如果你也在 怎样代写贝叶斯分析Bayesian Analysis 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。贝叶斯分析Bayesian Analysis一种统计推断方法(以英国数学家托马斯-贝叶斯命名),它允许人们将关于人口参数的先验信息与样本中包含的信息证据相结合,以指导统计推断过程。首先指定一个感兴趣的参数的先验概率分布。然后通过应用贝叶斯定理获得并结合证据,为参数提供一个后验概率分布。后验分布为有关该参数的统计推断提供了基础。
贝叶斯分析Bayesian Analysis自1763年以来,我们现在所知道的贝叶斯统计学并没有一个明确的运行。尽管贝叶斯的方法被拉普拉斯和当时其他领先的概率论者热情地接受,但在19世纪却陷入了不光彩的境地,因为他们还不知道如何正确处理先验概率。20世纪上半叶,一种完全不同的理论得到了发展,现在称为频繁主义统计学。但贝叶斯思想的火焰被少数思想家保持着,如意大利的布鲁诺-德-菲内蒂和英国的哈罗德-杰弗里斯。现代贝叶斯运动开始于20世纪下半叶,由美国的Jimmy Savage和英国的Dennis Lindley带头,但贝叶斯推断仍然极难实现,直到20世纪80年代末和90年代初,强大的计算机开始广泛使用,新的计算方法被开发出来。随后,人们对贝叶斯统计的兴趣大增,不仅导致了贝叶斯方法论的广泛研究,也导致了使用贝叶斯方法来解决天体物理学、天气预报、医疗保健政策和刑事司法等不同应用领域的迫切问题。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
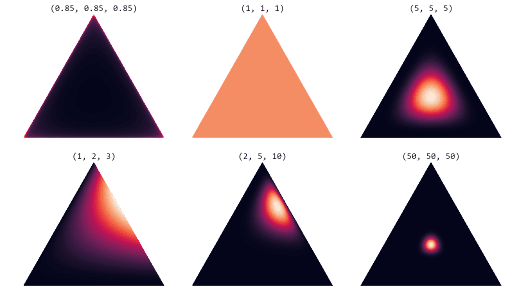
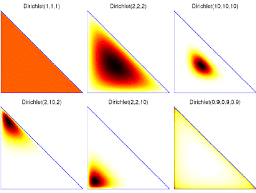
统计代写|贝叶斯分析代考Bayesian Analysis代写|THE DIRICHLET DISTRIBUTION RE-VISITED
The use of the logistic normal (additive and multiplicative) distribution is not as common as the use of the Dirichlet distribution (in Bayesian NLP). The main reason for this is that inference with the logistic normal is cumbersome, even with approximate inference such as the MCMC method or variational inference (which are discussed in Chapters 6 and 5). More than being cumbersome, this type of inference is also computationally intensive. Still, this does not preclude the use of the logistic normal distribution in both the MCMC setting (Mimno et al., 2008) or the variational setting (Blei and Lafferty, 2006).
A recent example of a use of the (additive) logistic normal distribution for text analysis is the correlated topic model (CTM) of Blei and Lafferty (2006). Blei and Lafferty present a model that is identical to the LDA model (see Section 2.2), only a logistic normal distribution is used to draw topic distribution for each topic, instead of the Dirichlet distribution, as in the LDA model.
The authors’ main motivation was to model correlation between topics. They assumed that given a large corpus of documents, the topics in the corpus are related to each other. For example, topics such as genetics and computational biology are both under the umbrella of biology, and when a document is about one, it is more likely to be about the other. On the other hand, astronomy is usually weakly related, if at all, to biology, and therefore we expect a correlation close to 0 , or even negative, between topics under the umbrella of astronomy and biology.
The authors compared the LDA and CTM on articles from the journal Science. Their findings were that the CTM achieved a better fit (when measured using average held-out loglikelihood; see Section 1.6 for more detail) than LDA. In addition, CTM’s probability peaked with $K=90$ (i.e., 90 topics), while LDA’s probability peaked with 30 topics. This implies that the CTM was able to make better use of available topics for the dataset used.
The additive logistic normal distribution was also used as a prior for structured problems, such as dependency grammar induction. Cohen et al. (2009) explore the use of the logistic normal distribution as a prior on the dependency model with valence (Klein and Manning, 2004), and demonstrate significant improvements in model estimation with this prior. Cohen et al. compared it with the use of the Dirichlet distribution and to not using a prior at all. The Dirichlet distribution behaved quite similarly to the case of not having a prior at all. The problem they modeled, as mentioned above, is that of dependency grammar induction, in which the prediction target is dependency trees (see Chapter 8) predicted from a sequence of part-ofspeech tags.
统计代写|贝叶斯分析代考Bayesian Analysis代写|The Partitioned Logistic Normal Distribution
The logistic normal distribution is a distribution over the probability simplex, which corresponds to a single multinomial. In NLP, the generative models used often consist of a family of multinomial distributions. In this case, the parameters $\theta$ consist of $K$ subvectors, $\theta^1, \ldots, \theta^K$, where each $\theta^k$ is in an $N_k$-dimensional vector in the probability simplex. See Chapter 8 for a more detailed explanation.
