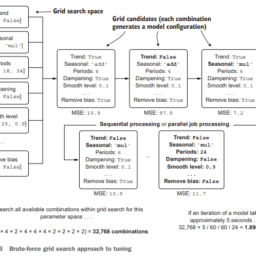
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
计算机代写|机器学习代写Machine Learning代考|COMP5318
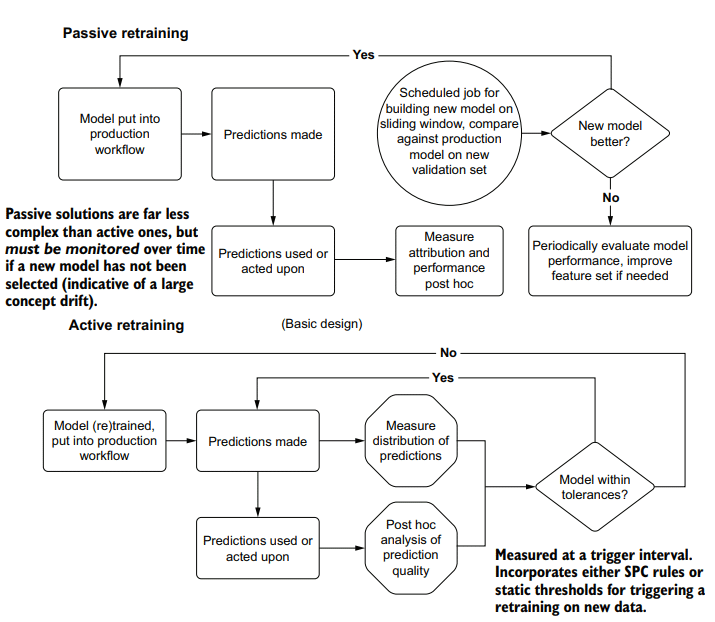
It all starts with monitoring. For our ice cream coupon scenario, that involves building ETL processes for not only our predictions (safely storing each batch of predictions for analytics use cases), but also basic statistical measurement attributes to use for setting triggered alerts about model health.
Let’s revisit the outside temperature measurements that are being fed as a feature into our model from chapter 11. Figure 12.5 shows a visual example of how, by setting three separate checks on the temperature feature, we could detect issues in the underlying data.
This plot is intended to be a visual aid only. In practice, alerts would be configured through calculations performed on the data, triggering if the boundary shift magnitude crosses a predetermined threshold purely based on logic written in code. The three regions identified in this plot, though, are examples of rules that should be embedded in monitoring code that can alert the team to an issue in the input features to the model.
The first identified detection (step change alerting on the mean) is useful for detecting large, unexpected deviations that may prove problematic for a model’s predictive capability. Rules like this are relatively trivial to implement, can have configured thresholds, and are an effective early-warning system for the ML team to intervene immediately when the new data arrives.
The second detection type (step change in the values of data variance) generally requires a bit more time to trigger. The variance of the same value (temperature) on different scales (Celsius versus Fahrenheit) is intrinsically different. As such, the total variance of the data will show a marked difference. However, to reduce the chances of false-positive warnings on discrete periods of time, alarm conditions concerned with variance monitoring generally require longer periods to trigger.
The third indication type, although coinciding with the shift in the mean, is a dramatic increase in variation that has not been historically observed. When large peaks occur in variation measurements (typically far larger than the changes that would be monitored by the second case in this example), an investigation is warranted into the state of the data being measured.
At the very least, to protect against both the slow entropic decay of model effectiveness and the foundational disruptive events seen in figure 12.5, we need to be measuring aspects of our models. Feature monitoring, training label drift measurement, model validation metrics, and attribution metrics are all elements that make up an effective strategy to identify drift.
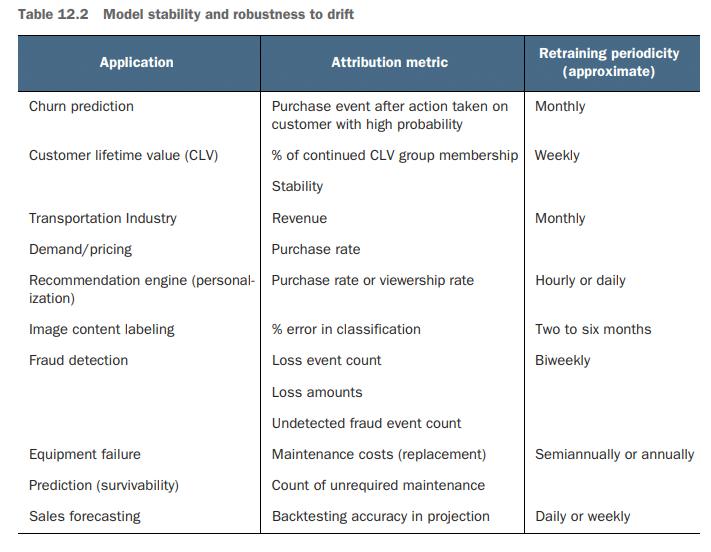
Table 12.2 illustrates common types of modeling that I’ve seen and worked on in different industries and a general estimate of how long stability held before a retraining event was required, for perspective.
