如果你也在 怎样代写机器学习Machine Learning COMP5318这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。
机器学习代考_Machine Learning代考_Task and Reward
Planting watermelon involves many steps, such as seed selection, regular watering, fertilization, weeding, and insect control. We usually do not know the quality of the watermelons until harvesting. If we consider the harvesting of ripe watermelons as a reward for planting watermelons, then we do not receive the final reward immediately after each step of planting, e.g., fertilization. We do not even know the exact impact of the current action on the final reward. Instead, we only receive feedback about the current status, e.g., the watermelon seedling looks healthier. After planting watermelons many times and exploring different planting methods, we may finally come up with a good strategy for planting watermelons. Such a process, when abstracted, is called reinforcement learning.
As illustrated in – Figure 16.1, we usually use Markov Decision Process (MDP) to describe reinforcement learning problems: an agent is in an environment $E$ with a state space $X$, where each state $x \in X$ is a description of the environment perceived by the agent, e.g., the growing trend of the watermelon seedling in watermelon planting. The actions that the agent can perform form an action space $A$. For example, in watermelon planting, the actions include watering, using different types of fertilizers, and applying different types of pesticides. When an action $a \in A$ is performed on the current state $x$, the underlying transition function $P$ will transit the environment from the current state to another with a certain probability, e.g., watering a dehydrated seedling may or may not recover it to a healthy state. After the transition from one state to another, the environment sends the agent a reward based on the underlying reward function $R$, e.g., $+1$ for healthy seedling, $-10$ for withered seedling, and $+100$ for harvesting a ripe watermelon. In short, reinforcement learning involves a quadruplet $E=\langle X, A, P, R\rangle$, where $P: X \times A \times X \mapsto \mathbb{R}$ gives the state transition probability, and $R: X \times A \times X \mapsto \mathbb{R}$ gives the reward. In some applications, the reward function may only depend on state transitions, that is, $R: X \times X \mapsto \mathbb{R}$.
机器学习代考_Machine Learning代考_Exploration Versus Exploitation
Unlike common supervised learning, the final amount of rewards in reinforcement learning is only observed after multiple actions. Let us start our discussion with the simplest case: we maximize the reward of each step, that is, consider only one step at a time. Note that reinforcement learning and supervised learning are still quite different even in this simplified scenario since the agent needs to try out different actions to collect the respective outcomes. In other words, there is no training data that tells the agent which actions to take.
To maximize the one-step reward, we need to consider two aspects: find the reward corresponding to each action and take the highest-rewarded action. If the reward of each action is a definite value, then we can find the highest-rewarded action by trying out all actions. In practice, however, the reward of action is usually a random variable sampled from a probabil- ity distribution, and hence we cannot accurately determine the mean reward only in one trial.
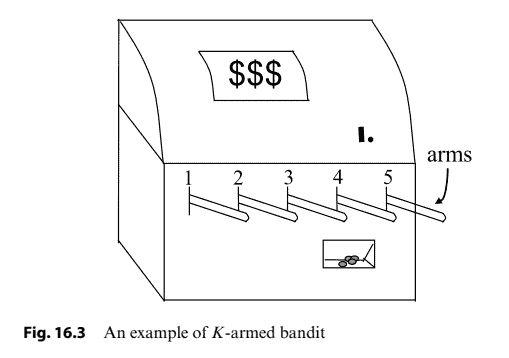
The above one-step reinforcement learning scenario corresponds to a theoretical model called $K$-armed bandit. As illustrated in $-$ Figure 16.3, there are $K$ arms in the $\mathrm{K}$-armed bandit. After inserting a coin, the player can pull an arm, and the machine will return some coins at a certain probability (of this arm) that is unknown to the player. The player’s objective is to develop a policy that maximizes the cumulative reward, that is, more coins.
If we only want to know the expected reward of each arm, then we can employ the exploration-only method: equally allocate the pulling opportunities to the arms (i.e., pull each arm in turn), and then calculate the average number of coins returned by each arm as the approximation of expectation. In contrast, if we only want to take the highest-rewarded action, then we can employ the exploitation-only method: pull the currently best arm (i.e., the one with the highest average reward), or randomly choose one when there are multiple best arms. By comparing these two methods, we see that the exploration-only method can estimate the reward of each arm reasonably well at the cost of losing many opportunities to pull the optimal arm, whereas the exploitation-only method is likely to miss the optimal arm since it does not have a good estimation of the expected reward of each arm. Therefore, we are unlikely to maximize the cumulative rewards using either method.

