如果你也在为遇到的matlab相关的难题发愁,请随时右上角联系我们的24/7代写客服。MATLAB®将为迭代分析和设计过程而调整的桌面环境与直接表达矩阵和阵列数学的编程语言相结合。它包括用于创建脚本的实时编辑器,这些脚本将代码、输出和格式化文本结合在可执行的笔记本中。
- 专业构建
MATLAB工具箱是专业开发的,经过严格的测试,并有完整的文件记录。 - 拥有互动式应用程序
MATLAB应用程序让您看到不同的算法是如何与您的数据一起工作的。迭代直到您得到您想要的结果,然后自动生成一个MATLAB程序来重现或自动完成您的工作。 - 以及扩展的能力
只需稍加修改代码,就可以将您的分析扩展到集群、GPU和云上运行。不需要重写你的代码或学习大数据编程和内存外技术。
my-assignmentexpert™ matlab作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的matlab作业代写作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此matlab作业代写作业代写的价格不固定。通常在matlab专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在matlab作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的应用数学applied math代写服务。我们的专家在matlab作业代写方面经验极为丰富,各种matlab作业代写相关的作业也就用不着 说。
我们提供的matlab作业代写及其相关学科的代写,服务范围广, 其中包括但不限于:
- 数据分析
- 数值与符号计算
- 工程与科学绘图
- 控制系统设计
- 航天工业
- 汽车工业
- 生物医学工程
- 语音处理
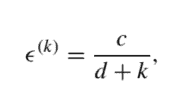
运筹学代写
数学代写|matlab作业代写|The Exploration vs. Exploitation Tradeoff
On the opposite end of the spectrum, the alternative of pure exploration consists of a random selection of alternatives, based on uniform probabilities. Clearly, we need to find some sensible compromise between these extremes. The theory of optimal learning in multiarmed bandits is definitely beyond the scope of this tutorial, but we should mention that the problem is, in its most general form, essentially intractable. In some cases, it is possible to find an index (called the Gittins index) for each action, allowing us to sort alternatives and find the next alternative to try in an optimal way. Alternatively, sophisticated heuristics have been proposed, like the knowledge gradient [10]. Let us consider the simplest strategies, which may be easily applied to DP.
- The static $\epsilon$-greedy approach. Since pure exploitation may prevent us from finding interesting actions, and pure exploration is arguably inefficient, the $\epsilon-$ greedy approach has been proposed to balance these two extreme approaches. In the static version, we fix a probability $\epsilon$. Then, with probability $1-\epsilon$ we select the most promising action, and with probability $\epsilon$ we select a random action.
- The dynamic $\epsilon$-greedy approach. A possible refinement is to change $\epsilon$ along the way. In the first iterations, we should probably tip the balance in favor of exploration, whereas in the latter iterations, when we are supposed to have gathered more reliable estimates, we may decrease $\epsilon$. One possibility would be to set, at iteration $k$,
$$
\epsilon^{(k)}=\frac{c}{d+k}
$$
for given constants $c$ and $d$. If we want to retain some exploration component anyway, with probability $d$, we could choose a policy based on
$$
\epsilon^{(k)}=d+\frac{c}{k}
$$
数学代写|MATLAB作业代写|Non-stationarity and Exponential Smoothing
Another source of trouble is the non-stationarity of estimates of value functions or $Q$-factors. Even though the system itself might be stationary, the policy that we follow to make decisions is not, as we are learning along the way. To understand the point, consider the familiar sample mean used to estimate the expected value $\theta=\mathbb{E}[X]$ of a scalar random variable $X$. In the sample mean, all of the collected observations have the same weight. This may be expressed in a different way, in order to reflect a sequential sampling procedure. Let $\widehat{\theta}^{(m)}$ be the estimate of $\theta$ after collecting $m$ observations:
$$
\begin{aligned}
\widehat{\theta}^{(m)} &=\frac{1}{m} \sum_{k=1}^{m} X^{(k)}=\frac{1}{m}\left(X^{(m)}+\sum_{k=1}^{m-1} X^{(k)}\right)=\frac{1}{m}\left(X^{(m)}+(m-1) \widehat{\theta}^{(m-1)}\right) \
&=\frac{1}{m} X^{(m)}+\frac{m-1}{m} \cdot \widehat{\theta}^{(m-1)}=\widehat{\theta}^{(m-1)}+\frac{1}{m}\left(X^{(m)}-\widehat{\theta}^{(m-1)}\right) .
