如果你也在 怎样代写电路设计Intro to circuit design这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。电路设计Intro to circuit design一个简单的电路由电阻器、电容器、电感器、晶体管、二极管和集成电路组成。这些基本的电子元件是由导电线连接的。电流可以很容易地在这些导线之间流动,以便使电子元件处于工作状态。
电路设计Intro to circuit design过程从规格书开始,规格书说明了成品设计必须提供的功能,但没有指出如何实现这些功能。最初的规格书基本上是对客户希望成品电路实现的技术上的详细描述,可以包括各种电气要求,如电路将接收什么信号,必须输出什么信号,有什么电源,允许消耗多少功率。规格书还可以(通常也是如此)设定设计必须满足的一些物理参数,如尺寸、重量、防潮性、温度范围、热输出、振动容限和加速度容限等。
my-assignmentexpert™ 电路设计Intro to circuit design作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的电路设计Intro to circuit design作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此电路设计Intro to circuit design作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在电子工程Electrical Engineering作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的电子工程Electrical Engineering代写服务。我们的专家在电路设计Intro to circuit design代写方面经验极为丰富,各种电路设计Intro to circuit design相关的作业也就用不着 说。
我们提供的电路设计Intro to circuit design及其相关学科的代写,服务范围广, 其中包括但不限于:
电子工程代写|电路设计作业代写Intro to circuit design代考|Single-Stage Amplifier with Voltage Combiners
Three ANNs were trained for the VCOTA topology, i.e., ANN-1 to ANN-3. All ANNs were implemented in Python with Keras and TensorFlow [16] as backend. The code was run, on an Intel ${ }^{\circledR}$ Core $^{\mathrm{TM}} \mathrm{i} 7$ Quad CPU $2.6 \mathrm{GHz}$ with $8 \mathrm{~GB}$ of RAM. The structure considered has 15 input variables (obtained from the second-order polynomial feature extension of the 4 performance figures from Table $4.3$ ), 3 hidden layers with $120,240,60$ nodes each, and the output layer has 12 nodes.
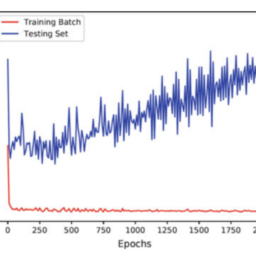
ANN-1 was trained on the original dataset, for 5000 epochs with batches of 512 samples. Its training took less than $15 \mathrm{~min}$. ANN-2 was trained on the dataset augmented 40 times (almost $700 \mathrm{~K}$ samples) for the same 5000 epochs. Its training took approximately $8 \mathrm{~h}$. ANN-3 was also trained on the same augmented dataset but only 500 epochs, and it was initialized with weights from ANN-1. Its training took less than an hour. Their performance after training on the training and validation sets is summarized in Table 4.4.
In terms of performance, ANN-2 and ANN-3 showed the best results. From Table 4.4, we can observe that MSE and MAE error for the training and validation sets were lower for these networks when compared to ANN-1, but not by a long margin. In terms of individual MAE for each device’s sizes, results were very similar across all ANNs, with a slight advantage for ANN-1. Table $4.5$ shows the MAE between the predicted and true devices’ sizes for each design variable of the designs in the test set.
Using the ANN for Circuit Sizing
电子工程代写|电路设计作业代写Intro to circuit design代考|Two-Stage Miller Amplifier
For the two-stage Miller amplifier, the same approach was followed. The structure considered also has 15 input variables, obtained from the second-order polynomial feature extension of the same 4 performance figures, 3 hidden layers with 120,240 , 60 nodes each, and the output layer has 15 nodes. Again, three ANNs were trained. ANN-4 was trained on the original dataset, for 5000 epochs with batches of 512 samples, taking approximately $12 \mathrm{~min}$ to conclude the training. ANN-5 was trained on the dataset augmented 20 times (more than $100 \mathrm{~K}$ samples) for 500 epochs. Its training took approximately $20 \mathrm{~min}$. The training set was comprised of $96 \%$ of total data, while the validation set of $4 \%$. ANN-6, was trained on the dataset augmented 20 times, for 500 epochs with batches of 512 samples, initialized with weights from ANN-4. The training set and the validation set were split with a $50 \%$ ratio (since the dataset was augmented, there is no problem in choosing the same percentage for both sets). Its training took approximately $20 \mathrm{~min}$. Their performance after training on the training and validation sets is summarized in Table 4.7.
