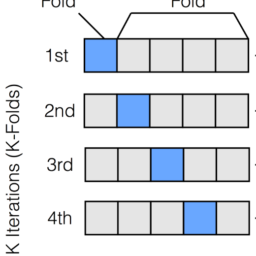
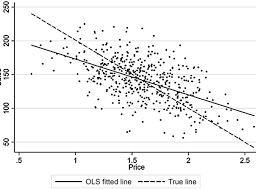
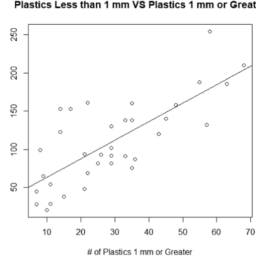
如果你也在 怎样代写统计Statistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。统计Statistics是数学的一个分支,涉及到矢量空间和线性映射。它包括对线、面和子空间的研究,也涉及所有向量空间的一般属性。
统计学Statistics是一门关于发展和研究收集、分析、解释和展示经验数据的方法的科学。统计Statistics是一个高度跨学科的领域;统计Statistics的研究几乎适用于所有的科学领域,各科学领域的研究问题促使新的统计方法和理论的发展。在开发方法和研究支撑这些方法的理论时,统计学家利用了各种数学和计算工具。
统计Statistics领域的两个基本概念是不确定性和突变。我们在科学(或更广泛的生活)中遇到的许多情况,其结果是不确定的。在某些情况下,不确定性是因为有关的结果尚未确定(例如,我们可能不知道明天是否会下雨),而在其他情况下,不确定性是因为虽然结果已经确定,但我们并不知道(例如,我们可能不知道我们是否通过了某项考试)。
my-assignmentexpert™ 统计Statistics作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的统计Statistics作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此统计Statistics作业代写的价格不固定。通常在经济学专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在统计Statistics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在统计Statistics代写方面经验极为丰富,各种统计Statistics相关的作业也就用不着 说。
我们提供的统计Statistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Date Analysis数据分析
- Actuarial Science 精算科学
- Bayesian Statistics 贝叶斯统计
- Generalized Linear Model 广义线性模型
- Macroeconomic statistics 宏观统计学
- Microeconomic statistics 微观统计学
- Logistic regression 逻辑回归
- linear regression 线性回归
统计作业代写STATISTICS代考|putative effect
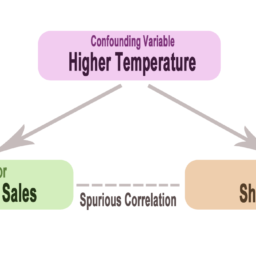
Involves causal inference: establishing that one variable produces or causes another. Causality is a challenging topic because, to ascertain its existence with observational (nonexperimental) data, we should consider all potential confounding variables that might explain why two variables are associated. Yet, few studies have the resources necessary to measure the myriad factors that might account for an association (remember Chapter 12’s discussion of omitted variable bias?). Nevertheless, statisticians have developed some promising tools that move us closer to the ability to make causal claims, even with observational data. Two related methods that are growing in popularity are called propensity score matching and weighting. These methods are simpler to understand if we imagine two groups: the treatment group that is exposed to the presumed cause and the control group that is not exposed to the presumed cause. In a true experiment, researchers may control who or what is and is not exposed to the cause and then observe
the putative effect. For example, an experimental vaccine designed to target the coronavirus is given to a randomly chosen sample of 100 people and a placebo to another randomly chosen sample of 100 people. Researchers then compare who does and does not experience COVID-19 symptoms during follow-up, which might be based on a regression model, a simple test of proportions, or some other statistical approach. Because of randomization of participants into the experimental and control groups, in all likelihood the systematic differences between the two groups are controlled or partialled out, so, if the treatment group does not experience symptoms (or they are greatly reduced), the vaccine is, with high probability, the cause of COVID-19 inhibition.
