如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
计算机代写|机器学习代写Machine Learning代考|The dangers of a data silo
Data silos are deceptively dangerous. Isolating data in a walled-off, private location that is accessible only to a certain select group of individuals stifles the productivity of other teams, causes a large amount of duplicated effort throughout an organization, and frequently (in my experience of seeing them, at least) leads to esoteric data definitions that, in their isolation, depart wildly from the general accepted view of a metric for the rest of the company.
It may seem like a really great thing when an ML team is granted a database of its own or an entire cloud object store bucket to empower the team to be self-service. The seemingly geologically scaled time spent for the DE or warehousing team to load required datasets disappears. The team members are fully masters of their domain, able to load, consume, and generate data with impunity. This can definitely be a good thing, provided that clear and soundly defined processes govern the management of this technology.
But clean or dirty, an internal-use-only data storage stack is a silo, the contents squirreled away from the outside world. These silos can generate more problems than they solve.
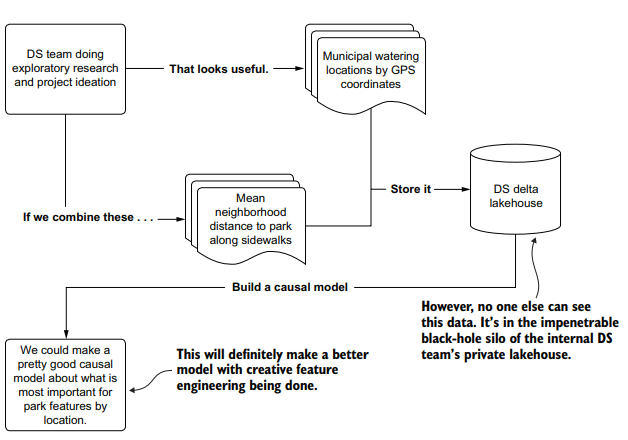
To show how a data silo can be disadvantageous, let’s imagine that we work at a company that builds dog parks. Our latest ML project is a bit of a moon shot, working with counterfactual simulations (causal modeling) to determine which amenities would be most valuable to our customers at different proposed construction sites. The goal is to figure out how to maximize the perceived quality and value of the proposed parks while minimizing our company’s investment costs.
To build such a solution, we have to get data on all of the registered dog parks in the country. We also need demographic data associated with the localities of these dog parks. Since the company’s data lake contains no data sources that have this information, we have to source it ourselves. Naturally, we put all of this information in our own environment, thinking it will be far faster than waiting for the DE team’s backlog to clear enough to get around to working on it.
计算机代写|机器学习代写Machine Learning代考|Fallbacks and cold starts
Let’s imagine that we’ve just built an ML-powered solution for optimizing delivery routes for a pizza company. Some time ago, the business approached us, asking for a cheaper, faster, and more adaptable solution to optimizing the delivery routes of a single driver. The prior method for figuring out which addresses a certain driver would deliver the pizzas to was done by a pathing algorithm that generated optimal routes based on ArcGIS. While capable and quite fully featured, the business wanted something that considered the temporal nature and history of actual delivery data to create a more effective route.
The team worked on an LSTM-based approach that was trained on the last three years of delivery data, creating an adversarial network with reinforcement learning that rewarded optimal pathing based on timeliness of delivery. The project quickly advanced from a science project to something that was proving its worth in a handful of regions. It was far more adept at selecting delivery sequences than the brute-force pathing that their previous production system was capable of.
After reviewing several weeks’ worth of routing data in the test markets, the business felt comfortable with turning on the system for all delivery routes. Things looked pretty good. Predictions were being served, drivers were spending less time stuck in traffic, and pizza was delivered hot at a much higher rate than ever before.
It took about a week before the complaints began pouring in. Customers in rural areas were complaining of very long delivery times at a frighteningly high rate. After looking at the complaints, the pattern began to emerge that every complaint was always with the last stop on a delivery chain. It didn’t take long for the DS team to realize what was happening. With most of the training data focused on urban centers, the volume of drop-offs and the lower proximity between stops meant that an optimized stop count was being targeted in general for the model. When this delivery count was applied to a rural environment, the sheer distances involved meant that nearly all final-stop delivery customers would be greeted with a room-temperature pizza.
