语音表示起着重要作用。在语音技术中使用表示学习技术的主要原因之一是语音数据与二维图像数据有根本的不同。图像可以作为一个整体或块进行分析,但语音必须按顺序格式化以捕捉时间依赖性和模式。

机器学习代写|神经网络代写Neural Networks代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。