MY-ASSIGNMENTEXPERT™可以为您提供 soe.ucsc.edu STAT209 Generalized Linear Models广义线性模型的代写代考和辅导服务!
这是圣克鲁斯加利福尼亚大学 广义线性模型的代写成功案例。

STAT209课程简介
Theory, methods, and applications of generalized linear statistical models; review of linear models; binomial models for binary responses (including logistical regression and probit models); log-linear models for categorical data analysis; and Poisson models for count data. Case studies drawn from social, engineering, and life sciences.
Course description and background: This is a graduate-level course on the theory, methods and applications of Generalized Linear Models (GLMs). Emphasis will be placed on statistical modeling, building from standard normal linear models, extending to GLMs, and briefly covering more specialized topics. With regard to inference, prediction, and model assessment, we will study both likelihood and Bayesian methods. In particular, within the Bayesian modeling framework, we will discuss practically important hierarchical extensions of the standard GLM setting.
Prerequisites
Note that this is a course on methods for GLMs, rather than a course on using software for data analysis with GLMs. Students will be expected to be familiar with statistical software R, which will be used to illustrate the methods with data examples as part of the homework assignments (and exam). For data analysis problems involving Bayesian GLMs, you will be expected to write your own programs to fit Bayesian models using Markov chain Monte Carlo posterior simulation methods (R will suffice for this).
STAT209 Generalized Linear Models HELP(EXAM HELP, ONLINE TUTOR)
The list below includes a number of distributions, providing in each case the probability density or mass function, support, and parameter space. Determine whether each of the distributions belongs to the exponential dispersion family. Similarly for the two-parameter exponential family of distributions. In both cases, justify your answers.
(c) Logistic distribution.
$$
f(y \mid \theta, \sigma)=\frac{\exp ((y-\theta) / \sigma)}{\sigma{1+\exp ((y-\theta) / \sigma)}^2} \quad y \in \mathbb{R}, \quad \theta \in \mathbb{R}, \sigma>0
$$
(d) Cauchy distribution.
$$
f(y \mid \theta, \sigma)=\frac{1}{\pi \sigma\left{1+((y-\theta) / \sigma)^2\right}} \quad y \in \mathbb{R}, \quad \theta \in \mathbb{R}, \sigma>0
$$
(e) Pareto distribution.
$$
f(y \mid \alpha, \beta)=\frac{\beta \alpha^\beta}{y^{\beta+1}} \quad y \geq \alpha, \alpha>0, \beta>0
$$
(f) Beta distribution.
$$
f(y \mid \alpha, \beta)=\frac{y^{\alpha-1}(1-y)^{\beta-1}}{\mathrm{~B}(\alpha, \beta)} \quad 0 \leq y \leq 1, \quad \alpha>0, \beta>0
$$
where $\mathrm{B}(\alpha, \beta)=\int_0^1 u^{\alpha-1}(1-u)^{\beta-1} \mathrm{~d} u$ is the beta function.
(g) Negative binomial distribution.
$$
f(y \mid \alpha, p)=\frac{\Gamma(y+\alpha)}{\Gamma(\alpha) y !} p^\alpha(1-p)^y \quad y \in{0,1,2, \ldots}, \quad \alpha>0,0<p<1,
$$
where $\Gamma(c)=\int_0^{\infty} u^{c-1} \exp (-u) \mathrm{d} u$ is the gamma function.
Consider the linear regression setting where the responses $Y_i, i=1, \ldots, n$, are assumed independent with means $\mu_i=\mathrm{E}\left(Y_i\right)=\boldsymbol{x}i^T \boldsymbol{\beta}=\sum{j=1}^p x_{i j} \beta_j$ for (known) covariates $x_{i j}$ and (unknown) regression coefficients $\boldsymbol{\beta}=\left(\beta_1, \ldots, \beta_p\right)^T$.