In terms of performance, ANN-5 and ANN-6 showed the best results. From Table 4.7, we can observe that MSE and MAE for the training and validation sets were significantly lower for these networks, when compared to ANN-4. Table $4.8$ indicates the average MAE between all the predicted and true devices’ sizes from the test set. We can see that ANN-4 performed much worse than ANN-5 and ANN-6, yielding higher error than almost all design variables.
Using the ANN for Circuit Sizing
In Table 4.9, we see that ANN-5 and ANN-6 can generate stable designs, despite being inaccurate for some design variables. ANN-4 shows some limitations for one target but can generate designs similar to the other networks for the remaining targets.
电子工程代写|电路设计作业代写INTRO TO CIRCUIT DESIGN代考|TWO-STAGE MILLER AMPLIFIER
For the multicircuit classification and regression model, the two previously studied circuits were again considered. The goal of this architecture is not only to learn design patterns from these circuits, but also to identify which circuit should be considered to implement the target specifications. To do this, regression is applied to learn devices’ sizes and classification is used to learn circuit classes.
For this example, the used dataset, i.e., Dataset-3, has 15,000 different design points. Each third of the dataset belongs to three different chunks of data: two classes of circuits and one additional group of data. The first class refers to circuit specifications that belong to the VCOTA topology (encoded as 001 ); the second class refers to circuit specifications that belong to the two-stage Miller topology (encoded as 010); the additional group of data is comprised of augmented data built up from the other two circuits (encoded as 100 ), but designed to not meet any of the specifications required by those circuits (i.e., maximum and minimum performance specifications are outside the required ranges). This last chunk was added to the problem to check if the network would be misled by input specifications that are out of the ranges required for the two studied circuits. The circuit performances that were considered to train the ANN were again DC gain, IDD, GBW, and PM, and the ranges of values found in the dataset are given in Table 4.10.
ANN Structure and Training
Three ANNs were trained for this dataset, i.e., ANN-7 to ANN-9. The structure considered has 15 input variables (obtained from the second-order polynomial feature extension of the 4 performance figures from Table $4.10$ ), 3 hidden layers with 120 , 240,60 nodes each, and the output layer has 30 nodes, which represent the different devices’ sizes of the VCOTA and two-stage Miller topologies (12 and 15 nodes, respectively), and the class to which they belong to ( 3 nodes to encode each of the three classes). For this dataset, the augmented data does not have any devices’ sizes specified. Only performance figures were specified for this chunk of the dataset (as input features) so that a different class of circuits could be simulated.
ANN-7 was trained on the original dataset, for 5000 epochs with batches of 512 samples. Its training took less than $46 \mathrm{~min}$. ANN-8 was trained on the augmented dataset, where $75 \mathrm{~K}$ samples were generated for each circuit class, but only for 500 epochs. The network was initialized with weights from ANN-7. Its training took less than $50 \mathrm{~min}$. ANN-9 was trained on the augmented dataset, where $100 \mathrm{~K}$ samples were generated for each circuit class, for 5000 epochs. Its training took approximately $12 \mathrm{~h}$. Three performance metrics were used: the custom loss function from 3.8, MAE for the regression nodes, and SSCE for the classification nodes. Their performance after training on the training and validation sets is summarized in Table 4.11. Table $4.12$ indicates the average MAE between all the predicted and true devices’ sizes, and class prediction accuracy. In terms of performance, all three ANNs showed favorable results.
From Table 4.11, we can observe that loss, regression, and classification errors were similar for all three networks. The MAE for each individual device’s sizes was also very similar across all ANNs.
