如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。

计算机代写|机器学习代写Machine Learning代考|Scalability and concurrency
Throughout this project that we’ve been working on, the weightiest and most complex aspect of the solution has been in scalability. When we talk about scalability here, we’re actually referring to cost. The longer that VMs are running and executing our project code, the more the silent ticker of our bill is going up. Anything that we can do to maximize resource utilization of that hardware as a function of time is going to keep that bill in a manageable state, reducing the concern that the business will have about the total cost of the solution.
Throughout the second half of chapter 7 , we evaluated two strategies for scaling our problem to support modeling many airports. The first, parallelizing the hyperparameter evaluation over a cluster, scaled down the per-model training time significantly as compared to the serial approach. The second, parallelizing the actual permodel training across a cluster, scaled the solution in a slightly different way (which is more in favor of the many models/reasonable training iterations approach), reducing our cost footprint for the solution in a much larger manner.
As mentioned in chapter 7 , these are but two ways of scaling this problem, both involving parallel implementations that distribute portions of the modeling process across multiple machines. However, we can add a layer of additional processing to speed these operations up even more. Figure 8.7 shows an overview of our options for increasing the throughput for ML tasks to reduce the wall-clock time involved in building a solution.
Moving down the scale in figure 8.7 brings a trade-off between simplicity and performance. For problems that require a scale that distributed computing can offer, it is important to understand the level of complexity that will be introduced into the code base. The challenges with these implementations are no longer relegated to the DS part of the solution and instead require increasingly sophisticated engineering skills in order to build.
Gaining the knowledge and ability to build large-scale ML projects that leverage systems capable of handling distributed computation (for example, Spark, Kubernetes, or Dask) will help ensure that you are capable of implementing solutions requiring scale. In my own experience, my time has been well spent learning how to leverage concurrency and the use of distributed systems to accelerate the performance and reduce the cost of projects by monopolizing available hardware resources as much as I can.
For the purposes of brevity, we won’t go into examples of implementing the last two sections of figure 8.7 within this chapter. However, we will touch on examples of concurrent operations later in this book.
计算机代写|机器学习代写Machine Learning代考|What is concurrency?
In figure 8.7 , you can see the term concurrency listed in the bottom two solutions. For most data scientists who don’t come from a software engineering background, this term may easily be misconstrued as parallelism. It is, after all, effectively doing a bunch of things at the same time.
Concurrency, by definition, is the act of executing many tasks at the same time. It doesn’t imply ordering or sequential processing of tasks simultaneously. It merely requires that a system and the code instructions being sent to it be capable of running more than one task at the same time.
Parallelism, on the other hand, works by dividing tasks into subtasks that can be executed in parallel, simultaneously, on discrete threads and cores of a CPU or GPU. Spark, for instance, executes tasks in parallel on a distributed system of discrete cores in executors.
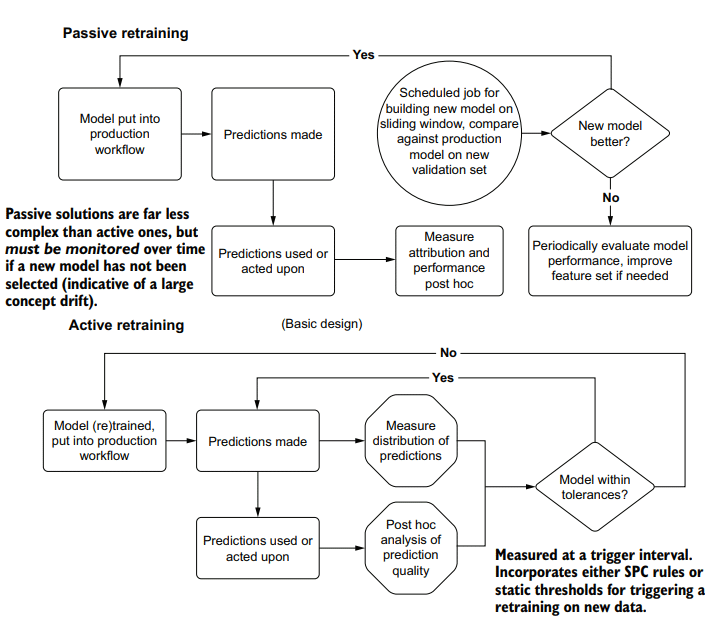
These two concepts can be combined in a system that can support them, one of multiple machines, each of which has multiple cores available to it. This system architecture is shown in the final bottom section of figure 8.7. Figure 8.8 illustrates the differences between parallel execution, concurrent execution, and the hybrid parallelconcurrent system.