But in observational research projects-such as those represented by the datasets used in the previous chapters-researchers rarely have this level of control over the assignment of the presumed cause, so they must take a different approach and attempt to account for differences between groups in the sample. In an LRM, analysts statistically adjust for differences by including potential confounding variables, which might account for all differences across individuals and allow them to isolate the “cause” of some outcome. However, a more likely scenario is that important variables are left out of the model because they are not available in the dataset or perhaps the conceptual model guiding the research is not developed enough. Using LRMs to make causal inferences also requires other stringent assumptions. { }^{5} Of course, all of this assumes that there is a single “cause” of an outcome and the goal is to identify it. This is often a fair assumption in the medical sciences or program evaluation when one wishes to know whether, say, marijuana vaping causes mouth cancer or a school nutrition program triggers more vegetable consumption. But when studying social and behavioral phenomena many outcomes are multi-causal or may involve complex interactions and nonlinear associations that require a highly developed conceptual model to identify. Thus, the focus on identifying single cause-and-effect relationships is often myopic. Rather than using LRMs in an attempt to identify a single causal factor, it might be preferable in many instances to be guided by a conceptual model that proposes that multiple factors affect an outcome. { }^{6}
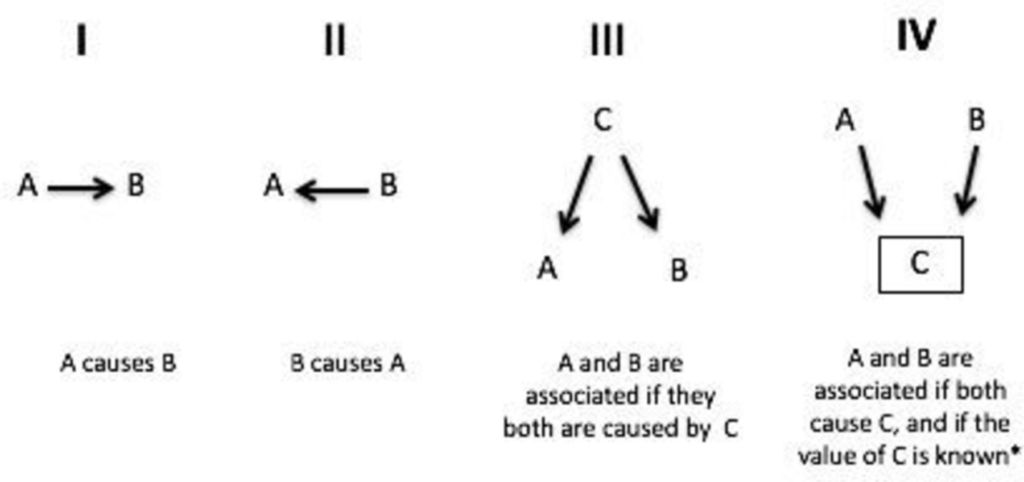
统计作业代写STATISTICS代考|PUTATIVE EFFECT
涉及因果推理:确定一个变量产生或导致另一个变量。因果关系是一个具有挑战性的话题,因为为了通过观察(非实验)数据确定其存在,我们应该考虑所有可能解释为什么两个变量相关的潜在混杂变量。然而,很少有研究拥有必要的资源来衡量可能导致关联的无数因素(还记得第 12 章对遗漏变量偏差的讨论吗?)。尽管如此,统计学家已经开发了一些有前途的工具,使我们更接近做出因果断言的能力,即使是观察数据也是如此。两种越来越流行的相关方法称为倾向得分匹配和加权。如果我们设想两个组,这些方法更容易理解:暴露于假定原因的治疗组和未暴露于假定原因的对照组。在一个真实的实验中,研究人员可以控制谁或什么是和不暴露于原因,然后观察
