如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。

计算机代写|机器学习代写Machine Learning代考|ML code smells
Sometimes you look at a code base and just know something is not right. The mistakes you see in formatting, collection handling, lack of appropriate recursion, or quantity of dead code can give you a sense of the overall health of a code base. If they’re bad enough, even the most junior members of a team can identify them.
More insidious problems might be much harder for a junior DS to identify but can be clear to more senior members of the team. These “smells” within the code (a term famously coined by Martin Fowler) are indicative of potentially crippling problems that may arise elsewhere, directly impacting production stability or making the code nigh-impossible to debug if a problem happens.
Table 10.1 lists some of the more common code smells that I see in ML code bases. While the ones listed are not catastrophic, per se, they typically are the first sign that I have that “all is not well in Denmark.” Finding one of these code smells generally means that one of the more insidious issues that will likely affect production stability is contained somewhere in the code base. Learning to recognize these issues, setting plans to address the technical debt of them, and working to learn techniques to avoid these in ML projects can significantly reduce the refactoring and repair work that the ML team will have to do in the future.
This chapter is focused on the five most frequent “deadly” errors. These are the crippling problems that create fundamentally broken ML code bases. Seeing these sorts of issues would likely mean a pager duty call at least once per week.
If a project contains a small number of the issues described in this chapter, it’s not guaranteed to fail. The project may be onerous and confusing to continue developing, or incredibly unpleasant to maintain, but that doesn’t mean it won’t run and serve its intended purpose.
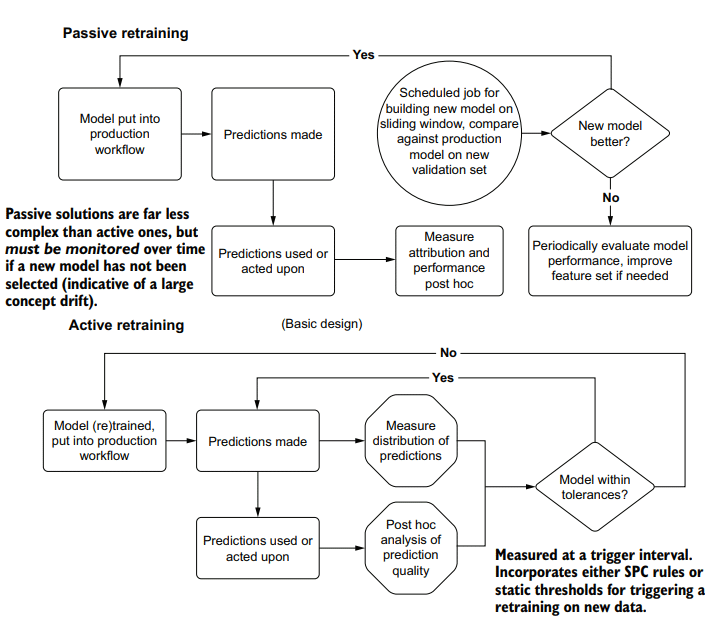
However, if the code base is riddled with multiple instances of each type of problem, the chances that you’re going to sleep well through your on-call week are pretty grim. Figure 10.1 shows the relationship between the severity of these issues and their potential effect on the outcome of the final project.
计算机代写|机器学习代写Machine Learning代考|Naming, structure, and code architecture
Someone who is on on-call support experiences few more exhausting and panicinducing scenarios than realizing that the job that just broke and requires investigation is “that one” This code is so overly confusing, complicated, and monkey-patched that when it breaks, the original author is usually called in to fix it. What makes it even worse is knowing that person left the company-two months ago. And now you have to fix their code.
Digging into it, all you see are obscure acronyms as variable names, massive walls of code within functions, classes with dozens of unrelated methods thrown in haphazardly, unhelpful inline comments, and thousands of lines of commented-out code. It’s basically the worst of both worlds: both a bowl of spaghetti code (control flow in the code organized as well as noodles in a bowl of spaghetti) and a ball of mud (effectively a morass of individual bowls of spaghetti with duplicated code, global references, dead code, and no seeming architectural design for maintainability).
