如果你也在 怎样代写机器学习Machine Learning COMP5318这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。
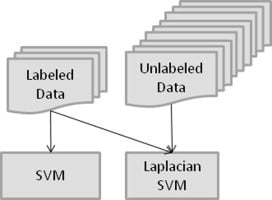
计算机代写|机器学习代写Machine Learning代考|Semi-Supervised SVM
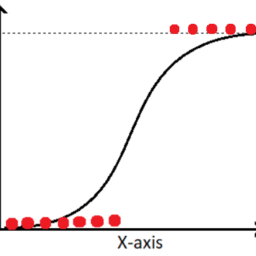
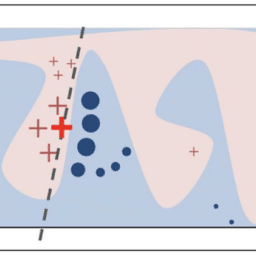
Semi-Supervised Support Vector Machine (S3VM) is the extension of SVM for semi-supervised learning. Compared to the standard SVM, which aims to find the separating hyperplane with the maximum margin, S3VM aims to find a separating hyperplane that not only separates the labeled samples but also lies in a low-density region of all samples. As illustrated in $\square$ Figure 13.3, the assumption here is low-density separation, which is an extension of the clustering assumption under linear separating hyperplanes.
A well-known S3VM is Transductive Support Vector Machine(TSVM) (Joachims 1999), which is designed for binary classification problems. TSVM considers all possible label
计算机代写|机器学习代写Machine Learning代考|Disagreement-Based Methods
Unlike the previously introduced methods that utilize unlabeled samples via a single learner, disagreement-based methods train multiple learners and the disagreement between learners is crucial for the exploitation of unlabeled data.
Co-training (Blum and Mitchell 1998) is a representative disagreement-based method. Since it was originally designed for multi-view data, it is also a representative method for multiview learning. Before introducing co-training, let us first take a look at the multi-view data.
In many real-world applications, a data object can have multiple attribute sets, where each attribute set provides a view of the data object. For example, a movie can have different attribute sets such as the attribute set about the visual images, the attribute set about the audio, the attribute set about the subtitles, and the attribute set about the online reviews. For ease of discussion, we consider only the visual and audio attribute sets. Then, a movie clip can be represented as a sample $\left(\left\langle\boldsymbol{x}^1, \boldsymbol{x}^2\right\rangle, y\right)$, where $\boldsymbol{x}^i$ is the feature vector of the sample in view $i$. Let $\boldsymbol{x}^1$ denote the feature vector in the visual view, and $\boldsymbol{x}^2$ denote the feature vector in the audio view. Let $y$ denote the label, indicating the genre of movies, such as action and romance. Then, data in the form of $\left(\left\langle\boldsymbol{x}^1, \boldsymbol{x}^2\right\rangle, y\right)$ is called multi-view data.
Suppose that different views are compatible, that is, they share the same output space $\mathcal{Y}$. Let $\mathcal{Y}^1$ denote the label space for visual information, and $\mathcal{Y}^2$ denote the label space for audio information. Then, we have $\mathcal{Y}=\mathcal{y}^1=\mathcal{Y}^2$. For example, both label spaces must be {action, romance} rather than $\mathcal{Y}^1=$ action, romance $}$ and $\mathcal{Y}^2={$ literary, horror $}$. Under the above assumption, there are many benefits of explicitly considering multiple views. For example, it is hard to tell the genre of a movie when we only see two people looking at each other visually. However, it is likely to be a romance movie if we also hear the phrase “I love you” from the audio. On the other hand, if both the visual and the audio information suggest action, then putting them together, it is very likely to be an action movie. Under the assumption of compatibility, the above example shows that the complementarity between different views is useful for constructing learners.
机器学习代写
计算机代写|机器学习代写 MACHINE LEARNING代考|SEMISUPERVISED SVM
半监督支持向量机 $S 3 V M$ 是 sVm对半监督学习的扩展。与标准 SVM 見在找到具有最大边距的分离超平面相比,S3VM 見在找到一个分离超平面,该分离超平面不仅 可以分离标记的样本,而且还位于所有样本的低密度区域。如图所示 $口$ 图 13.3,这里的假设是低密度分离,它是线性分离超平面下的袟类假设的扩展。
一个著名的 S3VM 是 Transductive Support Vector MachineTSVM Joachims1999,它是为二分类问题而设计的。TSVM 考虑所有可能的标签
计算机代写|机器学习代写MACHINE LEARNING代考|DISAGREEMENT-BASED METHODS
与之前介绍的通过单个学习器利用末标记样本的方法不同,其于分歧的方法训练多个学习器,学习器之间的分歧对于利用末标记数据至关重要。
联合培训BlumandMitchell1998是一种代表性的基于分歧的方法。由于它最初是为多视图数据设计的,因此它也是多视图学习的代表方法。在介绍协同训练之 前,让我们先看一下多视图数据。
在许多实际应用中,一个数据对象可以有多个属性集,其中每个属性集提供数据对象的一个视图。例如,一部电影可以有不同的属性集,例如关于视觉图像的属性 集、关于音频的属性集、关于字幕的属性集以及关于在线评论的属性集。为了便于讨论,我们只考虑视觉和音频属性集。然后,一个影片剪辑可以表示为一个样本 $\left(\left\langle\boldsymbol{x}^1, \boldsymbol{x}^2\right\rangle, y\right)$ ,在哪里 $\boldsymbol{x}^i$ 是视图中样本的特征向量 $i$. 让 $\boldsymbol{x}^1$ 表示视觉视图中的特征向量,以及 $\boldsymbol{x}^2$ 表示音频视图中的特征向量。让 $y$ 表示标签,表示电影的类型,例 如动作片和嗳情片。然后,数据形式为 $\left(\left\langle x^1, x^2\right\rangle, y\right)$ 称为多视图数据。
假设不同的视图是兼容的,即它们共享相同的输出空间 $\mathcal{Y}$. 让 $\mathcal{Y}^1$ 表示视觉信息的标签空间,和 $\mathcal{Y}^2$ 表示音频信息的标签空间。那么,我们有 $\mathcal{Y}=y^1=\mathcal{Y}^2$. 例如,两 个标签空间都必须是 {action, romance} 而不是 $\mathcal{Y}^1=$ 动作,亜情 $}$ 和 $\mathcal{Y}^2=$ \$literary, horror\$. 在上述假设下,明确考慮多个视图有很多好处。例如,当我们只看到 两个人在视觉上看着对方时,很难分辩电影的类型。但是,如果我们还从音频中听到“我喛你”这句话,它很可能是一部喏情电影。另一方面,如果视觉和音频信息 都暗示动作,那么将它们放在一起,它很可能是一部动作片。在兼容性的假设下,上面的例子表明不同视图之间的互补性对于构建学习器是有用的。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。