推定的效果。例如,一种针对冠状病毒的实验性疫苗被给予随机选择的 100 人样本,而安慰剂被给予另一个随机选择的 100 人样本。然后,研究人员比较谁在随访期间出现和未出现 COVID-19 症状,这可能基于回归模型、简单的比例检验或其他一些统计方法。由于将参与者随机分为实验组和对照组,两组之间的系统差异很可能得到控制或部分排除,因此,如果治疗组没有出现症状(或症状大大减轻),疫苗是,很有可能是 COVID-19 抑制的原因。
但在观察性研究项目中——例如前几章中使用的数据集所代表的项目——研究人员很少对假定原因的分配有这种程度的控制,因此他们必须采取不同的方法并尝试解释不同群体之间的差异。样本。在 LRM 中,分析师通过包括潜在的混杂变量对差异进行统计调整,这可能解释个体之间的所有差异,并允许他们隔离某些结果的“原因”。然而,更可能的情况是模型中忽略了重要变量,因为它们在数据集中不可用,或者指导研究的概念模型可能不够发达。使用 LRM 进行因果推断还需要其他严格的假设。5当然,所有这些都假设结果有一个单一的“原因”,目标是识别它。这通常是医学科学或项目评估中的一个公平假设,当人们想知道大麻是否会导致口腔癌或学校营养计划是否会引发更多的蔬菜消费时。但是在研究社会和行为现象时,许多结果是多因果的,或者可能涉及复杂的相互作用和非线性关联,需要高度发达的概念模型来识别。因此,对识别单一因果关系的关注往往是短视的。与其使用 LRM 来尝试识别单个因果因素,不如在许多情况下由提出多个因素影响结果的概念模型指导可能更可取。
统计作业代写Statistics代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
matlab代写
MATLAB是一个编程和数值计算平台,被数百万工程师和科学家用来分析数据、开发算法和创建模型。
MATLAB is a programming and numeric computing platform used by millions of engineers and scientists to analyze data, develop algorithms, and create models.
统计代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
统计作业代写
生活中,统计学无处不在。它遍布世界的每一个角落,应用于每一个领域。不管是普通人的生活,还是最高精尖的领域,它都不曾缺席。
自从人类发明统计学这一学科以来,原本复杂多样、无法预测的数据,变成了可预测的、直观的正态分布。
我们的确不可能精准的预测到每一个数据的变化,但是我们可以精准的预测到大部分数据的变化。当然,那些散落在中心之外的数据我们无法把握,可尽管如此,我们也拥有了接近神的能力,打破了神与人的壁垒,这就是统计学的魅力。
同时,它又作为众多学生的噩梦学科,在学科难度榜上居高不下 。大量的统计公式、概念和题目导致了ohysics作业繁杂又麻烦。现在有我们UprivateTA™机构为您提供优质statistics assignment代写服务,帮您解决作业难题!
my-assignmentexpert™这边统计代写的质量怎么样?保不保分?靠不靠谱? 一般能写到多少分?
各国各学校的学术标准都有所差异,即使是统计作业,给分也存在一定的主观性因素,有时Teacher和TA的改分并不能够做到完全公正,所有的作业分数都存在一定的运气成分,TA对于步骤把控的严格程度可能和给分的TA今天的心情以及他的性格正相关。一般情况下,MY-ASSIGNMENTEXPERT™出品的作业平均正确率在93%以上。
我在MY-ASSIGNMENTEXPERT™这里购买了代写服务,然后最后这门课的成绩挂了怎么办?
若是因为各种因素结合导致在此购买的统计作业的成绩未达到事先指定的标准,MY-ASSIGNMENTEXPERT™承诺免费重写/修改,并且无条件退款。
最快什么时候写完? 很急的任务可以做吗?
最急的统计论文,可在24小时以内完成,加急的论文价格会比普通的订单稍贵,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计quiz和统计exam代考,在写手档期ok的情况下,可以在下单之后一小时之内进行,不过不提倡这样临时找人,因为加急的quiz和exam代考价格会比普通的订单贵更重要的是可能找不到人,因此建议各位提前预定,不要拖到deadline临近再下订单。
最急的统计assignment,在写手档期ok的情况下,可以在下单之后三小时之内完成,价格在一般的assignment基础上收一个加急费用,如果一份assignment发下来不确定自己能不能完成也能提前和我们联系,报价是不收取任何费用的,如果后续有需要,也方便我们安排写手档期。