如果你也在 怎样代写金融数学Financial mathematics under uncertainty这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。金融数学Financial mathematics under uncertainty将在某些付款和取决于个人死亡或其他不确定风险的付款方面应用利率、现值、现金流模型和利润测试的思想。
金融数学Financial mathematics under uncertainty金融学是利用概率论和数理统计、偏微分方程、随机过程、数学分析等数学工具进行数学建模和定量分析的方法,以寻找金融内部规律的新学科。这门学科自诞生以来,不断被金融学家吸收和使用。由于金融研究问题的不确定性,虽然金融数学是一门年轻的学科,但它注定要使随机分析作为一种主要工具得到广泛应用。然而,经过两次华尔街革命,金融数学得到了迅速发展。其核心内容是研究不确定随机环境下投资组合的最优选择理论和资产定价理论。套利、最优和均衡是基本的经济思想和金融数学的三个基本概念。
my-assignmentexpert™金融数学Financial mathematics under uncertainty作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的金融数学Financial mathematics under uncertainty作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此金融数学Financial mathematics under uncertainty作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在金融Financial作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的金融Financial代写服务。我们的专家在金融数学Financial mathematics under uncertainty代写方面经验极为丰富,各种金融数学Financial mathematics under uncertainty相关的作业也就用不着 说。
我们提供的金融数学Financial mathematics under uncertainty及其相关学科的代写,服务范围广, 其中包括但不限于:

金融代写|不确定性下的金融数学代写Financial mathematics under uncertainty代考|Trades and Quotes Data and Their Aggregation: From Point Processes to Discrete Time Series
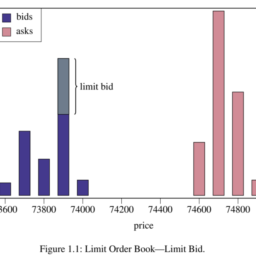
In its simplest form, the trading activities through an exchange that opens at 9:30 a.m. and closes at 4 p.m. can be described by a sequence of time stamps (“ticks”) $t_{0}<t_{1}<\cdots<t_{n}$ and the “marks” $y_{i}$ at time $t_{i}$, in which $t_{0}$ denotes $9: 30$ a.m. and after, and $t_{n}$ denotes the time of the last trade that occurs before or at 4 p.m. The marks $y_{i}$ can be price, volume of an order placed on either the buy or sell side of the book and in general can represent the characteristics of the order book at the time of $i$ th activity see Figure 2.1. The events with the marks associated with the ticks can be described mathematically as a marked point process. But our goal here is to first show how these data points can be aggregated over regularly spaced time intervals and how methods for linear homogeneous time series can be used to analyze the aggregated data. Some tools that are relevant for the analysis of point processes will be presented in Chapter 4 .
The typical Level III data for CISCO on a single day in 2011 is given below in Table 2.1. This outlay in Table $2.1$ points to various issues that need to be addressed in processing this type of data. The order numbers are only unique during the lifetime of the order but can be reassigned at a later time. Several activities such as submission, cancellation or modification of an order, all can take place at the same time stamp. Hidden orders are revealed only when they are executed and as such do not have visible order numbers. Full cancellation quantity and price information should be traced back to the submission time. To summarize, at any given point in time using the data described in Table $2.1$, the full limit order book that essentially records where each order is in the queue, can be constructed and thus providing the activity time and the associated marks. These and other characteristics of the limit order book superbook-if we collate this information from all exchanges will be taken up in a later chapter, but the focus here is on constructing discrete time series data from this point process data.
金融代写|不确定性下的金融数学代写Financial mathematics under uncertainty代考|Trading Decisions as Short-Term Forecast Decisions
Answers to these questions involve in some way predicting the market movement and in particular the future (short-term and long-term) price of assets. In the short term it is possible that prices have a tendency to ‘trend’ or exhibit ‘momentum’ but in the long run, prices have a tendency to ‘mean-revert’ as the information about the asset gets incorporated into the price.
