如果你也在 怎样统计计算Statistical Computing这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计计算Statistical Computing是统计学和计算机科学之间的纽带。它意味着通过使用计算方法来实现的统计方法。它是统计学的数学科学所特有的计算科学(或科学计算)的领域。这一领域也在迅速发展,导致人们呼吁应将更广泛的计算概念作为普通统计教育的一部分。与传统统计学一样,其目标是将原始数据转化为知识,[2]但重点在于计算机密集型统计方法,例如具有非常大的样本量和非同质数据集的情况。
许多统计建模和数据分析技术可能难以掌握和应用,因此往往需要使用计算机软件来帮助实施大型数据集并获得有用的结果。S-Plus是公认的最强大和最灵活的统计软件包之一,它使用户能够应用许多统计方法,从简单的回归到时间序列或多变量分析。该文本广泛涵盖了许多基本的和更高级的统计方法,集中于图形检查,并具有逐步说明的特点,以帮助非统计学家充分理解方法。
my-assignmentexpert™统计计算Statistical Computing作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计计算Statistical Computing作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计计算Statistical Computing作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计计算Statistical Computing作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计计算Statistical Computing代写服务。我们的专家在统计计算Statistical Computing代写方面经验极为丰富,各种统计计算Statistical Computing相关的作业也就用不着 说。
我们提供的统计计算Statistical Computing及其相关学科的代写,服务范围广, 其中包括但不限于:
- 随机微积分 Stochastic calculus
- 随机分析 Stochastic analysis
- 随机控制理论 Stochastic control theory
- 微观经济学 Microeconomics
- 数量经济学 Quantitative Economics
- 宏观经济学 Macroeconomics
- 经济统计学 Economic Statistics
- 经济学理论 Economic Theory
- 计量经济学 Econometrics
统计代写
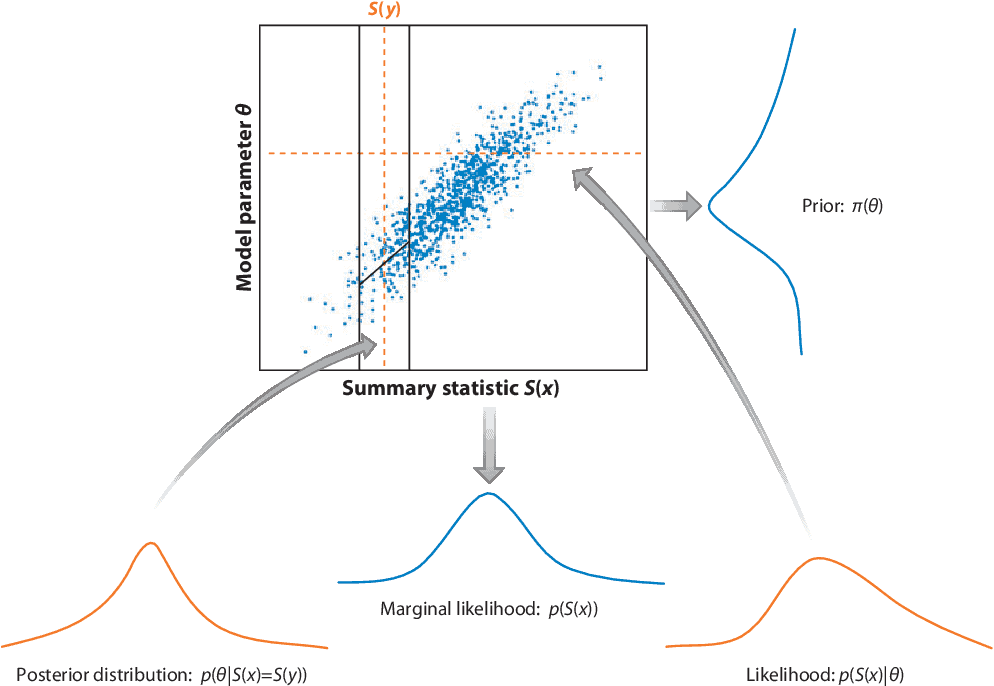
数学代写|统计计算作业代写Statistical Computing代考|Basic Approximate Bayesian Computation
In this section we describe a basic version of the $\mathrm{ABC}$ method. We start the presentation by describing the method as an algorithm, and then give the required explanations to understand why this algorithm gives the desired result.
Algorithm 5.1 (basic Approximate Bayesian Computation)
input:
data $x^{} \in \mathbb{R}^{n}$ the prior density $\pi$ for the unknown parameter $\theta \in \mathbb{R}^{p}$ a summary statistic $S: \mathbb{R}^{n} \rightarrow \mathbb{R}^{q}$ an approximation parameter $\delta>0$ randomness used: samples $\theta_{j} \sim p_{\theta}$ and $X_{j} \sim p_{X \mid \theta}\left(\cdot \mid \theta_{j}\right)$ for $j \in \mathbb{N}$ output: $\theta_{j_{1}}, \theta_{j_{2}}, \ldots$ approximately distributed with density $p_{\theta \mid X}\left(\theta \mid x^{}\right)$
1: $s^{} \leftarrow S\left(x^{}\right)$
2: for $j=1,2,3, \ldots$ do
3: $\quad$ sample $\theta_{j} \sim p_{\theta}(\cdot)$
4: $\quad$ sample $X_{j} \sim p_{X \mid \theta}\left(\cdot \mid \theta_{j}\right)$
5: $\quad S_{j} \leftarrow S\left(X_{j}\right)$
6: if $\left|S_{j}-s^{*}\right| \leq \delta$ then
7: output $\theta_{j}$
8: end if
9: end for
In the algorithm, the summary statistic $S$ is assumed to take values in $\mathbb{R}^{q}$. The dimension $q$ is typically much smaller than the dimension $n$ of the data, and often $q$ equals the number $p$ of parameters. The distance $\left|S_{j}-s^{}\right|$ in line 6 of the algorithm is the Euclidean norm in $\mathbb{R}^{q}$. Since the algorithm considers the summary statistic $s^{}=S\left(x^{*}\right)$ instead of the full data, the method can only be expected to work if $S(\theta)$ contains ‘enough’ information about $\theta$. The optimal case for this is if $S$ is a sufficient statistic, as described in the following definition.
