如果你也在 怎样代写机器学习Machine Learning COMP5318这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。
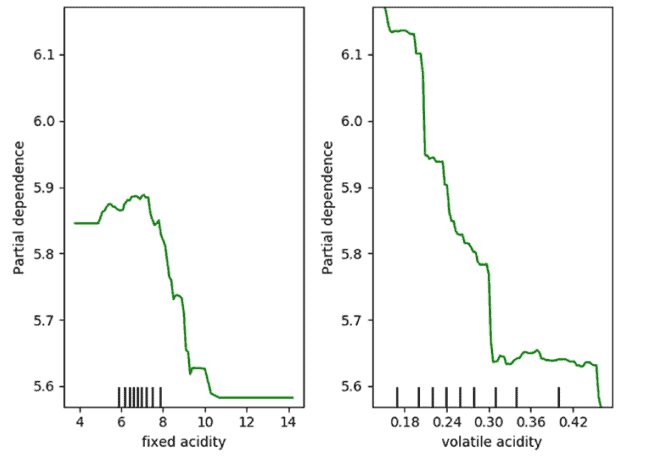
机器学习代考_Machine Learning代考_Partial Dependence Plots (PDP)
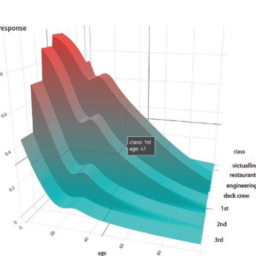
The partial dependence plot (short PDP or PD plot) shows the marginal effect one or two features have on the predicted outcome of a machine learning model $(\mathrm{J}$. H. Friedman 2001). A partial dependence plot can show whether the relationship between the target and a feature is linear, monotonic, or more complex. For example, partial dependence plots always show a linear relationship when applied to a linear regression model.
The partial dependence function for regression is defined as follows.
$$
\hat{f}{x_S}\left(x_S\right)=E{x_C}\left[\hat{f}\left(x_S, x_C\right)\right]=\int \hat{f}\left(x_S, x_C\right) d \mathbb{P}\left(x_C\right)
$$
The $x_S$ are the features for which the partial dependence function should be plotted, and $x_C$ are the other features used in the machine learning model $f$. Usually, there are only one or two features in the set $\mathrm{S}$. The feature(s) in $S$ are those we want to know the effect on the prediction. The feature vectors $x_S$ and $x_C$ combined make up the total feature space $x$. Partial dependence works by marginalizing the machine learning model output over the distribution of the features in set $C$. The function shows the relationship between the features in set $S$ we are interested in and the predicted outcome.
Marginalizing over the other features gets a function that depends only on features in $S$, interactions with other features included.
The partial function $f x S$ is estimated by calculating averages in the training data, also known as the Monte Carlo method.
$$
\hat{f}{x_S}\left(x_S\right)=\frac{1}{n} \sum{i=1}^n \hat{f}\left(x_S, x_C^{(i)}\right)
$$
机器学习代考_Machine Learning代考_Individual Conditional Expectation
Individual conditional expectation (ICE) plots display one line per instance that shows how the instance’s prediction changes when a feature changes.
The partial dependence plot for the average effect of a feature is a global method because it does not focus on specific instances but an overall average. The equivalent to a PDP for individual data instances is an ICE plot. An ICE plot visualizes the dependence of the prediction on a feature for each instance separately, resulting in one line per instance, compared to one line overall in partial dependence plots. A PDP is the average of the lines of an ICE plot.
The values for a line (and one instance) can be computed by keeping all other features the same, creating variants of this instance by replacing the feature’s value with values from a grid, and making predictions with the black-box model for these newly created instances.
The result is a set of points with the feature value from the grid and the respective predictions. What is the point of looking at individual expectations instead of partial dependencies? Partial dependence plots can obscure a heterogeneous relationship created by interactions. PDPs can show you what the average relationship between a feature and the prediction looks like. This only works well if the interactions between the features for which the PDP is calculated and the other features are weak. In interactions, the ICE plot provides much more insight.
机器学习代写
机器学习代考_MACHINE LEARNING代考_PARTIAL DEPENDENCE PLOTS $P D P$
部分依赖图 shortPDPor PDplot显示一个或两个特征对机器学习模型的预测结果的边际效应 $(\mathrm{J}$. H. 弗里德曼 2001) 。部分依赖图可以显示目标和特征之间的关系 是线性的、单调的还是更复杂的。例如,部分相关图在应用于线性回归模型时始终显示线性关系。
回归的偏相关函数定义如下。
$$
\hat{f} x_S\left(x_S\right)=E x_C\left[\hat{f}\left(x_S, x_C\right)\right]=\int \hat{f}\left(x_S, x_C\right) d \mathbb{P}\left(x_C\right)
$$
这 $x_S$ 是应该绘制部分依赖函数的特征,并且 $x_C$ 是机器学习模型中使用的其他特征 $f$. 通常,集合中只有一个或两个特征S. 特点 $s$ 在 $S$ 是我们想知道对预测的影响的那 些。特征向量 $x_S$ 和 $x_C$ 组合起来构成总的特征空间 $x$. 部分依赖通过将机器学习模型输出边㭬化到集合中的特征分布来起作用 $C$. 该函数显示集合中特征之间的关系 $S$ 我们感兴趣的是预期的结果。
边氺化其他特征得到一个仅依赖于特征的函数 $S$ ,包括与其他功能的交互。
偏函数 $f x S$ 通过计算川训练数据中的平均值来估计,也称为蒙特卡罗方法。
$$
\hat{f} x_S\left(x_S\right)=\frac{1}{n} \sum i=1^n \hat{f}\left(x_S, x_C^{(i)}\right)
$$
机器学习代考_MACHINE LEARNING代考_INDIVIDUAL CONDITIONAL EXPECTATION
个体条件期望 $I C E$ 绘图为每个实例显示一行,显示实例的预测在特征发生变化时如何变化。
特征平均效果的部分依赖图是一种全局方法,因为它不关注特定实例,而是关注整体平均值。与单个数据实例的 PDP等效的是 ICE 图。ICE图分别可视化预测对每 个实例的特征的依赖性,与部分依赖图中的整体一条线相比,每个实例一条线。PDP是 ICE 图线的平均值。
一行的值andoneinstance 可以通过保持所有其他特征相同,通过用网格中的值替换特征值来创建该实例的变体,并使用黑盒模型为这些新创建的实例进行预测来 计算。
结果是一组具有来自网格的特征值和相应预测的点。育看个人期望而不是部分依赖的意义何在? 部分依赖图可以掩盖由交互创建的异构关系。PDP可以向您展示特 征与预测之间的平均关系。这仅在计算 PDP 的特征与其他特征之间的交互较弱时才有效。在交互中,ICE图提供了更多的洞察力。

机器学习代考_Machine Learning代考_ 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。