In these cases, the natural choice of a prior over the whole set of multinomials would be:
$$
p(\theta)=\prod_{k=1}^K p\left(\theta^k\right)
$$
Constants: $K, N_k$ for $k \in{1, \ldots, K}$ integers
Hyperprameters: $\eta \in \mathbb{R}^{\left(\sum_{k=1}^K N_k\right)-K}$ mean vector, $\Sigma$ the corresponding covariance matrix
Target random variables: $\theta^k$ vectors in the probability simplex of dimension $N_k-1$ for $k \in{1, \ldots, K}$
Auxiliary random variables: $\mu^k \in \mathbb{R}^{N_k-1}$ for $k \in{1, \ldots, K}$
- Generate a multivariate normal variable $\mu \in \mathbb{R}^{\sum_{i=1}^K N_k-K}$. The multivariate normal variable has mean $\eta$ and covariance matrix $\Sigma$ of size $\left(\sum_{i=1}^K N_k-K\right) \times\left(\sum_{i=1}^K N_k-\right.$ $K)$.
- Break $\mu$ into $K$ subvectors, each of length $N_k-1$.
- The random vector $\theta$ is set to:
$$
\begin{aligned}
\theta_i^k & =\frac{\exp \left(\mu_i^k\right)}{\prod_{j=1}^{N_k-1}\left(1+\exp \left(\mu_j^k\right)\right)} \forall i \in\left{1, \ldots, N_k-1\right} \
\theta_{N_k}^k & =\frac{1}{\prod_{j=1}^{N_k-1}\left(1+\exp \left(\mu_j^k\right)\right)}
\end{aligned}
$$
贝叶斯分析代写
统计代写|贝叶斯分析代考BAYESIAN ANALYSIS代写|THE DIRICHLET DISTRIBUTION RE-VISITED
物流法线的使用 additiveandmultiplicative分布不像狄利克雷分布那样普遍inBayesianNLP. 这样做的主要原因是逻辑正态的推理很麻烦,即 使是近似推理,如 MCMC 方法或变分推理whicharediscussedinChapters6and5. 这种类型的推理不仅麻烦,而且计算量大。尽管如此,这并不 排除在 MCMC 设置中使用逻辑正态分布 Mimnoetal., 2008或变分设置BleiandLafferty, 2006.
最近使用的一个例子additive用于文本分析的逻辑正态分布是相关主题模型 $C T M$ 布莱和拉弗蒂2006. Blei 和 Lafferty 提出了一个与LDA 模型相同 的模型seeSection 2.2,仅使用逻辑正态分布来绘制每个主题的主题分布,而不是像 LDA 模型中那样使用 Dirichlet 分布。
作者的主要动机是模拟主题之间的相关性。他们假设给定一个大型文档语料库,语料库中的主题彼此相关。例如,遗传学和计算生物学等主题都 属于生物学范畴,当一篇文档是关于一个的时候,它更有可能是关于另一个的。另一方面,天文学通常与生物学相关性很弱,如果有的话,因此 我们预计天文学和生物学主题之间的相关性接近于 0 ,甚至为负。
作者在《科学》杂志的文章中比较了 LDA 和 CTM。他们的发现是 CTM 实现了更好的拟合 whenmeasuredusingaverageheld – outloglikelihood; seeSection 1.6formoredetail比LDA。此外,CTM的概率达到峰值 $K=90$ i.e., 90topics,而 LDA 的概率在 30 个主题时达到峰值。这意味着 CTM 能够更好地利用所用数据集的可用主题。
加性逻辑正态分布也被用作结构化问题的先验,例如依存语法归纳。科恩等人。2009探索使用逻辑正态分布作为具有效价的依赖模型的先验 KleinandManning, 2004,并展示了使用此先验模型估计的显着改进。科恩等人。将其与 Dirichlet 分布的使用进行比较,并与根本不使用先验 进行比较。狄利克雷分布的表现与完全没有先验的情况非常相似。他们建模的问题,如上所述,是依赖语法归纳的问题,其中预测目标是依赖树 seeChapter 8 从词性标签序列预测。
统计代写|贝叶斯分析代考BAYESIAN ANALYSIS代写|THE PARTITIONED LOGISTIC NORMAL DISTRIBUTION
逻辑正态分布是概率单纯形的分布,对应于单个多项式。在 NLP中,使用的生成模型通常由一系列多项式分布组成。在这种情况下,参数 $\theta$ 包括 $K$ 子向量, $\theta^1, \ldots, \theta^K$ ,其中每个 $\theta^k$ 在一个 $N_k$ 概率单纯形中的维向量。更详细的解释见第 8 章。
在这些情况下,对整组多项式的先验的自然选择是:
$$
p(\theta)=\prod_{k=1}^K p\left(\theta^k\right)
$$
常量: $K, N_k$ 为了 $k \in 1, \ldots, K$ 整数
随机变量: $\theta^k$ 维度概率单纯形中的向量 $N_k-1$ 为了 $k \in 1, \ldots, K$
辅助随机变量: $\mu^k \in \mathbb{R}^{N_k-1}$ 为了 $k \in 1, \ldots, K$
- 休息 $\mu$ 进入 $K$ 子向量,每个长度 $N_k-1$.
- 随机向量 $\theta$ 被设定为:

统计代写|贝叶斯分析代考Bayesian Analysis代写 请认准exambang™. exambang™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。