如果你也在 怎样代写神经网络Neural Networks这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。神经网络Neural Networks是由一组化学连接或功能相关的神经元组成的。一个神经元可能与其他许多神经元相连,网络中的神经元和连接的总数可能很广泛。连接,称为突触,通常从轴突到树突形成,尽管树突和其他连接也是可能的。除了电信号外,还有其他形式的信号,这些信号来自于神经递质的扩散。
神经网络Neural Networks是由生物神经元组成的网络或电路,或者从现代意义上讲,是由人工神经元或节点组成的人工神经网络。因此,神经网络要么是由生物神经元组成的生物神经网络,要么是用于解决人工智能(AI)问题的人工神经网络。生物神经元的连接在人工神经网络中被建模为节点之间的权重。正的权重反映了兴奋性连接,而负值意味着抑制性连接。所有的输入都被一个权重修改并加总。这种活动被称为线性组合。最后,一个激活函数控制输出的振幅。例如,可接受的输出范围通常在0和1之间,也可以是-1和1。
my-assignmentexpert™ 神经网络Neural Networks作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的神经网络Neural Networks作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此神经网络Neural Networks作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在机器学习Machine Learning作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的机器学习Machine Learning代写服务。我们的专家在神经网络Neural Networks代写方面经验极为丰富,各种神经网络Neural Networks相关的作业也就用不着 说。
我们提供的神经网络Neural Networks及其相关学科的代写,服务范围广, 其中包括但不限于:
机器学习代写|神经网络代写Neural Networks代考|Swish
The ReLU function, which we introduced way back in Chapter 1, isn’t the only activation function that’s been tried. They’re just extremely simple to implement and extremely performant, both at the mathematical and hardware levels, and so have stood the test of time, so to speak.
This paper explores a variety of alternative activation functions and found that the swish function (discovered in this paper) produces even better results when used in networks.
Swish is defined mathematically as
$$
\begin{aligned}
&\cdots f(x)=x \cdot \operatorname{sigmoid}(\beta x)^{\cdots} \
&\cdots \operatorname{sigmoid}(y)=1 /\left(1+e^{\wedge}(-y)\right)^{\cdots}
\end{aligned}
$$
Combining these two together has the interesting property of going slightly negative around zero, whereas most traditional activation functions are always >= zero. Conceptually, this produces a smoother gradient space and by extension makes it easier for the network to learn the underlying data distribution, which translates into improved accuracy. Swish has been shown to improve performance in other reinforcement learning problem scenarios, and so it is an important activation function for you to know in general.
There are some limitations to swish from an implementation standpoint, namely, that it uses more memory than a simple ReLU. We will come back to this in the next chapter.
机器学习代写|神经网络代写Neural Networks代考|Inverted skip connections
SE (Squeeze + Excitation) block
This is an interesting paper from the Oxford Visual Geometry Group (e.g., the people who produced VGG) from 2017 , which won the ImageNet competition that year.
Conceptually, we might think of what our neural networks are actually learning as a collection of features. Then, when the network sees a picture that matches a particular collection of features, we train it to fire a particular neuron. To take things to the next level and avoid random activations, ideally for each feature map, we could define a sort of master neuron that decides whether or not the feature should activate as a whole.
This is loosely the idea of Squeeze and Excitation blocks. By taking the feature input and reducing it dramatically down (to as small as a single pixel in some cases), we allow the network to sort of train each block to teach itself as to whether or not it should fire given a particular input, so to speak. This produces state-of-the-art results, but is also computationally expensive.
EfficientNet uses a simpler variant based around combining two convolutions to produce similar results at a much cheaper cost computationally.
