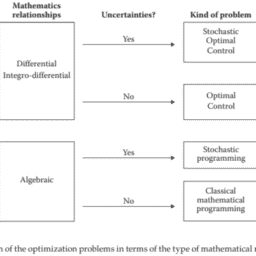
如果你也在 怎样代写随机过程Stochastic Process MTH5420这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。随机过程Stochastic Process被广泛用作系统和现象的数学模型,这些系统和现象似乎以随机的方式变化。这方面的例子包括细菌种群的生长,由于热噪声而波动的电流,或气体分子的运动。随机过程在许多学科中都有应用,如生物学、化学、生态学、 神经科学、 物理学、图像处理、信号处理、控制理论、信息理论、计算机科学、密码学和电信。
随机过程Stochastic Process过程可以被定义为由一些数学集合索引的随机变量的集合,这意味着随机过程的每个随机变量都与该集合中的一个元素唯一相关。历史上,索引集是实线的某个子集,如自然数,从而使索引集有了时间的解释。集合中的每个随机变量都从同一数学空间取值,称为状态空间。
my-assignmentexpert™随机过程Stochastic Process代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的随机过程Stochastic Process作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此随机过程Stochastic Process作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在澳洲代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的澳洲代写服务。我们的专家在随机过程Stochastic Process代写方面经验极为丰富,各种随机过程Stochastic Process相关的作业也就用不着 说。
我们提供的随机过程Stochastic Process MTH5420及其相关学科的代写,服务范围广, 其中包括但不限于:

澳洲代考|随机过程代考Stochastic Process代考|Genetic Algorithms
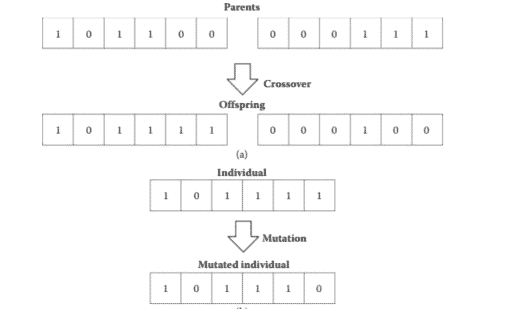
Genetic algorithms are among the first developed stochastic optimization methods. They were proposed by Holland (1975) and are a subtype of the so-called evolutionary algorithms. They emulate the evolution of a species, where the more capable individuals in a given population have higher chances to pass their genes to further generations. In mathematical terms, a solution $\bar{x}$ is an individual in the GA, and a given set of solutions forms a population. One of the particularities of the GAs is that the solutions are represented in terms of chromosomes, i.e., chains containing the genetic information of each individual. That codified representation is known as genotype, whereas the “manifestation” of the genotype, i.e., the physical/mathematical system, is known as phenotype. Some examples of chromosomes are shown in Figure 3.1, where binary, integer, and alphabetic representations can be observed. The type of representation to be used depends on the problem to be solved. Each locus (position on the chain) can show different values (alleles), and each combination of locus and values represents different solutions for the objective function $\mathrm{f}(\bar{x})$. For engineering applications, codification with real numbers is more advisable because of the similarity between the genotype and the phenotype spaces (Gen and Cheng, 2000).
Once the problem has been codified, an initial solution is required to start the algorithm. The GAs function with a set of solutions in a simultaneous way, thus the initial point is indeed a population of solutions, each one with particular characteristics (i.e., different genetic information) that differentiate it from the others. The initial population is generated randomly. Then, it is necessary to evaluate the individuals on that first generation of solutions to determine which of them are good individuals and which are bad individuals. This classification is given by the so-called fitness function, which is strongly related to the objective function. Thus, for minimization, “good individuals” are those with a low value of $f(\bar{x})$. Then, a selection procedure is started. In this step, some of the individuals in the generation are selected to reproduce and give birth to the next generation, which is expected to have better characteristics than those of the previous generation. In general, the best individuals of the generation (i.e., those with the better values of $f(\bar{x})$ have higher probabilities of being selected for reproduction). Nevertheless, other individuals can also be selected to give genetic variability in the following generation, ensuring that a wider space in the feasible region is analyzed.
澳洲代考|随机过程代考Stochastic Process代考|Differential Evolution
Differential evolution is an evolutionary method. It shares some characteristics with the GAs. It was first proposed by Storn and Price (1997) as a strategy to solve the Chebyshev polynomial fitting problem (Shaoqiang et al., 2010). Similar to the GAs, the DE method functions with generations, where each generation comprises a number of parameter vectors representing a set of solutions. It is important to recall that DE uses a real-number representation at the parameter vectors. To start with the algorithm, an initial solution is randomly generated. The solutions in the generation are evaluated through the fitness function, which is related to the objective function. To produce the next generation, an individual $\bar{x}{\mathrm{SEL}}$ is randomly selected as candidate to be substituted through the crossover operation. Here, three other individuals $\left(\bar{x}{p 1}, \bar{x}{p 2}, \bar{x}{p 3}\right)$ are selected as parents, where one of the individuals will act as the main parent. Then, a fraction of the difference between the values of each variable in the other two parents is computed. Those values are added to the value of the respective variable in the main parent, which can bexpressed as follows:
$$
\left(\bar{x}{\text {NEW }}\right)^{T}=\left(\bar{x}{p 1}\right)^{T}+F \times\left[\left(\bar{x}{p 2}\right)^{T}-\left(\bar{x}{p 3}\right)^{T}\right]
$$
where $F$ is a randomly generated number and $F \in(0,1)$ (Abbass et al., 2001). The new individual $\bar{x}{\text {NEw }}$ is then compared with the selected individual. If $\mathrm{f}\left(\bar{x}{\mathrm{NEW}}\right)$ is better than $\mathrm{f}\left(\bar{x}{\mathrm{SE}}\right)$, then $\bar{x}{\mathrm{SEI}}$ is replaced by $\bar{x}{\mathrm{NEW}}$ in the population. Otherwise, $\bar{x}{\text {SEE }}$ remains as an individual for the next generation. This operation takes place until the new generation has been completed. The procedure continues until the CC has been reached, which may imply a maximum number of generations. Figure $3.4$ shows a graphical representation of the DE method.