A lot of ML code tends to look like this, unfortunately, and it can be remarkably frustrating to diagnose and refactor. Let’s take a look at a few bad habits regarding naming, structure, and architecture, as well as better alternatives to those bad practices.
Naming conventions and structure
Naming variables can be a bit of a tricky exercise. Some schools of thought subscribe to the “less is more” philosophy, where the most succinct (shortest) code is best. Others, including myself, when writing non-ML code, tend to stick to more verbose naming conventions. As mentioned in chapter 9, the computer doesn’t care at all how you name things (provided that you’re not, as shown in listing 10.1, using a reserved keyword for a structure as a variable name).
Let’s look at a dense representation of some naming issues. From lazy abbreviations (shorthand placeholder variable names) to unintelligible cipher-like names and a reserved function name, this listing has more than a few problems.

机器学习代写
计算机代写|机器学习代写Machine Learning代考|ML code smells
有时您查看代码库,就知道有些地方不对。在格式化、集合处理、缺乏适当的递归或死代码数量方面看到的错误可以让您了解代码库的整体健康状况。如果它们足够糟糕,即使是团队中最初级的成员也能识别它们。
对于资历较浅的DS来说,更隐蔽的问题可能更难识别,但对于团队中较资深的成员来说,可能很清楚。代码中的这些“气味”(Martin Fowler创造的一个著名术语)表明可能在其他地方出现潜在的严重问题,直接影响生产稳定性,或者在问题发生时使代码几乎无法调试。
表10.1列出了我在ML代码库中看到的一些更常见的代码气味。虽然列出的这些问题本身并不是灾难性的,但它们通常是我认为“丹麦一切都不好”的第一个迹象。找到这些代码中的气味通常意味着可能影响产品稳定性的潜在问题包含在代码库的某个地方。学会识别这些问题,制定解决它们的技术债务的计划,并努力学习在ML项目中避免这些问题的技术,可以显着减少ML团队将来必须做的重构和修复工作。
本章主要讨论五个最常见的“致命”错误。这些都是严重的问题,从根本上破坏了ML代码库。看到这些问题可能意味着每周至少要打一次呼机值班电话。
如果一个项目包含本章中描述的少量问题,它并不一定会失败。项目继续开发可能是繁重和令人困惑的,或者维护起来令人难以置信的不愉快,但这并不意味着它不会运行并服务于预期的目的。
然而,如果代码库充斥着每种类型的问题的多个实例,那么您在随叫随到的一周中睡个好觉的机会就非常渺茫了。图10.1显示这些问题的严重程度与它们对最终工程项目结果的潜在影响之间的关系。
计算机代写|机器学习代写Machine Learning代考|Naming, structure, and code architecture
对于随时待命的支持人员来说,很少有比意识到刚刚中断并需要调查的工作是“那一个”更令人疲惫和恐慌的场景了。这段代码过于令人困惑、复杂,而且打了很多补丁,以至于当它中断时,通常会叫原作者来修复它。更糟糕的是,你知道那个人两个月前就离开了公司。现在你得修改他们的代码。
深入研究它,您所看到的只是模糊的首字母缩略词作为变量名、函数内的大量代码墙、类中随意抛出的数十个不相关的方法、无益的内联注释以及数千行注释掉的代码。它基本上是两个世界中最糟糕的:一碗意大利面代码(组织好的代码中的控制流和一碗意大利面中的面条)和一团泥(实际上是一堆带有重复代码、全局引用、死代码和表面上没有可维护性的架构设计的意大利面碗)。
不幸的是,很多ML代码都是这样的,诊断和重构非常令人沮丧。让我们来看看一些关于命名、结构和体系结构的坏习惯,以及替代这些坏习惯的更好的方法。
命名约定和结构
命名变量可能是一个有点棘手的练习。一些思想流派赞同“少即是多”的哲学,即最简洁(最短)的代码是最好的。其他人,包括我自己,在编写非ml代码时,倾向于坚持更冗长的命名约定。正如第9章所提到的,计算机根本不关心您如何命名事物(只要您没有像清单10.1所示的那样,使用结构体的保留关键字作为变量名)。
让我们看一下一些命名问题的密集表示。从惰性缩写(简写占位符变量名)到难以理解的类似密码的名称和保留的函数名,这个清单存在很多问题。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。