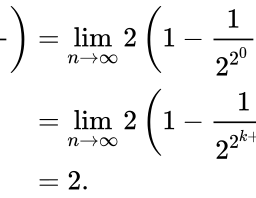如果你也在 怎样代写统计Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计Statistics是数学的一个分支,涉及到矢量空间和线性映射。它包括对线、面和子空间的研究,也涉及所有向量空间的一般属性。
统计学Statistics是一门关于发展和研究收集、分析、解释和展示经验数据的方法的科学。统计Statistics是一个高度跨学科的领域;统计Statistics的研究几乎适用于所有的科学领域,各科学领域的研究问题促使新的统计方法和理论的发展。在开发方法和研究支撑这些方法的理论时,统计学家利用了各种数学和计算工具。
统计Statistics领域的两个基本概念是不确定性和突变。我们在科学(或更广泛的生活)中遇到的许多情况,其结果是不确定的。在某些情况下,不确定性是因为有关的结果尚未确定(例如,我们可能不知道明天是否会下雨),而在其他情况下,不确定性是因为虽然结果已经确定,但我们并不知道(例如,我们可能不知道我们是否通过了某项考试)。
my-assignmentexpert™ 统计Statistics作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计Statistics作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在统计Statistics代写方面经验极为丰富,各种统计Statistics相关的作业也就用不着 说。
我们提供的统计Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Date Analysis数据分析
- Actuarial Science 精算科学
- Bayesian Statistics 贝叶斯统计
- Generalized Linear Model 广义线性模型
- Macroeconomic statistics 宏观统计学
- Microeconomic statistics 微观统计学
- Logistic regression 逻辑回归
- linear regression 线性回归
统计作业代写Statistics代考|figure
we observed that another name for the outcome variable is the endogenous variable. The term endo refers to something that is inside or within. An endogenous variable is, therefore, one produced within the system or within the equation. The linear regression equation, you’ve noticed by now, assumes that the outcome variable, but not the explanatory variables, is “produced” within the system. The explanatory variables are considered exogenous or produced only by factors outside of the system. A common claim is that the explanatory variables are “predetermined”; pre implying they are formed outside the system inferred by the model. Such an understanding of the model is so important some experts call it the exogeneity assumption. $.^{10}$
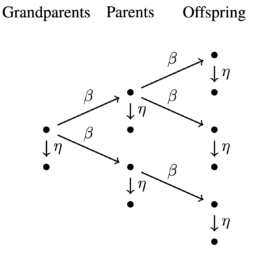
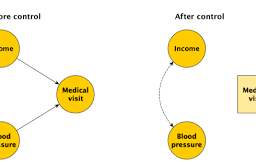
Endogeneity issues arise when the LRM has not been specified correctly and generally involve when explanatory variables are associated with the error term. The last section discussed how this can occur when we have omitted variable bias because $\left.\operatorname{cov}\left(\mathbf{x}, \hat{\varepsilon}_{i}\right) \neq 0\right)$, but it also includes whether we have identified the correct ordering of the variables. For example, think about a set of variables such as education, occupational prestige, race/ethnicity, and life satisfaction. Models are often proposed that define a particular set of these variables as affecting one another in some way. In the last section, for instance, we saw that occupational prestige confounded the presumed association between education and life satisfaction. But is it feasible to imagine that occupational prestige is endogenous in the model since it is influenced by education? Probably, and this implies a different sort of relationship, with occupational prestige mediating the association between education and life satisfaction. Figure $12.4$ represents this model.
统计作业代写STATISTICS代考|characterizes
The figure characterizes two models that are interconnected: the first uses occupational prestige as the outcome, whereas the second uses life
Illustration of a mediation model.
satisfaction as the outcome. When two (or more) such models are considered in a regression context, this approach is called a simultaneous equations mod${ }_{e l} .^{11}$ If such an association exists yet we fail to model it appropriately, we are at risk of simultaneous equations bias.
Similarly, consider the model in Equation $12.3$ that includes race/ethnicity.
Life satisfaction $_{i}=\alpha+\beta_{1}\left(\right.$ occup. $\left.^{\text {prestige }}\right)+\beta_{2}\left(\right.$ race/ethnicity $\left.{i}\right)+\hat{\varepsilon}{i} \quad$ (12.3)
The model implies that occupational prestige and race/ethnicity independently combine to affect life satisfaction. But suppose that occupational prestige and race/ethnicity are not independently determined; rather, because of various historical and social factors that are associated with race/ethnicity in the U.S. and elsewhere, occupational prestige is, in part, a product of an individual’s race/ ethnicity. Similar to the previous example, occupational prestige is endogenous in the system specified by Equation 12.3. The problem for the LRM is that the estimated slope coefficient for occupational prestige in the equation is biased. As an exercise, estimate a model with occupational prestige as the outcome variable and a variable that measures race/ethnicity (race or ethnic) as the explanatory variable. Include education as a control variable. What do the results tell you about the possible endogeneity of occupational prestige?