Leveraging these execution strategies for the appropriate type of problem being solved can dramatically improve the cost of a project. While it may seem tempting to utilize the most complex approach for every problem (parallel concurrent processing in a distributed system), it simply isn’t worth it. If the problem that you’re trying to solve can be implemented on a single machine, it’s always best to reduce the infrastructure complexity by going with that approach. It’s advisable to move down the path of greater infrastructure complexity only when you need to. This is particularly true when the data, the algorithm, or the scale of tasks is so large that a simpler approach is not possible.

机器学习代写
计算机代写|机器学习代写Machine Learning代考|Scalability and concurrency
在我们一直致力于的这个项目中,解决方案中最重要和最复杂的方面是可伸缩性。当我们在这里谈论可扩展性时,我们实际上指的是成本。vm运行和执行我们的项目代码的时间越长,我们的账单就会越长。作为时间的函数,我们可以做的任何事情来最大化硬件的资源利用率,都将使该账单处于可管理的状态,从而减少业务对解决方案的总成本的担忧。
在第7章的后半部分,我们评估了两种扩展问题的策略,以支持对许多机场进行建模。首先,在集群上并行化超参数评估,与串行方法相比,显著降低了每个模型的训练时间。第二种方法是跨集群并行化实际的超模型训练,以一种稍微不同的方式扩展解决方案(这更有利于多模型/合理的训练迭代方法),以更大的方式减少解决方案的成本占用。
正如第7章所提到的,这只是扩展这个问题的两种方法,都涉及到在多台机器上分布部分建模过程的并行实现。然而,我们可以添加一个额外的处理层来加快这些操作的速度。图8.7显示了增加ML任务吞吐量以减少构建解决方案所涉及的时钟时间的选项概述。
向下移动图8.7中的规模需要在简单性和性能之间进行权衡。对于需要分布式计算所能提供的规模的问题,理解将引入代码库的复杂程度是很重要的。这些实现的挑战不再是解决方案的DS部分,而是需要越来越复杂的工程技能来构建。
获得构建大型ML项目的知识和能力,利用能够处理分布式计算的系统(例如,Spark, Kubernetes或Dask)将有助于确保您能够实现需要规模的解决方案。根据我自己的经验,我把时间花在学习如何利用并发性和使用分布式系统上,通过尽可能多地垄断可用的硬件资源来加速性能和降低项目成本。
为简洁起见,我们在本章中将不讨论实现图8.7最后两个部分的示例。但是,我们将在本书后面的部分涉及并发操作的示例。
计算机代写|机器学习代写Machine Learning代考|What is concurrency?
在图8.7中,您可以看到下面两个解决方案中列出了术语并发性。对于大多数没有软件工程背景的数据科学家来说,这个术语很容易被误解为并行。毕竟,它是在同一时间有效地做一堆事情。
根据定义,并发是同时执行许多任务的行为。它并不意味着同时对任务进行排序或顺序处理。它只要求系统和发送给它的代码指令能够同时运行多个任务。
另一方面,并行性通过将任务划分为子任务来工作,这些子任务可以在CPU或GPU的离散线程和内核上并行、同时执行。例如,Spark在执行器中离散内核的分布式系统上并行执行任务。
这两个概念可以结合在一个支持它们的系统中,即多台机器中的一台,每台机器都有多个可用的内核。这个系统架构显示在图8.7的最后底部部分。图8.8说明了并行执行、并发执行和混合并行并发系统之间的区别。
利用这些执行策略来解决适当类型的问题可以显著地提高项目的成本。虽然对每个问题(分布式系统中的并行并发处理)使用最复杂的方法似乎很诱人,但这根本不值得。如果您试图解决的问题可以在一台机器上实现,那么最好采用这种方法来降低基础设施的复杂性。只有在需要的时候,才建议使用更复杂的基础设施。当数据、算法或任务规模如此之大,以至于不可能采用更简单的方法时,尤其如此。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。