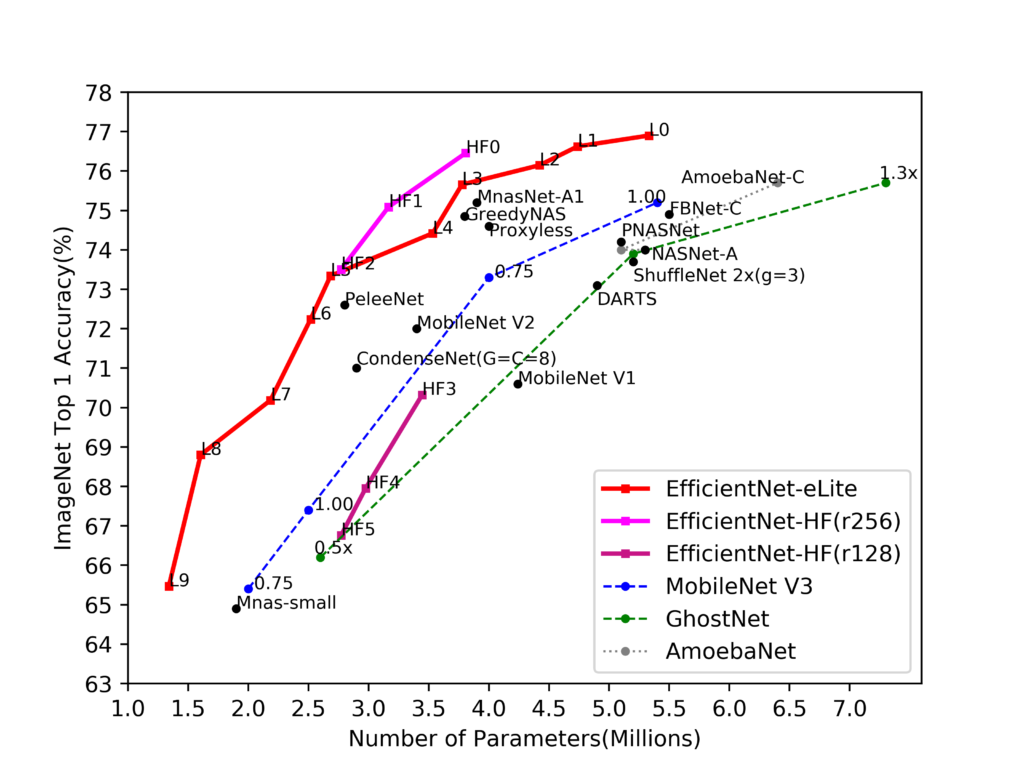
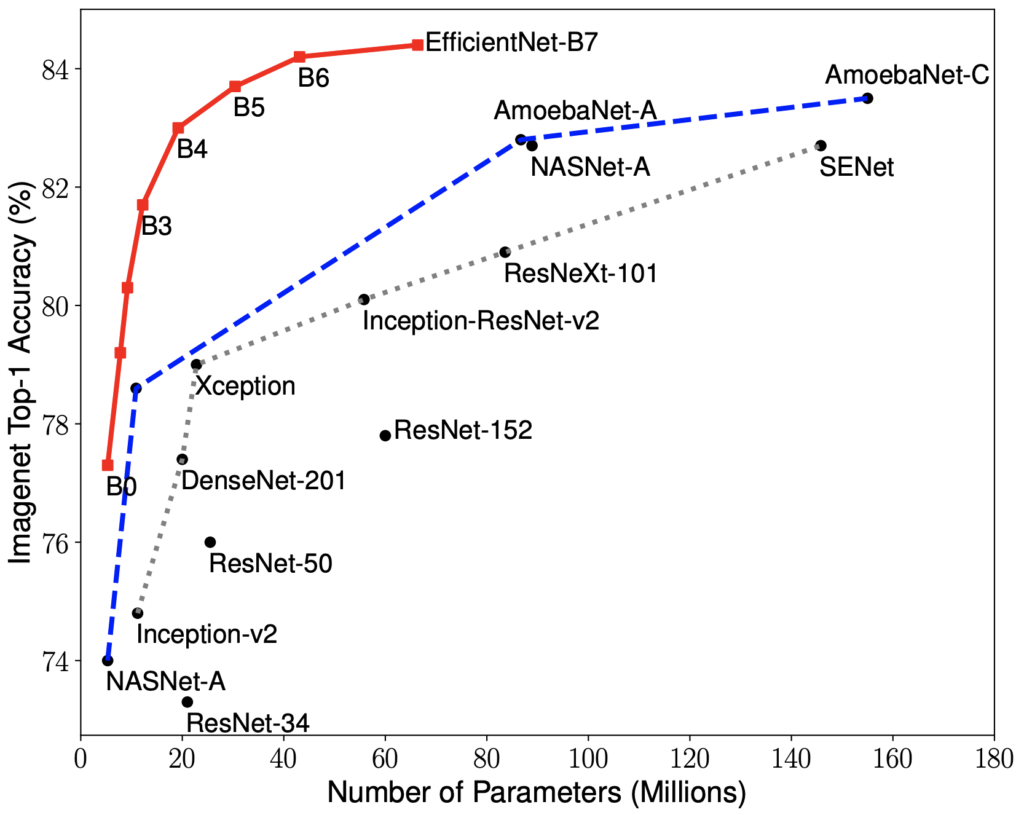
机器学习代写|神经网络代写NEURAL NETWORKS代考|EfficientNet B1-8
To play off our exploration of network architecture search functions in the last chapter, the problem with these sort of approaches is that trying to make them larger is difficult because there’s not a clear system for scaling them up.
What the authors introduce in this paper is a set of scaling heuristics for their base $(\mathrm{B} 0$ ) network that enables smooth scaling to produce larger and larger networks. Loosely speaking, we might say that each step of a larger network requires a squared amount of compute. Then, we can build large networks consistently given an extremely large amount of computational time to run on. So, here are EfficientNet variants that can be produced by simply scaling up our prior network compared to the various networks we’ve looked at so far in this book.