计算机代写|机器学习代写Machine Learning代考|Responding to drift
For our example of temperature drift shown previously in figure 12.5 , the response to repairing the drift condition is trivial. We can apply a feature conversion to the older data to bring it in line with the new scaling of the temperature values. Identifying, isolating, and repairing issues that are obvious and trivial to correct is, well, obvious. Just fix it and move on.
Unfortunately, not every problem is so simple. What if we can’t readily identify what is causing a degradation in the model? We have four primary means of responding to drift:
- Scheduled or triggered retraining, with validation of results against the prior model, and new model against new validation data. Keep the best one.
- For obvious issues (for example, ETL errors, explosions in cardinality, or shifts in variance of features), either repair or scale the features, retrain the model, validate its performance on new holdout data, and continue running as before on the new model.
- For prediction degradation issues that are not related to the obvious factors mentioned in the preceding list item, revisit feature engineering, and conduct exploratory data analysis and correlation analysis. Determine if any new features need to be added or existing features need to be removed. Attempt to retrain and release a new validated model to production.
- If the model shows a negative business impact that is statistically significant, stop using the model immediately. Attempt to perform root cause analysis and repair the issue (if possible). If the benefit of the model is no longer present, shut it down permanently.
机器学习代写
计算机代写|机器学习代写Machine Learning代考|What can we do about it?
这一切都始于监控。对于我们的冰淇淋券场景,这不仅包括为我们的预测(为分析用例安全地存储每批预测)构建ETL流程,还包括用于设置关于模型健康的触发警报的基本统计度量属性。
让我们回顾一下第11章中作为特征输入模型的外部温度测量。图12.5显示了一个可视化示例,通过在温度特性上设置三个独立的检查,我们可以检测底层数据中的问题。
这个情节只是作为视觉辅助。在实践中,警报将通过对数据执行的计算来配置,如果边界位移幅度超过一个完全基于代码编写的逻辑的预定阈值,就会触发警报。但是,在此图中标识的三个区域是应该嵌入到监视代码中的规则示例,这些规则可以提醒团队注意模型输入特性中的问题。
第一个确定的检测(对平均值的阶跃变化警报)对于检测可能证明对模型的预测能力有问题的大的、意外的偏差是有用的。这样的规则相对容易实现,可以配置阈值,并且是ML团队在新数据到达时立即进行干预的有效预警系统。
第二种检测类型(数据方差值的阶跃变化)通常需要更多的时间来触发。同一值(温度)在不同尺度上(摄氏度与华氏度)的方差本质上是不同的。这样,数据的总方差就会显示出显著的差异。然而,为了减少在离散时间内出现误报警告的机会,与方差监测有关的警报条件通常需要更长的时间来触发。
第三种迹象类型虽然与平均值的变化相吻合,但在历史上从未观察到的变化急剧增加。当变化测量中出现较大的峰值时(通常比本例中第二种情况所监视的变化大得多),需要对所测量数据的状态进行调查。
至少,为了防止模型有效性的缓慢熵衰减和图12.5所示的基本破坏性事件,我们需要测量模型的各个方面。特征监控、训练标签漂移测量、模型验证度量和归因度量都是组成有效的漂移识别策略的要素。
表12.2说明了我在不同行业中见过并参与过的常见建模类型,以及对需要再培训事件之前的稳定性维持时间的一般估计。
计算机代写|机器学习代写Machine Learning代考|Responding to drift
对于前面图12.5所示的温度漂移示例,修复漂移条件的响应是微不足道的。我们可以对旧数据应用特征转换,使其与新的温度值缩放一致。识别、隔离和修复需要纠正的明显而琐碎的问题是显而易见的。把它修好,然后继续生活。
不幸的是,并非所有问题都如此简单。如果我们不能很容易地确定是什么导致了模型的退化怎么办?我们有四种应对漂移的主要方法:
计划或触发的再训练,根据先前的模型验证结果,并根据新的验证数据验证新模型。保留最好的一个。
对于明显的问题(例如,ETL错误、基数爆炸或特征方差的变化),可以修复或缩放特征,重新训练模型,在新的保留数据上验证其性能,然后在新模型上像以前一样继续运行。
对于与上述明显因素无关的预测退化问题,重新进行特征工程,并进行探索性数据分析和相关性分析。确定是否需要添加新功能或删除现有功能。尝试重新培训并将新的验证模型发布到生产中。
如果模型显示出具有统计意义的负面业务影响,请立即停止使用该模型。尝试执行根本原因分析并修复问题(如果可能)。如果模型的好处不再存在,永久关闭它。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。