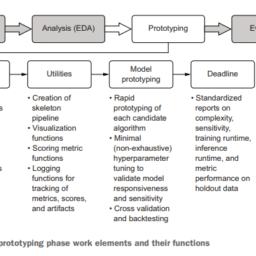
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
计算机代写|机器学习代写Machine Learning代考|Data consistency
Data issues can be one of the most frustrating aspects of production stability for a model. Whether due to flaky data collection, ETL changes between project development and deployment, or a general poor implementation of ETL, they typically bring a project’s production service to a grinding halt.
Ensuring data consistency (and regularly validating its quality) in every phase of the model life cycle is incredibly important for both the relevance of the implementation’s output and the stability of the solution over time. Consistency across phases of modeling is achieved by eliminating training and inference skew, utilizing feature stores, and openly sharing materialized feature data across an organization.
Training and inference skew
Let’s imagine that we’re working on a team that has been developing a solution by using a batch extract of features for consistency throughout model development. Throughout the development process, we were careful to utilize data that we knew was available in the serving system’s online data store. Because of the success of the project, the status quo was simply not left alone. The business wants more of what we’re bringing to the table.
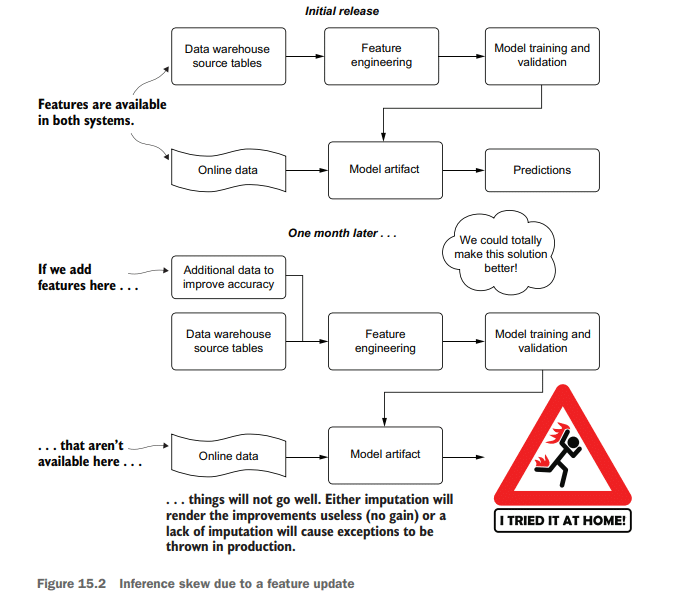
After a few weeks of work, we find that the addition of features from a new dataset that wasn’t included in the initial project development makes a large impact on the model’s predictive capabilities. We integrate these new features, retrain the model, and are left in the position shown in figure 15.2.
计算机代写|机器学习代写Machine Learning代考|A brief intro to feature stores
From a project’s development perspective, one of the more time-consuming aspects of crafting the ML code base is in feature creation. As data scientists, we spend a great amount of creative effort in manipulating the data being used in models to ensure that the correlations present are optimally leveraged to solve a problem. Historically, this computational processing is embedded within a project’s code base, in an inline execution chain that is acted upon during both training and prediction.
Having this tightly coupled association between the feature engineering code and the model-training and prediction code can lead to a great deal of frustrating troubleshooting, as we saw earlier in our scenario. This tight coupling can also result in complicated refactoring if data dependencies change, and duplicated effort if a calculated feature ever needs to be implemented in another project.
With the implementation of a feature store, however, these data consistency issues can be largely solved. With a single source of truth defined once, a registered feature calculation can be developed once, updated as part of a scheduled job, and available to be used by anyone in the organization (if they have sufficient access privileges, that is).
Consistency is not the only goal of these engineered systems. Synchronized data feeds to an online transaction processing (OLTP) storage layer (for real-time predictions) are another quality-of-life benefit that a feature store brings to minimizing the engineering burden of developing, maintaining, and synchronizing ETL needs for production ML. The basic design of a feature store capable of supporting online predictions consists of the following:
- An ACID-compliant storage layer:
- (A) Atomicity-Guaranteeing that transactions (writes, reads, updates) are handled as unit operations that either succeed (are committed) or fail (are rolled back) to ensure data consistency.