神经网络代写
机器学习代写|神经网络代写NEURAL NETWORKS代考|SWISH
我们在第 1 章中介绍过的 ReLU 函数并不是唯一尝试过的激活函数。它们在数学和硬件层面上实现起来都非常简单,性能也非常好,可以这么说,它们经受住了时间的考验。
本文探索了多种替代激活函数,发现 swish 函数d一世sC这在和r和d一世n吨H一世sp一种p和r在网络中使用时会产生更好的结果。
Swish 在数学上定义为
$$
\begin{aligned}
&\cdots f(x)=x \cdot \operatorname{sigmoid}(\beta x)^{\cdots} \
&\cdots \operatorname{sigmoid}(y)=1 /\left(1+e^{\wedge}(-y)\right)^{\cdots}
\end{aligned}
$$
将这两者结合在一起有一个有趣的特性,即在零附近略微为负,而大多数传统的激活函数总是 >= 零。从概念上讲,这会产生更平滑的梯度空间,并且通过扩展使网络更容易学习底层数据分布,从而提高准确性。Swish 已被证明可以在其他强化学习问题场景中提高性能,因此它是一个重要的激活函数,您通常需要了解它。
从实现的角度来看,swish 有一些限制,即它比简单的 ReLU 使用更多的内存。我们将在下一章回到这一点。
机器学习代写|神经网络代写NEURAL NETWORKS代考|INVERTED SKIP CONNECTIONS
东南小号q在和和和和+和XC一世吨一种吨一世这n块
这是牛津视觉几何组的一篇有趣的论文和.G.,吨H和p和这pl和在H这pr这d在C和d在GG从 2017 年开始,赢得了当年的 ImageNet 比赛。
从概念上讲,我们可能会将我们的神经网络实际学习的内容视为特征的集合。然后,当网络看到与特定特征集合匹配的图片时,我们训练它来激发特定的神经元。为了将事情提升到一个新的水平并避免随机激活,理想情况下,对于每个特征图,我们可以定义一种主神经元来决定该特征是否应该作为一个整体激活。
这大致就是 Squeeze 和 Excitation 块的概念。通过获取特征输入并大幅减少它吨这一种ss米一种ll一种s一种s一世nGl和p一世X和l一世ns这米和C一种s和s,我们允许网络对每个块进行某种训练,以自学它是否应该在给定特定输入的情况下触发,可以这么说。这会产生最先进的结果,但计算成本也很高。
EfficientNet 使用一个更简单的变体,该变体基于结合两个卷积来以更便宜的计算成本产生相似的结果。
机器学习代写|神经网络代写NEURAL NETWORKS代考|EFFICIENTNET B1−8
为了结束我们在上一章中对网络架构搜索功能的探索,这类方法的问题在于试图使它们更大是困难的,因为没有一个明确的系统来扩展它们。
作者在本文中介绍的是一组用于他们的基础的缩放启发式算法(乙0) 网络,可以平滑扩展以产生越来越大的网络。粗略地说,我们可以说大型网络的每一步都需要平方计算量。然后,我们可以在运行大量计算时间的情况下始终如一地构建大型网络。因此,与我们在本书中看到的各种网络相比,这里有 EfficientNet 变体,可以通过简单地扩展我们之前的网络来产生。

机器学习代写|神经网络代写Neural Networks代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
电磁学代考
物理代考服务:
物理Physics考试代考、留学生物理online exam代考、电磁学代考、热力学代考、相对论代考、电动力学代考、电磁学代考、分析力学代考、澳洲物理代考、北美物理考试代考、美国留学生物理final exam代考、加拿大物理midterm代考、澳洲物理online exam代考、英国物理online quiz代考等。
光学代考
光学(Optics),是物理学的分支,主要是研究光的现象、性质与应用,包括光与物质之间的相互作用、光学仪器的制作。光学通常研究红外线、紫外线及可见光的物理行为。因为光是电磁波,其它形式的电磁辐射,例如X射线、微波、电磁辐射及无线电波等等也具有类似光的特性。
大多数常见的光学现象都可以用经典电动力学理论来说明。但是,通常这全套理论很难实际应用,必需先假定简单模型。几何光学的模型最为容易使用。
相对论代考
上至高压线,下至发电机,只要用到电的地方就有相对论效应存在!相对论是关于时空和引力的理论,主要由爱因斯坦创立,相对论的提出给物理学带来了革命性的变化,被誉为现代物理性最伟大的基础理论。
流体力学代考
流体力学是力学的一个分支。 主要研究在各种力的作用下流体本身的状态,以及流体和固体壁面、流体和流体之间、流体与其他运动形态之间的相互作用的力学分支。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。