A second endogeneity issue asks whether one or more explanatory variables might be affected by the presumed outcome variable. Suppose we wish to estimate a model with adolescent alcohol use as the outcome variable and friends’ alcohol use as the explanatory variable. We may assume that one’s friends influence one’s behavior to a certain degree, thus leading to the model specification shown in Figure 12.5. But it may also be true that one’s choice of friends depends on one’s behavior. Perhaps youth who drink alcohol are more likely to choose friends who also drink alcohol. This issue implies that alcohol use and friends’ alcohol use are involved in a reciprocal association.
统计作业代写STATISTICS代考|FIGURE
我们观察到结果变量的另一个名称是内生变量。endo一词是指内部或内部的事物。因此,内生变量是在系统或方程中产生的。您现在已经注意到,线性回归方程假设结果变量,而不是解释变量,是在系统内“产生”的。解释变量被认为是外生的或仅由系统外的因素产生。一个常见的说法是解释变量是“预先确定的”;预先暗示它们是在模型推断的系统之外形成的。对模型的这种理解非常重要,一些专家称其为外生性假设。.10
当 LRM 没有被正确指定并且通常涉及解释变量与误差项相关联时,内生性问题就会出现。上一节讨论了当我们忽略变量偏差时这是如何发生的,因为这(X,e^一世)≠0),但它也包括我们是否已经确定了变量的正确顺序。例如,考虑一组变量,例如教育、职业声望、种族/民族和生活满意度。通常提出的模型将这些变量的特定集合定义为以某种方式相互影响。例如,在上一节中,我们看到职业声望混淆了教育与生活满意度之间假定的关联。但是,假设职业声望在模型中是内生的,因为它受到教育的影响,是否可行?可能,这意味着一种不同的关系,职业声望调节了教育和生活满意度之间的关联。数字12.4代表这个模型。
统计作业代写STATISTICS代考|CHARACTERIZES
该图描绘了两个相互关联的模型:第一个使用职业声望作为结果,而第二个使用生命
中介模型图示。
满意为结果。当在回归环境中考虑两个(或更多)这样的模型时,这种方法称为联立方程模型和一世.11如果存在这样的关联,但我们未能对其进行适当的建模,那么我们就有可能出现联立方程偏差。
同样,考虑方程中的模型12.3这包括种族/民族。
生活满意度一世=一种+b1(占领。声望 )+b2(种族/民族$\left。{i}\right)+\hat{\varepsilon} {i} \quad$ (12.3)
该模型暗示职业声望和种族/民族独立地结合起来影响生活满意度。但是假设职业声望和种族/民族不是独立决定的;相反,由于在美国和其他地方与种族/民族相关的各种历史和社会因素,职业声望部分是个人种族/民族的产物。与前面的例子类似,职业声望在公式 12.3 指定的系统中是内生的。LRM 的问题是方程中职业声望的估计斜率系数有偏差。作为练习,以职业声望作为结果变量和测量种族/民族(种族或民族)的变量作为解释变量,估计一个模型。将教育作为控制变量。
第二个内生性问题询问一个或多个解释变量是否会受到假定结果变量的影响。假设我们希望估计一个模型,其中青少年饮酒作为结果变量,朋友的饮酒作为解释变量。我们可以假设一个人的朋友会在一定程度上影响一个人的行为,从而得出图 12.5 所示的模型规范。但是,一个人对朋友的选择取决于一个人的行为,这也可能是真的。也许喝酒的年轻人更可能选择也喝酒的朋友。这个问题意味着酒精使用和朋友的酒精使用是相互关联的。

统计作业代写Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
matlab代写
MATLAB是一个编程和数值计算平台,被数百万工程师和科学家用来分析数据、开发算法和创建模型。
MATLAB is a programming and numeric computing platform used by millions of engineers and scientists to analyze data, develop algorithms, and create models.
统计代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
统计作业代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
my-assignmentexpert™这边统计代写的质量怎么样?保不保分?靠不靠谱? 一般能写到多少分?
各国各学校的学术标准都有所差异,即使是统计作业,给分也存在一定的主观性因素,有时Teacher和TA的改分并不能够做到完全公正,所有的作业分数都存在一定的运气成分,TA对于步骤把控的严格程度可能和给分的TA今天的心情以及他的性格正相关。一般情况下,MY-ASSIGNMENTEXPERT™出品的作业平均正确率在93%以上。
我在MY-ASSIGNMENTEXPERT™这里购买了代写服务,然后最后这门课的成绩挂了怎么办?
若是因为各种因素结合导致在此购买的统计作业的成绩未达到事先指定的标准,MY-ASSIGNMENTEXPERT™承诺免费重写/修改,并且无条件退款。
最快什么时候写完? 很急的任务可以做吗?
最急的统计论文,可在24小时以内完成,加急的论文价格会比普通的订单稍贵,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计quiz和统计exam代考,在写手档期ok的情况下,可以在下单之后一小时之内进行,不过不提倡这样临时找人,因为加急的quiz和exam代考价格会比普通的订单贵更重要的是可能找不到人,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计assignment,在写手档期ok的情况下,可以在下单之后三小时之内完成,价格在一般的assignment基础上收一个加急费用,如果一份assignment发下来不确定自己能不能完成也能提前和我们联系,报价是不收取任何费用的,如果后续有需要,也方便我们安排写手档期。