如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!

计算机代写|机器学习代写Machine Learning代考|Generalization and frameworks: Avoid them until you can’t
The first thing that the team does is work on a product requirements document (PRD) that outlines what they want their unique framework to do. A general design, based on a builder pattern, is drafted. The architect wants the team to do the following:
1 Ensure that custom default values are utilized throughout the project code (not relying on API defaults)
2 Enforce overriding of certain elements of the modeling process with respect to tuning hyperparameters
3 Wrap the open source APIs with naming conventions and structural elements that are more in line with the code standards at the company
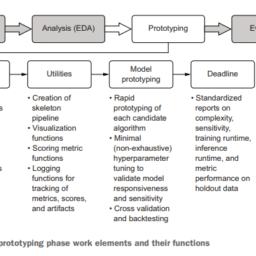
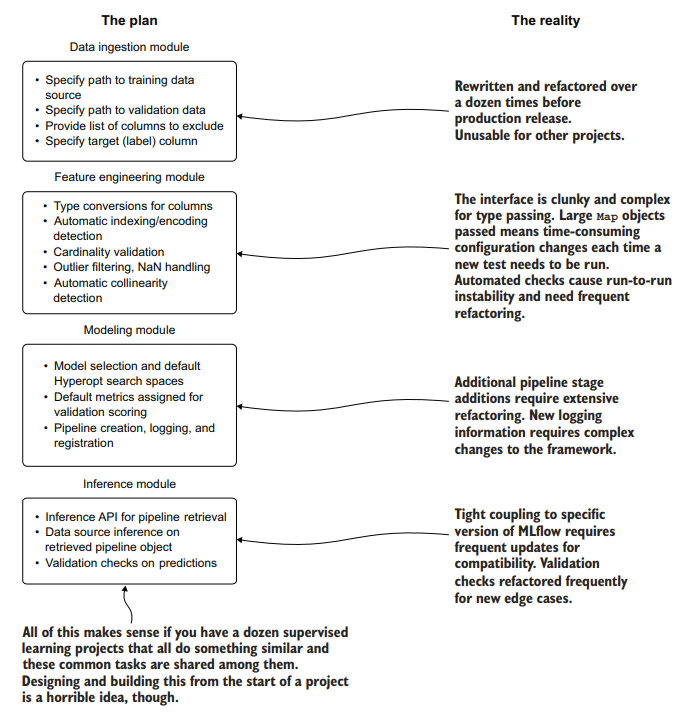
Before experimentation is done, a plan of features is developed, as shown in figure 13.9.
This plan for critical features is more than a little ambitious. Were this to proceed, the Reality aspects shown at the right side of the figure would likely play out (they’ve always happened whenever I’ve seen someone attempt to do this). Full of rework, refactoring, and redesign, this project would be doomed.
Instead of focusing on solving the problem by using existing frameworks (such as Spark, pandas, scikit-learn, NumPy, and R), the team would be supporting not only a project solution, but a custom implementation of a framework wrapper-and all of the pain that goes along with that. If you’re not staffed with dozens of software engineers to support a framework, it’s best to think carefully about planning to construct one.
Adding to the immense workload of building and maintaining such a software stack is the simple fact that you’d be attempting to support a wrapper that is more generic than the framework that it is wrapping. Engaging in work like this never ends well for two primary reasons:
You now own a framework-This means updates, compatibility guarantees, and a truly massive amount of testing to write (you are writing tests, right?). Functionality assurances are now in lockstep with the packages that you’re using to build the framework.
You now own a framework-Unless you’re planning on making it truly generic, open sourcing it and having a community of committers involved in its growth, and committing to maintaining it, it’s pointless work to engage in.
计算机代写|机器学习代写Machine Learning代考|Optimizing too early
Let’s suppose we work for a different company-one without that architect from the previous section, preferably. This company, instead of an empire-building architect, has an advisor to the DS team who comes from a backend engineering background. Throughout this person’s career, they’ve focused on SLAs that can be measured in milliseconds, algorithms that traverse collections in the most efficient way possible,and vast amounts of time eking out every available CPU cycle. Their world is entirely focused on the performance of discreet portions of code.