Let $p_{i t}=\ln P_{i t}$ denote the price of the $i$ th asset at time $t$ and let $p_{t}=$ $\left(p_{1 t}, p_{2 t}, \ldots, p_{n t}\right)$ denote the price vector for ‘ $n$ ‘ assets. Let $y_{i t}$ denote a vector of characteristics, e.g., volume of transactions, price volatility, number of transactions and the intensity of trading as captured by the average duration between transactions, etc., of the $i$ th asset at time $t$. These quantities are aggregated from high frequency data of the type given in Table $2.1$ and illustrated in Figure $2.1$ to be used as the characteristics associated with the price changes. In addition, we can also consider $r$ factors $f_{t}=\left(f_{1 t}, f_{2 t}, \ldots, f_{r t}\right)$ that may include market and industry factors as well as asset characteristics such as market capitalization, book-to-market ratio, etc. The trading rules can be broadly grouped as follows:
(A) Statistical Arbitrage Rules: $\mathrm{E}\left(p_{i, t+1} \mid p_{i, t}, p_{i, t-1}, \ldots, y_{i, t}, y_{i, t-1}, \ldots\right)$
- Predicting the price of $i$ th stock at $\mathrm{t}+1$ based on the past trading information; this is sometimes labelled as time series momentum.
(B) Momentum: $\mathrm{E}\left(p_{t+1} \mid p_{t}, p_{t-1}, \ldots, y_{t}, y_{t-1}, \ldots\right)$ - Predicting the cross-sectional momentum of a subset of stocks based on their past trading characteristics. This is not only useful for portfolio formation and rebalancing, but also for pairs trading which is based on tracking two or more stocks simultaneously so that their price divergence can be exploited.
(C) Fair Value: $\mathrm{E}\left(p_{t+1} \mid p_{t}, p_{t-1}, \ldots, y_{t}, y_{t-1}, \ldots, f_{t}, f_{t-1}, \ldots\right)$ - Predicting the price using all relevant quantities. The factors normally include market and Fama-French factors. Many of these factors are at a more macro level than the time scale considered for the price prediction, but nevertheless could be useful, as explained in Chapter 3 .
金融代写|不确定性下的金融数学代写FINANCIAL MATHEMATICS UNDER UNCERTAINTY代考|Stochastic Processes: Some Properties
Formally, a discrete time series or stochastic process $Y_{1}, Y_{2}, \ldots, Y_{T}$ is a sequence of random variables (r.v.’s) possessing a joint probability distribution. A particular sequence of observations of the stochastic process $\left{Y_{t}, t=1, \ldots, T\right}$ is known as a realization of the process. In general, determining the properties and identifying the probability structure which generated the observed time series are of interest. We do not attempt to study the joint distribution of $Y_{1}, Y_{2}, \ldots, Y_{T}$ directly, as it is too complicated for large $T$, but we study the probabilistic mechanism which generates the process sequentially through time, and from this we want to derive the conditional distribution of future observations for purposes of prediction.
The means, variances, and covariances are useful summary descriptions of the stochastic process $\left{Y_{t}, t=1, \ldots, T\right}$, but it is not possible to estimate the unknown parameters means, variances, and covariances from a single realization of $T$ observations if these quantities vary with ‘ $t$ ‘. We impose some additional structure on the joint distribution of the process in order to substantially reduce the number of unknown parameters. The concept of stationarity of a process serves as a realistic assumption for many types of time series. Stationarity is motivated by the fact that for many time series in practice, segments of the series may behave similarly.