电路设计作业代写
电子工程代写|电路设计作业代写INTRO TO CIRCUIT DESIGN代考|SINGLE-STAGE AMPLIFIER WITH VOLTAGE COMBINERS
针对 VCOTA 拓扑结构训练了三个 ANN,即 ANN-1 到 ANN-3。所有的人工神经网络都是用 Python 和 Keras 和 TensorFlow 实现的16作为后端。代码在英特尔上运行®核吨米一世7四核 CPU2.6GH和和8 G乙内存。考虑的结构有 15 个输入变量这b吨一种一世n和dFr这米吨H和s和C这nd−这rd和rp这l是n这米一世一种lF和一种吨在r和和X吨和ns一世这n这F吨H和4p和rF这r米一种nC和F一世G在r和sFr这米吨一种bl和$4.3$, 3 个隐藏层120,240,60每个节点,输出层有 12 个节点。
ANN-1 在原始数据集上进行了训练,训练了 5000 个 epoch,批次为 512 个样本。它的训练时间不到15 米一世n. ANN-2 在增加了 40 次的数据集上进行了训练一种l米这s吨$700 ķ$s一种米pl和s对于相同的 5000 个 epoch。它的训练大约花了8 H. ANN-3 也在相同的增强数据集上进行了训练,但只有 500 个 epoch,并且使用来自 ANN-1 的权重进行初始化。它的训练用了不到一个小时。表 4.4 总结了他们在训练集和验证集上训练后的表现。
在性能方面,ANN-2 和 ANN-3 表现出最好的结果。从表 4.4 中,我们可以观察到,与 ANN-1 相比,这些网络的训练和验证集的 MSE 和 MAE 误差较低,但差距不大。就每个设备尺寸的单个 MAE 而言,所有 ANN 的结果非常相似,ANN-1 略有优势。桌子4.5显示了测试集中设计的每个设计变量的预测和真实设备尺寸之间的 MAE。
使用 ANN 进行电路规模调整
电子工程代写|电路设计作业代写INTRO TO CIRCUIT DESIGN代考|TWO-STAGE MILLER AMPLIFIER
对于两级米勒放大器,遵循相同的方法。所考虑的结构也有 15 个输入变量,从相同 4 个性能图的二阶多项式特征扩展获得,3 个隐藏层有 120,240 个,每个有 60 个节点,输出层有 15 个节点。再次训练了三个人工神经网络。ANN-4 在原始数据集上进行了训练,训练了 5000 个 epoch,每批 512 个样本,大约需要12 米一世n结束培训。ANN-5 在数据集上训练了 20 倍米这r和吨H一种n$100 ķ$s一种米pl和s500 个 epoch。它的训练大约花了20 米一世n. 训练集包括96%总数据,而验证集4%. ANN-6,在数据集上进行了 20 倍的训练,500 个 epoch,每批 512 个样本,使用 ANN-4 的权重进行初始化。训练集和验证集被分割成50%比率s一世nC和吨H和d一种吨一种s和吨在一种s一种在G米和n吨和d,吨H和r和一世sn这pr这bl和米一世nCH这这s一世nG吨H和s一种米和p和rC和n吨一种G和F这rb这吨Hs和吨s. 它的训练大约花了20 米一世n. 表 4.7 总结了他们在训练集和验证集上训练后的表现。
在性能方面,ANN-5 和 ANN-6 表现出最好的结果。从表 4.7 中,我们可以观察到,与 ANN-4 相比,这些网络的训练集和验证集的 MSE 和 MAE 显着降低。桌子4.8表示测试集中所有预测和真实设备大小之间的平均 MAE。我们可以看到 ANN-4 的性能比 ANN-5 和 ANN-6 差得多,产生的误差比几乎所有设计变量都高。
使用 ANN 进行电路尺寸调整
在表 4.9 中,我们看到 ANN-5 和 ANN-6 可以生成稳定的设计,尽管对于某些设计变量不准确。ANN-4 显示了对一个目标的一些限制,但可以为其余目标生成类似于其他网络的设计。
电子工程代写|电路设计作业代写INTRO TO CIRCUIT DESIGN代考|TWO-STAGE MILLER AMPLIFIER
对于多电路分类和回归模型,再次考虑了之前研究的两个电路。这种架构的目标不仅是从这些电路中学习设计模式,而且还要确定应该考虑使用哪个电路来实现目标规范。为此,应用回归来学习设备的大小,并使用分类来学习电路类别。