- $(C)$ Consistency-Transactions to the data store must leave the data in a valid state to prevent data corruption (from an invalid or illegal action to the system).
- (I) Isolation-Transactions are concurrent and always leave the storage system in a valid state as though operations were performed in sequence.
- (D) Durability-Valid executions to the state of the system will remain persistent at all times, even in the event of a hardware system failure or power loss, and are written to a persistent storage layer (written to disk, as opposed to volatile memory).
- A low-latency serving layer that is synchronized to the ACID storage layer (typically, volatile in-memory cache layers or in-memory database representations such as Redis).
- A denormalized representation data model for both a persistent storage layer and in-memory key-value store (primary-key access to retrieve relevant features).
- An immutable read-only access pattern for end users. The teams that own the generated data are the only ones with write authority.
机器学习代写
计算机代写|机器学习代写Machine Learning代考|Data consistency
数据问题可能是模型生产稳定性中最令人沮丧的方面之一。无论是由于零散的数据收集,项目开发和部署之间的ETL变更,还是ETL的一般糟糕实现,它们通常会使项目的生产服务陷入停顿。
在模型生命周期的每个阶段确保数据一致性(并定期验证其质量)对于实现输出的相关性和解决方案随时间的稳定性都是非常重要的。通过消除训练和推理偏差、利用特征存储以及在整个组织中公开共享物化特征数据,可以实现建模各阶段之间的一致性。
训练和推理倾斜
让我们想象一下,我们正在一个团队中工作,该团队一直在通过在整个模型开发过程中使用特征的批量提取来开发解决方案。在整个开发过程中,我们小心地利用我们知道在服务系统的在线数据存储中可用的数据。由于项目的成功,现状并没有被孤立。企业想要更多我们带来的东西。
经过几周的工作,我们发现从最初的项目开发中没有包含的新数据集中添加的特征对模型的预测能力产生了很大的影响。我们集成了这些新特征,重新训练了模型,并保留在图15.2所示的位置。
计算机代写|机器学习代写Machine Learning代考|A brief intro to feature stores
从项目开发的角度来看,制作ML代码库的一个更耗时的方面是创建特性。作为数据科学家,我们花了大量创造性的努力来操纵模型中使用的数据,以确保最佳地利用存在的相关性来解决问题。从历史上看,这种计算处理被嵌入到项目的代码库中,在内联执行链中,该执行链在训练和预测期间都起作用。
在特征工程代码与模型训练和预测代码之间拥有这种紧密耦合的关联可能导致大量令人沮丧的故障排除,正如我们在前面的场景中看到的那样。如果数据依赖关系发生变化,这种紧密耦合还会导致复杂的重构,如果计算出的特性需要在另一个项目中实现,则会导致重复的工作。
然而,通过功能存储的实现,这些数据一致性问题可以在很大程度上得到解决。使用一次定义的单一事实源,可以一次开发注册的特征计算,作为计划作业的一部分进行更新,并且可供组织中的任何人使用(如果他们具有足够的访问权限)。
一致性并不是这些工程系统的唯一目标。同步数据馈送到在线事务处理(OLTP)存储层(用于实时预测)是功能存储带来的另一个生活质量的好处,它可以最大限度地减少开发、维护和同步生产ML所需的ETL的工程负担。能够支持在线预测的功能存储的基本设计包括以下内容:
兼容acid的存储层:
(A)原子性——保证事务(写、读、更新)作为单元操作来处理,无论是成功(提交)还是失败(回滚),以确保数据一致性。
$(C)$ consistency—到数据存储的事务必须使数据保持有效状态,以防止数据损坏(由于对系统的无效或非法操作)。
(I)隔离——事务是并发的,并且总是使存储系统处于有效状态,就好像操作是按顺序执行的一样。
(D)持久性——对系统状态的有效执行将始终保持持久性,即使在硬件系统故障或断电的情况下也是如此,并被写入持久存储层(写入磁盘,而不是易失性存储器)。
与ACID存储层同步的低延迟服务层(通常是易失的内存缓存层或内存数据库表示,如Redis)。
用于持久存储层和内存中的键值存储(检索相关特性的主键访问)的非规范化表示数据模型。
用于最终用户的不可变只读访问模式。拥有生成数据的团队是唯一具有写入权限的团队。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。