(i) Show that if the response distribution is normal,
$$
Y_i \stackrel{i n d .}{\sim} f\left(y_i \mid \mu_i, \sigma\right)=\left(2 \pi \sigma^2\right)^{-1 / 2} \exp \left(-\frac{\left(y_i-\mu_i\right)^2}{2 \sigma^2}\right), \quad i=1, \ldots, n,
$$
then the maximum likelihood estimate (MLE) of $\boldsymbol{\beta}$ is obtained by minimizing the $L_2$ norm,
$$
S_2(\boldsymbol{\beta})=\sum_{i=1}^n\left(y_i-\boldsymbol{x}i^T \boldsymbol{\beta}\right)^2 $$ (ii) Show that if the response distribution is double exponential, $$ Y_i \stackrel{i n d .}{\sim} f\left(y_i \mid \mu_i, \sigma\right)=(2 \sigma)^{-1} \exp \left(-\frac{\left|y_i-\mu_i\right|}{\sigma}\right), \quad i=1, \ldots, n, $$ then the MLE of $\boldsymbol{\beta}$ is obtained by minimizing the $L_1$-norm, $$ S_1(\boldsymbol{\beta})=\sum{i=1}^n\left|y_i-\boldsymbol{x}i^T \boldsymbol{\beta}\right| $$ (iii) Show that if the response distribution is uniform over the range $\left[\mu_i-\sigma, \mu_i+\sigma\right]$, $$ Y_i \stackrel{\text { ind. }}{\sim} f\left(y_i \mid \mu_i, \sigma\right)=(2 \sigma)^{-1}, \text { for } \mu_i-\sigma \leq y_i \leq \mu_i+\sigma, \quad i=1, \ldots, n, $$ then the MLE of $\boldsymbol{\beta}$ is obtained by minimizing the $L{\infty}$-norm,
$$
S_{\infty}(\boldsymbol{\beta})=\max _i\left|y_i-\boldsymbol{x}_i^T \boldsymbol{\beta}\right|
$$
(iv) Obtain the MLE of $\sigma$ under each one of the response distributions in (i) – (iii) and show that, in all cases, it is a function of the minimized norm.
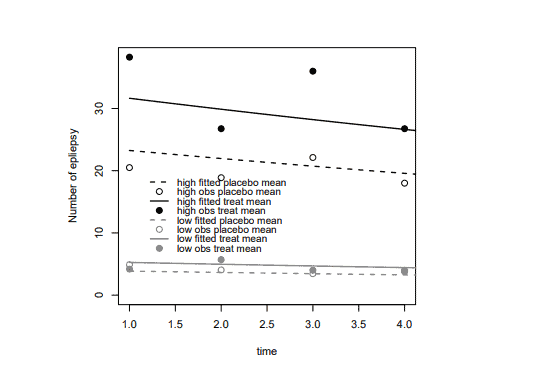
The data in the table below show the number of cases of AIDS in Australia by date of diagnosis for successive 3-month periods from 1984 to 1988.
\begin{tabular}{ccccc}
\hline \multicolumn{5}{c}{ Quarter } \
Year & 1 & 2 & 3 & 4 \
\hline 1984 & 1 & 6 & 16 & 23 \
1985 & 27 & 39 & 31 & 30 \
1986 & 43 & 51 & 63 & 70 \
1987 & 88 & 97 & 91 & 104 \
1988 & 110 & 113 & 149 & 159 \
\hline
\end{tabular}
Let $x_i=\log (i)$, where $i$ denotes the time period for $i=1, \ldots, 20$. Consider a GLM for this data set based on a Poisson distribution with response means $\mu_i$, systematic component $\beta_1+\beta_2 x_i$, and logarithmic link function $g\left(\mu_i\right)=\log \left(\mu_i\right)$
(a) Fit this GLM to the data working from first principles, that is, derive the expressions that are needed for the scoring method, and implement the algorithm to obtain the maximum likelihood estimates for $\beta_1$ and $\beta_2$.
(b) Use function “glm” in $\mathrm{R}$ to verify your results from part (a).
Let $X$ be a random variable with mean $\mu$ and variance $\sigma^2$ and let $g$ be a twice differentiable function. A Taylor expansion about $\mu$ gives
$$
g(X)-g(\mu)=(X-\mu) g^{\prime}(\mu)+\frac{1}{2} g^{\prime \prime}(\mu)(X-\mu)^2+\ldots
$$
ignoring all but the first term on the right hand side. Show that
$$
E[g(X)] \simeq g(\mu) \text { and } \operatorname{Var}[g(X)] \simeq \sigma^2\left[g^{\prime}(\mu)\right]^2
$$
Hence
(a) show that the variance-covariance matrix for the ML estimates $\widehat{\boldsymbol{\theta}}$ using the NewtonRaphson procedures is
$$
\operatorname{var}(\widehat{\boldsymbol{\theta}}) \simeq[\boldsymbol{I}(\widehat{\boldsymbol{\theta}})]^{-1}
$$
where $\boldsymbol{I}(\boldsymbol{\theta})$ is the informative matrix.
(b) find a function $g$ such that $\operatorname{Var}(g(X))$ is approximately constant when $X \sim \operatorname{Poisson}(\lambda)$.

MY-ASSIGNMENTEXPERT™可以为您提供UNIVERSITY OF ILLINOIS URBANA-CHAMPAIGN MATH2940 linear algebra线性代数课程的代写代考和辅导服务! 请认准MY-ASSIGNMENTEXPERT™. MY-ASSIGNMENTEXPERT™为您的留学生涯保驾护航。