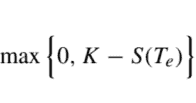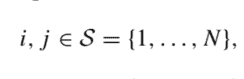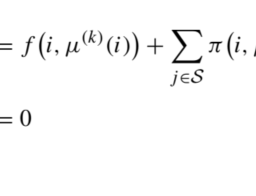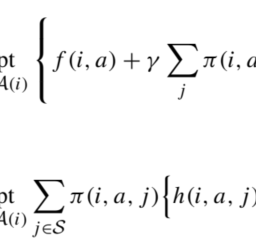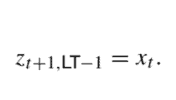如果你也在为遇到的matlab相关的难题发愁,请随时右上角联系我们的24/7代写客服。MATLAB®将为迭代分析和设计过程而调整的桌面环境与直接表达矩阵和阵列数学的编程语言相结合。它包括用于创建脚本的实时编辑器,这些脚本将代码、输出和格式化文本结合在可执行的笔记本中。
- 专业构建
MATLAB工具箱是专业开发的,经过严格的测试,并有完整的文件记录。 - 拥有互动式应用程序
MATLAB应用程序让您看到不同的算法是如何与您的数据一起工作的。迭代直到您得到您想要的结果,然后自动生成一个MATLAB程序来重现或自动完成您的工作。 - 以及扩展的能力
只需稍加修改代码,就可以将您的分析扩展到集群、GPU和云上运行。不需要重写你的代码或学习大数据编程和内存外技术。
my-assignmentexpert™ matlab作业代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。my-assignmentexpert™, 最高质量的matlab作业代写作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于统计Statistics作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此matlab作业代写作业代写的价格不固定。通常在matlab专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
my-assignmentexpert™ 为您的留学生涯保驾护航 在matlab作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的应用数学applied math代写服务。我们的专家在matlab作业代写方面经验极为丰富,各种matlab作业代写相关的作业也就用不着 说。
我们提供的matlab作业代写及其相关学科的代写,服务范围广, 其中包括但不限于:
- 数据分析
- 数值与符号计算
- 工程与科学绘图
- 控制系统设计
- 航天工业
- 汽车工业
- 生物医学工程
- 语音处理
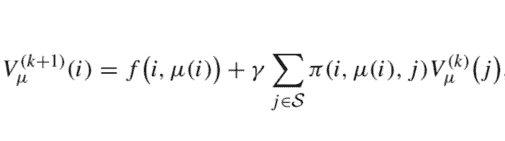
运筹学代写
数学代写|matlab作业代写|optimistic policy iteration
At first sight, value and policy iteration look like wildly different beasts. Value iteration relies on a possibly large number of computationally cheap iterations; policy iteration, on the contrary, relies on a (hopefully) small number of possibly expensive iterations. Convergence may only be obtained in the limit for value iteration, whereas finite convergence is obtained for policy iteration.
However, it is possible to bridge the gap between the two approaches. To see how, imagine that we evaluate a stationary policy $\mu$ by fixed-point iteration of operator $\mathcal{T}{\mu}:$ $$ V{\mu}^{(k+1)}(i)=f(i, \mu(i))+\gamma \sum_{j \in \mathcal{S}} \pi(i, \mu(i), j) V_{\mu}^{(k)}(j), \quad i \in \mathcal{S}
$$
In practice, this may be needed because the application of Gaussian elimination to solve a large-scale system of linear equations is not feasible. By a similar token, in model-free reinforcement learning we will have to learn the value function of a stationary policy by an iterative process too, based on Monte Carlo sampling or online experimentation. ${ }^{10}$ Before improving the policy by rollout, we should wait for convergence of the above scheme. Now, imagine that we stop prematurely the iterations in Eq. (4.10), optimistically assuming that we have correctly evaluated the current stationary policy $\mu$. After a sufficient number of iterations, we stop and use the current values as an estimate. Hence, we set $\widehat{V}{\mu}(i)=V{\mu}^{(k+1)}(i), i \in \mathcal{S}$ and apply rollout to find an improved policy:
$$
\tilde{\mu}(i) \in \underset{a \in \mathcal{A}(i)}{\arg o p t}\left{f(i, a)+\gamma \sum_{j} \pi(i, a, j) \widehat{V}_{\mu}(j)\right}, \quad i \in \mathcal{S} .