金融数学代写
金融代写|不确定性下的金融数学代写FINANCIAL MATHEMATICS UNDER UNCERTAINTY代考|TRADES AND QUOTES DATA AND THEIR AGGREGATION: FROM POINT PROCESSES TO DISCRETE TIME SERIES
在最简单的形式中,通过在上午 9:30 开放和下午 4 点关闭的交易所进行的交易活动可以用一系列时间戳来描述“吨一世Cķs” 吨0<吨1<⋯<吨n和“标记”是一世有时吨一世, 其中吨0表示9:30上午和之后,和吨n表示在下午 4 点之前或下午 4 点发生的最后一次交易的时间是一世可以是价格,订单的数量,无论是买入还是卖出,通常可以代表订单簿的特征一世活动见图 2.1。带有与刻度相关的标记的事件可以在数学上描述为标记点过程。但我们在这里的目标是首先展示如何在规则间隔的时间间隔内聚合这些数据点,以及如何使用线性齐次时间序列的方法来分析聚合数据。一些与点过程分析相关的工具将在第 4 章中介绍。
思科 2011 年单日典型 III 级数据见表 2.1。表中的这笔支出2.1指出在处理此类数据时需要解决的各种问题。订单号仅在订单的生命周期内是唯一的,但可以在以后重新分配。诸如提交、取消或修改订单之类的多项活动都可以同时进行。隐藏的订单仅在执行时才会显示,因此没有可见的订单号。完整的取消数量和价格信息应追溯到提交时间。总而言之,在任何给定时间点使用表中描述的数据2.1,可以构建完整的限价订单簿,该订单实质上记录了每个订单在队列中的位置,从而提供了活动时间和相关标记。限价订单簿超级簿的这些和其他特征——如果我们从所有交易所收集这些信息,将在后面的章节中讨论,但这里的重点是从这个点过程数据构建离散的时间序列数据。
金融代写|不确定性下的金融数学代写FINANCIAL MATHEMATICS UNDER UNCERTAINTY代考|TRADING DECISIONS AS SHORT-TERM FORECAST DECISIONS
这些问题的答案涉及以某种方式预测市场走势,尤其是未来sH这r吨−吨和r米一种ndl这nG−吨和r米资产价格。在短期内,价格可能倾向于“趋势”或表现出“动量”,但从长远来看,随着有关资产的信息被纳入价格,价格倾向于“均值回归”。
让p一世吨=ln磷一世吨表示价格一世时间的资产吨然后让p吨= (p1吨,p2吨,…,pn吨)表示 ‘ 的价格向量n’资产。让是一世吨表示特征向量,例如交易量、价格波动、交易数量和交易强度,由交易之间的平均持续时间等捕获。一世时间的资产吨. 这些数量是从表中给出的类型的高频数据中汇总而来的2.1并如图所示2.1用作与价格变化相关的特征。此外,我们还可以考虑r因素F吨=(F1吨,F2吨,…,Fr吨)这可能包括市场和行业因素以及资产特征,如市值、账面市值比等。交易规则可大致分为以下几类:
一种统计套利规则:和(p一世,吨+1∣p一世,吨,p一世,吨−1,…,是一世,吨,是一世,吨−1,…)
- 预测价格一世股票在吨+1基于过去的交易信息;这有时被称为时间序列动量。
乙势头:和(p吨+1∣p吨,p吨−1,…,是吨,是吨−1,…) - 根据过去的交易特征预测部分股票的横截面动量。这不仅对投资组合的形成和再平衡有用,而且对基于同时跟踪两只或多只股票的配对交易也很有用,以便可以利用它们的价格差异。
C公允价值:和(p吨+1∣p吨,p吨−1,…,是吨,是吨−1,…,F吨,F吨−1,…) - 使用所有相关数量预测价格。这些因素通常包括市场因素和 Fama-French 因素。其中许多因素比价格预测所考虑的时间尺度更宏观,但仍然可能有用,如第 3 章所述。
金融代写|不确定性下的金融数学代写FINANCIAL MATHEMATICS UNDER UNCERTAINTY代考|STOCHASTIC PROCESSES: SOME PROPERTIES
形式上,离散时间序列或随机过程是1,是2,…,是吨是一系列随机变量r.在.′s具有联合概率分布。随机过程的特定观察序列\left{Y_{t}, t=1, \ldots, T\right}\left{Y_{t}, t=1, \ldots, T\right}被称为过程的实现。一般来说,确定属性和识别生成观察到的时间序列的概率结构是有意义的。我们不尝试研究联合分布是1,是2,…,是吨直接,因为它对于大型吨,但是我们研究了随时间顺序生成过程的概率机制,并且我们希望从中推导出未来观测值的条件分布以进行预测。
均值、方差和协方差是对随机过程的有用总结描述\left{Y_{t}, t=1, \ldots, T\right}\left{Y_{t}, t=1, \ldots, T\right},但不可能从单个实现中估计未知参数的均值、方差和协方差吨如果这些数量随 ‘吨’。我们对过程的联合分布施加了一些额外的结构,以大大减少未知参数的数量。过程平稳性的概念是许多类型时间序列的现实假设。平稳性的动机是,对于实践中的许多时间序列,序列的片段可能表现相似。

金融代写|不确定性下的金融数学代写Financial mathematics under uncertainty代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。