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|Approximate Bayesian Computation with regression
The basic ABC method as described in the previous section can be computationally very expensive. Many variants of $\mathrm{ABC}$, aiming to reduce the computational cost, are used in application areas. In this section we describe one approach to constructing such improved variants of ABC. This approach is based on the idea of accepting a larger proportion of the samples and then to numerically compensate for the systematic error introduced by the discrepancy between the sampled values $s_{j}=S\left(X_{j}\right)$ and the observed value $s^{}=S\left(x^{}\right)$.
The method discussed here is based on the assumption that the samples $\theta_{j}$ can be written as
$$
\theta_{j} \approx f\left(S_{j}\right)+\varepsilon_{j}
$$
for all accepted $j$, where $f(s)=\mathbb{E}(\theta \mid S=s)$ and the $\varepsilon_{j}$ are independent of each other and of the $S_{j}$. If this relation holds at least approximately, we can use the modified samples
$$
\begin{aligned}
\tilde{\theta}{j} &=f\left(s^{}\right)+\varepsilon{j} \
&=f\left(S_{j}\right)+\varepsilon_{j}+f\left(s^{}\right)-f\left(S_{j}\right) \
&=\theta_{j}+f\left(s^{}\right)-f\left(S_{j}\right) \end{aligned} $$ instead of $\theta_{j}$ in order to transform samples corresponding to $S=S_{j}$ into samples corresponding to the required value $S=s^{}$. This idea is made more rigorous by the following result.
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|BASIC APPROXIMATE BAYESIAN COMPUTATION
在本节中,我们将描述一个基本版本的一种乙C方法。我们首先将该方法描述为一种算法,然后给出必要的解释来理解为什么该算法会给出预期的结果。
算法 5.
输入:
数据
data $x^{} \in \mathbb{R}^{n}$ the prior density $\pi$ for the unknown parameter $\theta \in \mathbb{R}^{p}$ a summary statistic $S: \mathbb{R}^{n} \rightarrow \mathbb{R}^{q}$ an approximation parameter $\delta>0$ randomness used: samples $\theta_{j} \sim p_{\theta}$ and $X_{j} \sim p_{X \mid \theta}\left(\cdot \mid \theta_{j}\right)$ for $j \in \mathbb{N}$ output: $\theta_{j_{1}}, \theta_{j_{2}}, \ldots$ approximately distributed with density $p_{\theta \mid X}\left(\theta \mid x^{}\right)$
1: $s^{} \leftarrow S\left(x^{}\right)$
2: for $j=1,2,3, \ldots$ do
3: $\quad$ sample $\theta_{j} \sim p_{\theta}(\cdot)$
4: $\quad$ sample $X_{j} \sim p_{X \mid \theta}\left(\cdot \mid \theta_{j}\right)$
5: $\quad S_{j} \leftarrow S\left(X_{j}\right)$
6: if $\left|S_{j}-s^{*}\right| \leq \delta$ then
output $\theta_{i}$\text {
7: } \quad \text { output } \theta_{j}
8: 结束 if
9: 结束
在算法中,汇总统计量小号假定取值Rq. 维度q通常比尺寸小得多n的数据,并且经常q等于数p的参数。距离 I $\mathbb{R}^{q}$. The dimension $q$ is typically much smaller than the dimension $n$ of the data, and often $q$ equals the number $p$ of parameters. The distance $\left|S_{j}-s^{}\right|$ in line 6 of the algorithm is the Euclidean norm in $\mathbb{R}^{q}$. Since the algorithm considers the summary statistic $s^{}=S\left(x^{*}\right)$ instead of the full data, the method can only be expected to work if $S(\theta)$ contains ‘enough’ information about $\theta$. 是一个足够的统计量,如以下定义中所述。
数学代写|统计计算作业代写STATISTICAL COMPUTING代考|APPROXIMATE BAYESIAN COMPUTATION WITH REGRESSION
上一节中描述的基本 ABC 方法在计算上可能非常昂贵。许多变种一种乙C,旨在降低计算成本,用于应用领域。在本节中,我们将描述一种构建这种改进的 ABC 变体的方法。这种方法是基于接受较大比例的样本的想法,然后对由采样值之间的差异引入的系统误差进行数值补偿sj=小号(Xj)和观测值 $s^{ }=S\left(x^{ }\right)$。
这里讨论的方法是基于样本的假设θj可以写成
θj≈F(小号j)+ej
对于所有接受j, 在哪里F(s)=和(θ∣小号=s)和ej彼此独立且独立于小号j. 如果这个关系至少近似成立,我们可以使用修改后的样本
$$
\begin{aligned}
\tilde{\theta} {j} &=f\lefts^{}\右s^{}\右+\varepsilon{j} \
&=f\leftS_{j}\右S_{j}\右+\varepsilon_{j}+f\left(s^{ }\right)-f\leftS_{j}\右S_{j}\右\
&=\theta_{j}+f\left(s^{ }\right)-f\leftS_{j}\右S_{j}\右\end{aligned} $$ 而不是θj为了变换对应的样本小号=小号j成对应于所需值 $S=s^{ }$ 的样本。下面的结果使这个想法更加严格。

计量经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
微观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写
宏观经济学代写请认准my-assignmentexpert™ Economics 经济学作业代写