On the first project, the advisor wants to contribute to the DS team’s work by helping to build out a load tester. Since the team is yet again dealing with determining whether dogs are hungry when entering the local pet supply store, the advisor guides the team on implementing a solution.
Based on their experience and knowledge of Scala for backend systems, the team members end up focusing on something that is highly optimized for minimizing the memory pressure on the JVM. They want to eschew mutable buffer collections in favor of explicit collection building (using only the minimum amount of memory needed) with a fixed predetermined size of the collection. Because of prior experience, they spend a few days building the code in order to generate the data needed to test the throughput of the modeling solution for inference purposes.
To start, the advisor works on defining the data structure that is going to be used for testing. Listing 13.9 shows both the data structure and the defining static parameters to generate the data with.
机器学习代写
计算机代写|机器学习代写Machine Learning代考|Generalization and frameworks: Avoid them until you can’t
团队要做的第一件事是编写产品需求文档(PRD),该文档概述了他们希望自己的独特框架做什么。一个基于构建器模式的总体设计被起草。架构师希望团队做到以下几点:
确保在整个项目代码中使用自定义默认值(不依赖于API默认值)
在调优超参数方面,强制覆盖建模过程的某些元素
用更符合公司代码标准的命名约定和结构元素包装开源api
在实验完成之前,我们制定了一个特征计划,如图13.9所示。
这个关键特性的计划有点野心勃勃。如果这继续下去,图中右侧显示的现实方面可能会发挥作用(每当我看到有人试图这样做时,他们总是发生)。充满了返工、重构和重新设计,这个项目注定要失败。
团队将不再专注于通过使用现有框架(如Spark、pandas、scikit-learn、NumPy和R)来解决问题,而是不仅支持项目解决方案,还支持框架包装器的自定义实现——以及随之而来的所有痛苦。如果您没有大量的软件工程师来支持一个框架,那么最好仔细考虑构建一个框架的计划。
在构建和维护这样一个软件堆栈的巨大工作量之外,一个简单的事实是,您将试图支持一个比它所包装的框架更通用的包装器。从事这样的工作永远不会有好结果,主要有两个原因:
现在您拥有了一个框架——这意味着更新、兼容性保证和真正大量的测试要编写(您正在编写测试,对吧?)现在,功能保证与用于构建框架的包是同步的。
现在您拥有了一个框架——除非您计划使它真正通用,将其开源,并让一个提交者社区参与其发展,并承诺维护它,否则这是毫无意义的工作。
计算机代写|机器学习代写Machine Learning代考|Optimizing too early
假设我们在一家不同的公司工作——最好是一家没有上一节中的架构师的公司。这家公司没有一个帝国构建架构师,而是为DS团队提供了一个具有后端工程背景的顾问。在这个人的整个职业生涯中,他们关注的是可以以毫秒为单位测量的sla,以最有效的方式遍历集合的算法,以及在每个可用的CPU周期内花费大量时间。他们的世界完全集中在代码的离散部分的性能上。
在第一个项目中,顾问希望通过帮助构建负载测试器来为DS团队的工作做出贡献。由于团队在进入当地宠物用品商店时再次处理确定狗是否饥饿的问题,因此顾问指导团队实施解决方案。
基于他们对后端系统Scala的经验和知识,团队成员最终专注于一些高度优化的东西,以最大限度地减少JVM的内存压力。他们希望避免可变的缓冲区集合,而倾向于使用固定的预先确定的集合大小进行显式的集合构建(只使用所需的最小内存量)。由于以前的经验,他们花了几天的时间来构建代码,以便生成测试建模解决方案的吞吐量所需的数据,以进行推理。
首先,advisor将定义用于测试的数据结构。清单13.9显示了数据结构和用于生成数据的定义静态参数。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。