\end{aligned}
$$
When we obtain a new observation $X^{(m)}$, we are essentially applying to the old estimate $\widehat{\theta}^{(m-1)}$ a correction that is proportional to the forecasting error. The amount of correction is smoothed by $1 / m$, and tends to vanish as $m$ grows. In a nonstationary setting, we may wish to keep the amount of correction constant:
$$
\widehat{\theta}^{(m)}=\widehat{\theta}^{(m-1)}+\alpha\left(X^{(m)}-\widehat{\theta}^{(m-1)}\right)=\alpha X^{(m)}+(1-\alpha) \widehat{\theta}^{(m-1)},
$$
where the coefficient $\alpha \in(0,1)$ specifies the weight of the new information with respect to the old one. This approach is known as exponential smoothing, and in order to figure out the reasons behind this name, let us recursively unfold Eq. (5.1):
$$
\begin{aligned}
\widehat{\theta}^{(m)} &=\alpha X^{(m)}+(1-\alpha) \widehat{\theta}^{(m-1)} \
&=\alpha X^{(m)}+\alpha(1-\alpha) X^{(m-1)}+(1-\alpha)^{2} \widehat{\theta}^{(m-2)} \
&=\sum_{k=0}^{m-1} \alpha(1-\alpha)^{k} X^{(m-k)}+(1-\alpha)^{m} \widehat{\theta}^{(0)}
\end{aligned}
$$
matlab代写
数学代写|MATLAB作业代写|THE EXPLORATION VS. EXPLOITATION TRADEOFF
在频谱的另一端,纯探索的替代方案包括基于统一概率的随机选择。显然,我们需要在这些极端之间找到一些合理的折衷方案。多臂老虎机中的最优学习理论肯定超出了本教程的范围,但我们应该提到,这个问题在最一般的形式下本质上是棘手的。在某些情况下,可以找到索引C一种一世一世和d吨H和G一世吨吨一世ns一世nd和X对于每个动作,允许我们对备选方案进行排序并找到下一个备选方案以最佳方式尝试。或者,已经提出了复杂的启发式方法,例如知识梯度10. 让我们考虑最简单的策略,这些策略可以很容易地应用于 DP。
- 静态的ε-贪婪的方法。由于纯粹的利用可能会阻止我们找到有趣的动作,而纯粹的探索可以说是低效的,ε−已经提出了贪婪方法来平衡这两种极端方法。在静态版本中,我们固定一个概率ε. 那么,有概率1−ε我们选择最有希望的行动,并且有概率ε我们选择一个随机动作。
- 动态的ε-贪婪的方法。一个可能的改进是改变ε一路上。在第一次迭代中,我们可能应该平衡探索,而在后面的迭代中,当我们应该收集到更可靠的估计时,我们可能会减少ε. 一种可能性是在迭代时设置到,
ε(到)=Cd+到
对于给定的常数C和d. 如果我们无论如何都想保留一些探索部分,有可能d,我们可以选择一个基于
ε(到)=d+C到
数学代写|MATLAB作业代写|NON-STATIONARITY AND EXPONENTIAL SMOOTHING
另一个麻烦来源是价值函数估计的非平稳性或问-因素。即使系统本身可能是静止的,但我们制定决策所遵循的政策却不是,因为我们正在学习。要理解这一点,请考虑用于估计期望值的熟悉样本均值θ=和[X]一个标量随机变量X. 在样本均值中,所有收集到的观测值具有相同的权重。这可以以不同的方式表达,以反映顺序抽样程序。让θ^(米)是的估计θ收集后米意见:
θ^(米)=1米∑到=1米X(到)=1米(X(米)+∑到=1米−1X(到))=1米(X(米)+(米−1)θ^(米−1)) =1米X(米)+米−1米⋅θ^(米−1)=θ^(米−1)+1米(X(米)−θ^(米−1)).
当我们得到一个新的观察X(米),我们本质上是应用于旧的估计θ^(米−1)与预测误差成比例的修正。校正量被平滑1/米, 并趋于消失为米成长。在非平稳设置中,我们可能希望保持校正量不变:
θ^(米)=θ^(米−1)+一种(X(米)−θ^(米−1))=一种X(米)+(1−一种)θ^(米−1),
其中系数一种∈(0,1)指定新信息相对于旧信息的权重。这种方法被称为指数平滑,为了弄清楚这个名称背后的原因,让我们递归展开方程。5.1:
θ^(米)=一种X(米)+(1−一种)θ^(米−1) =一种X(米)+一种(1−一种)X(米−1)+(1−一种)2θ^(米−2) =∑到=0米−1一种(1−一种)到X(米−到)+(1−一种)米θ^(0)

统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析NumericalAnalysis,又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。