随机过程代写
澳洲代考|随机过程代考STOCHASTIC PROCESS代考|GENETIC ALGORITHMS
遗传算法是最早开发的随机优化方法之一。它们是由荷兰提出的1975并且是所谓的进化算法的一个子类型。它们模拟了一个物种的进化,在这个物种中,给定种群中能力更强的个体有更高的机会将他们的基因传给后代。用数学术语来说,一个解决方案X¯是 GA 中的一个个体,一组给定的解构成一个总体。遗传算法的特点之一是解决方案是用染色体表示的,即包含每个个体遗传信息的链。这种编码表示被称为基因型,而基因型的“表现”,即物理/数学系统,被称为表型。图 3.1 显示了染色体的一些示例,其中可以观察到二进制、整数和字母表示。要使用的表示类型取决于要解决的问题。每个位点p○s一世吨一世○n○n吨H和CH一个一世n可以显示不同的值一个ll和l和s,每个轨迹和值的组合代表目标函数的不同解F(X¯). 对于工程应用,由于基因型和表型空间之间的相似性,更建议使用实数进行编码G和n一个ndCH和nG,2000.
一旦问题被编码,就需要一个初始解决方案来启动算法。GAs 以同时的方式与一组解一起起作用,因此初始点确实是一组解,每个解都有特定的特征一世.和.,d一世FF和r和n吨G和n和吨一世C一世nF○r米一个吨一世○n将其与其他产品区分开来。初始种群是随机生成的。然后,有必要对第一代解决方案中的个体进行评估,以确定其中哪些是好个体,哪些是坏个体。这种分类由所谓的适应度函数给出,它与目标函数密切相关。因此,为了最小化,“好个体”是那些具有低价值的人F(X¯). 然后,开始选择过程。在这一步中,选择一代中的一些个体进行繁殖并产生下一代,预计其具有比上一代更好的特征。总的来说,这一代人中最优秀的人一世.和.,吨H○s和在一世吨H吨H和b和吨吨和r在一个l在和s○F$F(X¯$ 有更高的概率被选中进行繁殖)。尽管如此,也可以选择其他个体在下一代中给出遗传变异性,确保分析可行区域中更广阔的空间。
澳洲代考|随机过程代考STOCHASTIC PROCESS代考|DIFFERENTIAL EVOLUTION
差分进化是一种进化方法。它与 GA 有一些共同的特点。它首先由斯托恩和普莱斯提出1997作为解决切比雪夫多项式拟合问题的策略小号H一个○q一世一个nG和吨一个l.,2010. 与 GA 类似,DE 方法具有代数,其中每一代都包含许多参数向量,代表一组解。重要的是要记住 DE 在参数向量处使用实数表示。从算法开始,随机生成一个初始解。生成中的解是通过与目标函数相关的适应度函数来评估的。为了产生下一代,一个单独的 $\bar{x}{\mathrm{SEL}}$ is randomly selected as candidate to be substituted through the crossover operation. Here, three other individuals $\left(\bar{x}{p 1}, \bar{x}{p 2}, \bar{x}{p 3}\right)$
$$
\left(\bar{x}{\text {NEW }}\right)^{T}=\left(\bar{x}{p 1}\right)^{T}+F \times\left[\left(\bar{x}{p 2}\right)^{T}-\left(\bar{x}{p 3}\right)^{T}\right]
$$
其中F是一个随机生成的数字,并且$F \in(0,1)$ (Abbass et al., 2001). The new individual $\bar{x}{\text {NEw }}$ is then compared with the selected individual. If $\mathrm{f}\left(\bar{x}{\mathrm{NEW}}\right)$ is better than $\mathrm{f}\left(\bar{x}{\mathrm{SE}}\right)$, then $\bar{x}{\mathrm{SEI}}$ is replaced by $\bar{x}{\mathrm{NEW}}$ in the population. Otherwise, $\bar{x}{\text {SEE }}$ remains as an individual for the next generation. This operation takes place until the new generation has been completed. The procedure continues until the CC has been reached, which may imply a maximum number of generations. Figure $3.4$ .显示了 DE 方法的图形表示。

澳洲代考|随机过程代考Stochastic Process代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。