$$
数学代写|MATLAB作业代写|generalized policy iteration
This kind of approach is called optimistic policy iteration and leads to methods broadly labeled under the umbrella of generalized policy iteration. Depending on how we are optimistic about our ability to assess the value of the policy, we may iterate Eq. (4.10) for a large or small number of steps. In other words, we apply the operator $\mathcal{T}{\mu}$ a few times, before applying operator $\mathcal{T}$. Note that this may be cheaper than optimizing, when the number of actions for each state is large (more so, in the case of continuous action spaces). On the contrary, in value iteration we always keep changing the policy, which is implicit in the updated value function: $$ V^{(k+1)}(i)=\underset{a \in \mathcal{A}(i)}{\operatorname{opt}} \sum{j \in \mathcal{S}} \pi(i, a, j)\left{h(i, a, j)+\gamma V^{(k)}(j)\right}, \quad i \in \mathcal{S}
$$
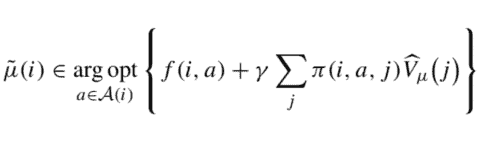
matlab代写
数学代写|MATLAB作业代写|OPTIMISTIC POLICY ITERATION
乍一看,价值和政策迭代看起来就像是截然不同的野兽。价值迭代依赖于可能大量计算成本低的迭代;相反,策略迭代依赖于H○p和F你一世一世和少量可能昂贵的迭代。值迭代只能在极限中获得收敛,而策略迭代只能获得有限收敛。
但是,有可能弥合这两种方法之间的差距。看看如何,假设我们评估一个固定策略μ通过运算符 $\mathcal{T} {\mu}的定点迭代:$V {\亩} ^ {到+1}一世=f一世,μ(一世)+\gamma \sum_{j \in \mathcal{S}} \pi一世,μ(一世, j) V_{\mu}^{到}j, \quad i \in \mathcal{S}
$$
在实践中,这可能是需要的,因为应用高斯消元法求解大规模线性方程组是不可行的。类似地,在无模型强化学习中,我们也必须通过基于蒙特卡罗采样或在线实验的迭代过程来学习固定策略的价值函数。10在通过 rollout 改进策略之前,我们应该等待上述方案的收敛。现在,假设我们提前停止了方程式中的迭代。4.10, 乐观地假设我们已经正确评估了当前的平稳策略μ. 在足够数量的迭代之后,我们停止并使用当前值作为估计。因此,我们设
$\mu$. After a sufficient number of iterations, we stop and use the current values as an estimate. Hence, we set $\widehat{V}{\mu}(i)=V{\mu}^{(k+1)}(i), i \in \mathcal{S}$ and apply rollout to find an improved policy:
$$
\tilde{\mu}(i) \in \underset{a \in \mathcal{A}(i)}{\arg o p t}\left{f(i, a)+\gamma \sum_{j} \pi(i, a, j) \widehat{V}_{\mu}(j)\right}, \quad i \in \mathcal{S} .
$$
数学代写|MATLAB作业代写|GENERALIZED POLICY ITERATION
这种方法称为乐观策略迭代,并导致在广义策略迭代的保护伞下被广泛标记的方法。根据我们对评估政策价值的能力的乐观程度,我们可以迭代方程。4.10对于大量或少量的步骤。换句话说,我们应用运算符
$\mathcal{T}{\mu}$ a few times, before applying operator $\mathcal{T}$. Note that this may be cheaper than optimizing, when the number of actions for each state is large (more so, in the case of continuous action spaces). On the contrary, in value iteration we always keep changing the policy, which is implicit in the updated value function: $$ V^{(k+1)}(i)=\underset{a \in \mathcal{A}(i)}{\operatorname{opt}} \sum{j \in \mathcal{S}} \pi(i, a, j)\left{h(i, a, j)+\gamma V^{(k)}(j)\right}, \quad i \in \mathcal{S} .
$$

统计代考
统计是汉语中的“统计”原有合计或汇总计算的意思。 英语中的“统计”(Statistics)一词来源于拉丁语status,是指各种现象的状态或状况。
数论代考
数论(number theory ),是纯粹数学的分支之一,主要研究整数的性质。 整数可以是方程式的解(丢番图方程)。 有些解析函数(像黎曼ζ函数)中包括了一些整数、质数的性质,透过这些函数也可以了解一些数论的问题。 透过数论也可以建立实数和有理数之间的关系,并且用有理数来逼近实数(丢番图逼近)
数值分析代考
数值分析NumericalAnalysis,又名“计算方法”,是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科。 它以数字计算机求解数学问题的理论和方法为研究对象,为计算数学的主体部分。
随机过程代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其取值随着偶然因素的影响而改变。 例如,某商店在从时间t0到时间tK这段时间内接待顾客的人数,就是依赖于时间t的一组随机变量,即随机过程
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。