如果你也在 怎样代写生存模型Survival Models这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。生存模型Survival Models在许多可用于分析事件时间数据的模型中,有4个是最突出的:Kaplan Meier模型、指数模型、Weibull模型和Cox比例风险模型。
生存模型Survival Models精算师和其他应用数学家使用预测人类或其他实体(有生命或无生命)生存模式的模型,并经常使用这些模型作为相当重要的财务计算的基础。具体来说,精算师使用这些模型来计算与个人人寿保险单、养老金计划和收入损失保险相关的财务价值。人口统计学家和其他社会科学家使用生存模型对该模型适用的人口的未来构成做出预测。
生存模型Survival Models代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。最高质量的生存模型Survival Models作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此生存模型Survival Models作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
统计代写|生存模型代考Survival Models代写|Properties of the Estimator
The product-limit estimator is unbiased and consistent.
For the variance of the estimator, let us consider
$$
\hat{p}x=\prod{i=1}^m \hat{p}i $$ which comes directly from (7.63). Recall that each $\hat{p}_i$ is a binomial proportion, conditional on its sample size $n_i$. Then all $\hat{p}_i$ ‘s are conditionally mutually independent, and, being binomial proportions, they are unbiased. Therefore, the conditions of Section 6.5 hold here, so by steps analogous to those leading to Equation (6.45), we find $$ \operatorname{Var}\left(\hat{p}_x \mid\left{n_i\right}\right)=\left(p_x\right)^2 \cdot\left[\prod{i=1}^m\left(\frac{q_i}{p_i n_i}+1\right)-1\right] .
$$
Since $\hat{q}x=1-\hat{p}_x$, it follows that (7.68) is $\operatorname{Var}\left(\hat{q}_x \mid\left{n_i\right}\right)$ as well. By the same steps as those leading from $(6.45)$ to (6.46), we can obtain the Greenwood approximation $$ \operatorname{Var}\left(\hat{q}_x \mid\left{n_i\right}\right)=\operatorname{Var}\left(\hat{p}_x \mid\left{n_i\right}\right) \approx\left(p_x\right)^2 \cdot \sum{i=1}^m\left(\frac{q_i}{p_i n_i}\right)
$$
统计代写|生存模型代考Survival Models代写|Estimation of $S(t)$
Let us assume a sample of $n$ persons all observed from time $t=0$ on the follow-up scale. If the study is halted before all have died, then we will have terminations from the sample at various values of $t$.
In clinical studies it is customary to use the approach of partitioning at each death point. Then if $r_j$ is the risk set immediately preceding the $j^{\text {th }}$ death point (which, in general, has $d_j$ deaths, with $d_j$ most frequently being one), we have, as before,
$$
\hat{q}j=\frac{d_j}{r_j} $$ Note that $\hat{q}_j$ estimates the probability of death over the interval which ends at the $j^{\text {th }}$ death point, given alive at the beginning of that interval; it is not the probability of death over an interval which begins at $t=j$. Then $$ \hat{S}\left(t_m\right)=\prod{j=1}^m\left(1-q_j\right)=\prod_{j=1}^m\left(\frac{r_j-d_j}{r_j}\right)
$$
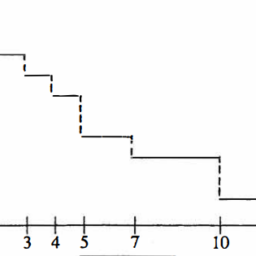
estimates the probability of survival from $t=0$ to $t=t_m$, the time of the $m^{t h}$ death point. For all $t$ such that $t_m \leq t<t_{m+1}$, the estimate of $S(t)$ is the same as $\hat{S}\left(t_m\right)$, since there are no deaths in the sample between $t_m$ and $t$. Thus
$$
\hat{S}(t)=\prod_{j=1}^m\left(\frac{r_j-d_j}{r_j}\right) \text { for } t_m \leq t<t_{m+1}, m=1,2, \ldots
$$
生存模型代考
统计代写|生存模型代考Survival Models代写|Properties of the Estimator
产品极限估计量是无偏一致的。
对于估计量的方差,让我们考虑
$$
\hat{p}x=\prod{i=1}^m \hat{p}i $$直接来自(7.63)。回想一下,每个$\hat{p}_i$都是一个二项比例,取决于其样本量$n_i$。那么所有的$\hat{p}_i$都是有条件的相互独立的,并且,作为二项比例,它们是无偏的。因此,第6.5节的条件在这里成立,因此通过与式(6.45)类似的步骤,我们找到$$ \operatorname{Var}\left(\hat{p}_x \mid\left{n_i\right}\right)=\left(p_x\right)^2 \cdot\left[\prod{i=1}^m\left(\frac{q_i}{p_i n_i}+1\right)-1\right] .
$$
既然$\hat{q}x=1-\hat{p}_x$,那么(7.68)也是$\operatorname{Var}\left(\hat{q}_x \mid\left{n_i\right}\right)$。通过与从$(6.45)$到(6.46)相同的步骤,我们可以得到格林伍德近似 $$ \operatorname{Var}\left(\hat{q}_x \mid\left{n_i\right}\right)=\operatorname{Var}\left(\hat{p}_x \mid\left{n_i\right}\right) \approx\left(p_x\right)^2 \cdot \sum{i=1}^m\left(\frac{q_i}{p_i n_i}\right)
$$
统计代写|生存模型代考Survival Models代写|Estimation of $S(t)$
让我们假设一个$n$人的样本,所有人都从$t=0$时间开始观察。如果研究在所有人死亡之前停止,那么我们将在$t$的不同值处终止样本。
在临床研究中,习惯上使用在每个死亡点划分的方法。那么,如果$r_j$是紧靠$j^{\text {th }}$死亡点之前的风险集(一般来说,该死亡点有$d_j$人,其中$d_j$最常是1人),我们有,和之前一样,
$$
\hat{q}j=\frac{d_j}{r_j} $$请注意,$\hat{q}j$估计在$j^{\text {th }}$死亡点结束的区间内的死亡概率,假设在该区间开始时还活着;它不是从$t=j$开始的一段时间内的死亡概率。然后$$ \hat{S}\left(t_m\right)=\prod{j=1}^m\left(1-q_j\right)=\prod{j=1}^m\left(\frac{r_j-d_j}{r_j}\right)
$$
估计存活概率从$t=0$到$t=t_m$, $m^{t h}$死亡点的时间。对于所有$t$这样的$t_m \leq t<t_{m+1}$, $S(t)$的估计值与$\hat{S}\left(t_m\right)$相同,因为在$t_m$和$t$之间的样本中没有死亡。因此
$$
\hat{S}(t)=\prod_{j=1}^m\left(\frac{r_j-d_j}{r_j}\right) \text { for } t_m \leq t<t_{m+1}, m=1,2, \ldots
$$

统计代写|生存模型代考Survival Models代写 请认准exambang™. exambang™为您的留学生涯保驾护航。