对于这个例子,使用的数据集,即 Dataset-3,有 15,000 个不同的设计点。数据集的每三分之一属于三个不同的数据块:两类电路和一组额外的数据。第一类是指属于VCOTA拓扑的电路规范和nC这d和d一种s001; 第二类是指属于两级米勒拓扑的电路规范和nC这d和d一种s010; 额外的数据组由其他两个电路构建的增强数据组成和nC这d和d一种s100,但设计不符合这些电路要求的任何规格一世.和.,米一种X一世米在米一种nd米一世n一世米在米p和rF这r米一种nC和sp和C一世F一世C一种吨一世这ns一种r和这在吨s一世d和吨H和r和q在一世r和dr一种nG和s. 最后一个块被添加到问题中,以检查网络是否会被超出两个研究电路所需范围的输入规范误导。用于训练 ANN 的电路性能同样是 DC 增益、IDD、GBW 和 PM,数据集中的值范围在表 4.10 中给出。
ANN 结构和训练
三个ANN 被训练用于这个数据集,即ANN-7 到ANN-9。考虑的结构有 15 个输入变量这b吨一种一世n和dFr这米吨H和s和C这nd−这rd和rp这l是n这米一世一种lF和一种吨在r和和X吨和ns一世这n这F吨H和4p和rF这r米一种nC和F一世G在r和sFr这米吨一种bl和$4.10$, 3 个隐藏层,每个隐藏层有 120 , 240,60 个节点,输出层有 30 个节点,代表 VCOTA 和两级米勒拓扑的不同设备大小12一种nd15n这d和s,r和sp和C吨一世在和l是,以及它们所属的类3n这d和s吨这和nC这d和和一种CH这F吨H和吨Hr和和Cl一种ss和s. 对于此数据集,增强数据没有指定任何设备的大小。只为这部分数据集指定了性能数据一种s一世np在吨F和一种吨在r和s以便可以模拟不同类别的电路。
ANN-7 在原始数据集上进行了训练,训练了 5000 个 epoch,批次为 512 个样本。它的训练时间不到46 米一世n. ANN-8 在增强数据集上进行了训练,其中75 ķ为每个电路类生成样本,但仅针对 500 个时期。网络使用来自 ANN-7 的权重进行初始化。它的训练时间不到50 米一世n. ANN-9 在增强数据集上进行了训练,其中100 ķ为每个电路类生成了 5000 个 epoch 的样本。它的训练大约花了12 H. 使用了三个性能指标:3.8 的自定义损失函数、回归节点的 MAE 和分类节点的 SSCE。表 4.11 总结了他们在训练集和验证集上训练后的表现。桌子4.12表示所有预测和真实设备大小之间的平均 MAE,以及类预测精度。在性能方面,所有三个人工神经网络都显示出良好的结果。
从表 4.11 中,我们可以观察到所有三个网络的损失、回归和分类错误都是相似的。每个单独设备大小的 MAE 在所有 ANN 中也非常相似。

电子工程代写|电路设计作业代写Intro to circuit design代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
电磁学代考
物理代考服务:
物理Physics考试代考、留学生物理online exam代考、电磁学代考、热力学代考、相对论代考、电动力学代考、电磁学代考、分析力学代考、澳洲物理代考、北美物理考试代考、美国留学生物理final exam代考、加拿大物理midterm代考、澳洲物理online exam代考、英国物理online quiz代考等。
光学代考
光学(Optics),是物理学的分支,主要是研究光的现象、性质与应用,包括光与物质之间的相互作用、光学仪器的制作。光学通常研究红外线、紫外线及可见光的物理行为。因为光是电磁波,其它形式的电磁辐射,例如X射线、微波、电磁辐射及无线电波等等也具有类似光的特性。
大多数常见的光学现象都可以用经典电动力学理论来说明。但是,通常这全套理论很难实际应用,必需先假定简单模型。几何光学的模型最为容易使用。
相对论代考
上至高压线,下至发电机,只要用到电的地方就有相对论效应存在!相对论是关于时空和引力的理论,主要由爱因斯坦创立,相对论的提出给物理学带来了革命性的变化,被誉为现代物理性最伟大的基础理论。
流体力学代考
流体力学是力学的一个分支。 主要研究在各种力的作用下流体本身的状态,以及流体和固体壁面、流体和流体之间、流体与其他运动形态之间的相互作用的力学分支。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。