Without a fallback control on the length of routes or the estimated total delivery time, the model was optimizing routes for the minimal amount of time for the total delivery run volume, regardless of how long that total estimated time would be. The solution lacked a backup plan. It didn’t have a fallback to use existing geolocation services (the ArcGIS solution for rural routes) if the model’s output violated a business rule (don’t deliver cold pizza).
机器学习代写
计算机代写|机器学习代写Machine Learning代考|The dangers of a data silo
数据孤岛看起来很危险。将数据隔离在一个封闭的私有位置,只有特定的一组个人可以访问,这会扼杀其他团队的生产力,在整个组织中导致大量的重复工作,并且经常(至少在我看到他们的经验中)导致深奥的数据定义,在他们的隔离中,与公司其他部分普遍接受的度量标准观点背道而驰。
当ML团队被授予自己的数据库或整个云对象存储桶以授权团队进行自助服务时,这似乎是一件非常棒的事情。DE或仓库团队加载所需数据集所花费的时间似乎是按地质比例计算的。团队成员完全掌握了他们的领域,能够不受惩罚地加载、使用和生成数据。这绝对是一件好事,前提是该技术的管理有清晰而完善的流程定义。
但是,无论是干净的还是脏的,仅供内部使用的数据存储堆栈都是一个筒仓,其内容与外部世界隔绝。这些竖井产生的问题比它们解决的问题要多。
为了说明数据孤岛是多么的不利,让我们想象一下,我们在一家建造狗公园的公司工作。我们最新的机器学习项目有点像登月,使用反事实模拟(因果模型)来确定在不同的拟建工地,哪些设施对我们的客户最有价值。我们的目标是找出如何最大限度地提高拟建公园的质量和价值,同时最大限度地降低公司的投资成本。
为了建立这样的解决方案,我们必须获得全国所有注册狗公园的数据。我们还需要与这些狗公园所在地相关的人口统计数据。由于公司的数据湖不包含包含此信息的数据源,因此我们必须自己查找。很自然地,我们把所有这些信息放在我们自己的环境中,认为这样做比等待DE团队的待办事项清理干净以便腾出时间进行工作要快得多。
计算机代写|机器学习代写Machine Learning代考|Fallbacks and cold starts
让我们想象一下,我们刚刚为一家披萨公司构建了一个由ml驱动的解决方案,用于优化配送路线。前段时间,该公司找到我们,要求我们提供更便宜、更快、适应性更强的解决方案,以优化单个司机的送货路线。之前的方法是通过基于ArcGIS生成最优路线的路径算法来确定某个司机将把披萨送到哪个地址。虽然功能强大且功能齐全,但该业务需要考虑实际交付数据的时间性质和历史,以创建更有效的路线。
该团队研究了一种基于lstm的方法,该方法在过去三年的交付数据上进行了训练,创建了一个带有强化学习的对抗网络,该网络根据交付的及时性奖励了最佳路径。这个项目很快从一个科学项目发展成为在少数几个地区证明其价值的东西。比起他们之前的制作系统所能提供的暴力路径,它更擅长于选择传递序列。
在审查了测试市场中几个星期的路线数据后,该公司觉得可以为所有送货路线打开系统。一切看起来都很好。天气预报已经做好了,司机堵在路上的时间减少了,披萨的送餐速度比以往任何时候都要快。
大约过了一个星期,投诉才开始蜂拥而至。农村地区的顾客抱怨送货时间过长,费率高得吓人。在查看了这些投诉之后,我们开始发现这样一种模式:所有的投诉都发生在送货链的最后一站。没过多久,DS团队就意识到发生了什么。由于大多数训练数据都集中在城市中心,下车量和站点之间的距离较低意味着模型的目标是优化站点数。当这个外卖数量应用于农村环境时,所涉及的绝对距离意味着几乎所有的终点站外卖客户都会收到室温的披萨。
在没有对路线长度或估计总交付时间的回退控制的情况下,该模型将在总交付运行量的最小时间内优化路线,而不管总估计时间有多长。该解决方案缺乏备份计划。如果模型的输出违反了业务规则(不送冷披萨),它没有退路来使用现有的地理定位服务(农村路线的ArcGIS解决方案)。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。