机器学习代写
机器学习代考_MACHINE LEARNING代考_TASK AND REWARD
种植西瓜涉及许多步氷,例如选种、定期浇水、施肥、除草和防虫。我们通常在收获前不知道西瓜的质量。如果我们将收获成孰西瓜视为种植西瓜的奖励,那么我 们不会在种植的每一步之后立即获得最终奖励,例如施肥。我们甚至不知道当前行动对最终奖励的确切影响。相反,我们只收到有关当前状态的反帻,例如,西瓜 苗看起来更健康。在多次种植西瓜,探索不同的种植方法后,我们可能最終会想出一个种植西瓜的好策略。这样的过程,当被抽象出来时,被称为强化学习。
如图 16.1 所示,我们通常使用马尔可夫决策过程 $M D P$ 描述强化学习问题:代理在环境中 $E$ 有状态空间 $X$, 其中每个状态 $x \in X$ 是agent感知的环境描述,例如西瓜 种植中西瓜幼苗的生长趋势。代理可以执行的动作形成一个动作空间 $A$. 例如,在西瓜种植中,动作包括浇水、使用不同类型的肥料和施用不同类型的农药。当一 个动作 $a \in A$ 在当前状态上执行 $x$, 底层转换函数 $P$ 将以一定的概率将环境从当前状态转移到另一个状态,例如,给脱水的幼苗浇水可能会或可能不会将其恢复到健 康状态。从一种状态转换到另一种状态后,环境根据底层奖励函数向代理发送奖励 $R$ ,例如, $+1$ 为了健康的幼苗, $-10$ 对于枯䒧的幼苗,和 $+100$ 收获一个成孰的 西瓜。简而言之,强化学习涉及四组 $E=\langle X, A, P, R\rangle$ , 在哪里 $P: X \times A \times X \mapsto \mathbb{R}$ 给出状态转移概率,并且 $R: X \times A \times X \mapsto \mathbb{R}$ 给予奖励。在某些应用 中,奖励函数可能只依赖于状态转换,即 $R: X \times X \mapsto \mathbb{R}$.
机器学习代考_MACHINE LEARNING代考_EXPLORATION VERSUS EXPLOITATION
与常见的监督学习不同,强化学习中的最终奖励量仅在多次操作后才能观察到。让我们从最简单的情况开始讨论:我们最大化每一步的奖励,即一次只考虞一个步 骤。请注意,即使在这个简化的场景中,强化学习和监督学习仍然有很大不同,因为代理需要尝试不同的动作来收集各目的结果。换句话说,没有训练数据告诉代 理要采取哪些行动。
为了最大化一步奖励,我们需要考虑两个方面:找到每个动莋对应的奖励,并采取最高奖励的动作。如果每个动作的奖励是一个确定的值,那么我们可以通过尝试 所有动作来找到最高奖励的动作。然而,在实践中,行动的奖励通常是从概率分布中抽样的随机变量,因此我们不能石在一次试验中淮确地确定平均奖励。
上述一步强化学习场景对应一个理论模型,称为 $K$-武装匪徒。如图所示-图16.3,有 $K$ 武器在 $\mathrm{K}$-武装罪徒。投币后,玩家可以拉动一只手臂,机器会以一定的概率 返还一些硬币ofthisarm这是玩家不知道的。玩家的目标是制定一个最大化累积奖励的策略,即更多的硬币。
如果我们只想知道每条手臂的预期回报,那么我们可以采用仅探索的方法: 将拉动机会平均分配给手臂i.e, pulleacharminturn,然后计算每个辞返回的硬币的 平均数量作为期望的近似值。相反,如果我们只想采取最高回报的行动,那么我们可以采用仅利用的方法:拉当前最好的手臂
i.e., theonewiththehighestaveragereward,或者当有多个最佳唷时随机选择一个。通过比较这两种方法,我们看到仅探索方法可以合理地估计每个辞的奖
励,但代价是失去许多拉动最佳鹃的机会,而仅开发方法可能会错过最佳臂,因为它对每个手臂的预期奖励没有很好的估计。因此,我们不太可能使用任何一种方 法来最大化累积奖励。

机器学习代考_Machine Learning代考_ 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。